a2c_is_a_special_case_of_ppo
 a2c_is_a_special_case_of_ppo copied to clipboard
a2c_is_a_special_case_of_ppo copied to clipboard
Instability when training
Hi,
Thank you for the great research.
I am working on implementing the findings from this paper in a different setting using TRLX. Unfortunately, when matching hyperparameters for A2C with PPO I seem to be experiencing instability with training and I am not able to match the results.
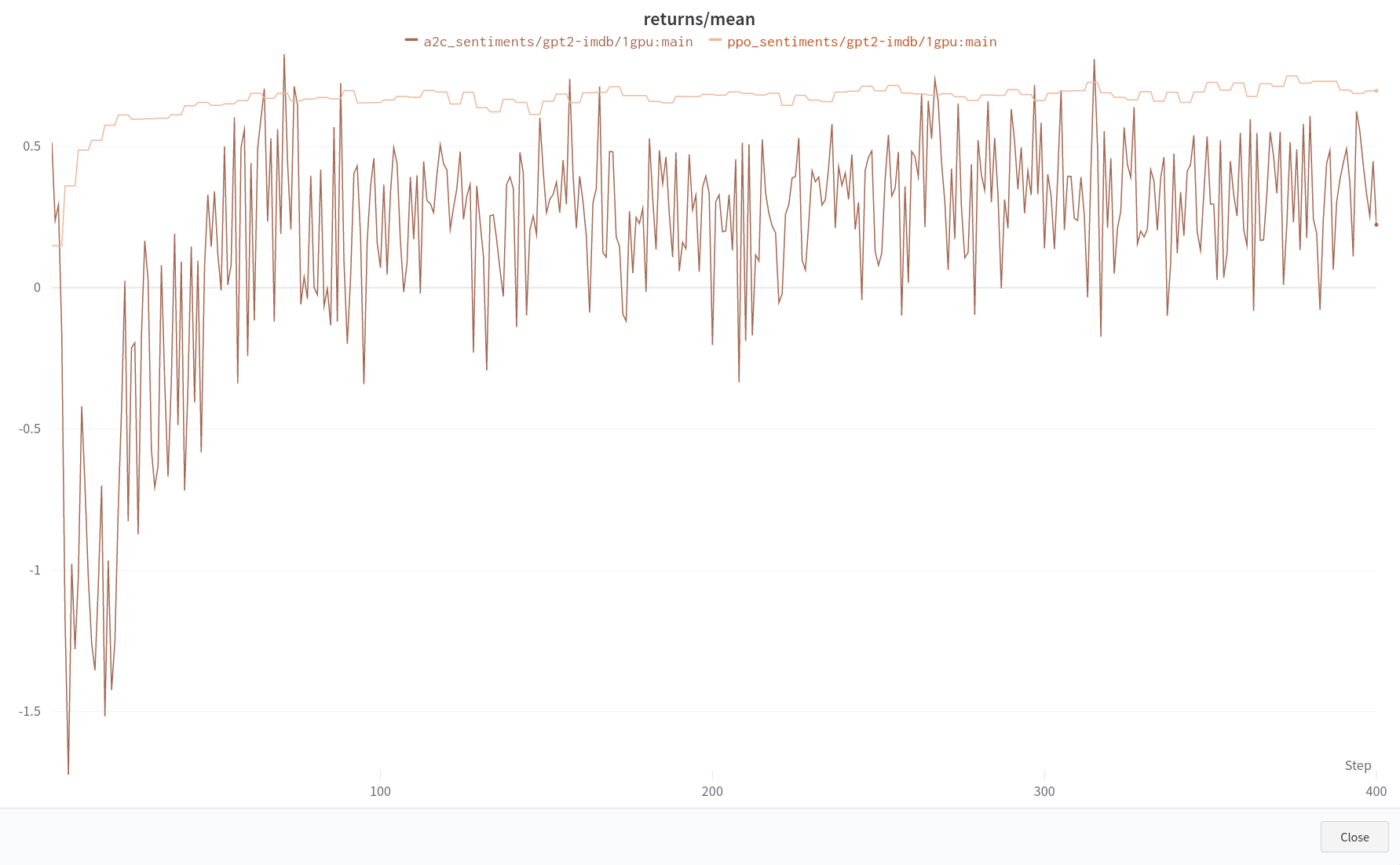
Hyperparameters for trying to match A2C training:
train:
seq_length: 1024
epochs: 400
total_steps: 10000
batch_size: 5
checkpoint_interval: 10000
eval_interval: 100
pipeline: "PromptPipeline"
orchestrator: "PPOOrchestrator" # A2C is a special case of PPO (https://arxiv.org/pdf/2205.09123.pdf)
trainer: "AcceleratePPOTrainer"
model:
model_path: "lvwerra/gpt2-imdb"
num_layers_unfrozen: 2
tokenizer:
tokenizer_path: "gpt2"
truncation_side: "right"
optimizer:
name: "rmsprop"
kwargs:
lr: 7.0e-4
alpha: 0.99
eps: 1.0e-5
weight_decay: 0
scheduler:
name: "linear" # Ensure that the learning rate is constant
kwargs:
start_factor: 1
total_iters: 0
method:
name: "ppoconfig"
num_rollouts: 5
chunk_size: 5
ppo_epochs: 1
init_kl_coef: 0.05
target: 6
horizon: 10000
gamma: 1
lam: 1
cliprange: 0.2
cliprange_value: .inf
vf_coef: 1
scale_reward: False
ref_mean: null
ref_std: null
cliprange_reward: 10
gen_kwargs:
max_new_tokens: 40
top_k: 0
top_p: 1.0
do_sample: True
Hyperparameters for original PPO training:
train:
seq_length: 1024
epochs: 100
total_steps: 10000
batch_size: 128
checkpoint_interval: 10000
eval_interval: 100
pipeline: "PromptPipeline"
orchestrator: "PPOOrchestrator"
trainer: "AcceleratePPOTrainer"
model:
model_path: "lvwerra/gpt2-imdb"
num_layers_unfrozen: 2
tokenizer:
tokenizer_path: "gpt2"
truncation_side: "right"
optimizer:
name: "adamw"
kwargs:
lr: 1.0e-4
betas: [0.9, 0.95]
eps: 1.0e-8
weight_decay: 1.0e-6
scheduler:
name: "cosine_annealing"
kwargs:
T_max: 10000 # train.total_steps
eta_min: 1.0e-4
method:
name: "ppoconfig"
num_rollouts: 128
chunk_size: 128
ppo_epochs: 4
init_kl_coef: 0.05
target: 6
horizon: 10000
gamma: 1
lam: 0.95
cliprange: 0.2
cliprange_value: 0.2
vf_coef: 1
scale_reward: False
ref_mean: null
ref_std: null
cliprange_reward: 10
gen_kwargs:
max_new_tokens: 40
top_k: 0
top_p: 1.0
do_sample: True
Any help would be greatly appreciated.
Thank you,
Enrico
Hi @conceptofmind, I think this is expected. While A2C is a special case of PPO, we expect A2C to perform differently compared to PPO.
A2C usually would have a more unstable policy update and can often get stuck in low rewards settings (see https://arxiv.org/pdf/2205.07015.pdf for more quantitative analysis).
@vwxyzjn Thank you for the response.
I will review the paper which you provided.
Do you have any advice on improving the stability of policy updates while still maintaining that A2C is a special case of PPO? Additionally, can the batchsize vary as long as the number of rollouts remains at 5?
Best,
Enrico
Hi Enrico, A2C is just a set of hyper-parameters for PPO. How to make the policy updates more stable remains an open question. I think you can try things like making the clip coefficient smaller (only applicable when num_epochs > 1)
The batch_size equals num_steps * num_envs. In the case of A2C, if you increase num_rollouts(i.e., num_steps) then the batch_size will become larger.
Hi @vwxyzjn,
Hi Enrico, A2C is just a set of hyper-parameters for PPO. How to make the policy updates more stable remains an open question. I think you can try things like making the clip coefficient smaller (only applicable when num_epochs > 1)
I am going to try a few different things such as l2-norm gradient clipping which DeepMind uses in its Sparrow paper and see if I can get more stable results for the A2C configuration.
The
batch_sizeequalsnum_steps * num_envs. In the case of A2C, if you increasenum_rollouts(i.e.,num_steps) then thebatch_sizewill become larger.
Ok, so increasing the num_rollouts, batch_size, and chunk_size hyperparameters will still maintain your findings? I wanted to confirm that these hyperparameters did not need to be set at 5 and could be scaled appropriately. I have been trying to match different configurations from above to further verify training stability and results. Increasing batch_size clearly makes a significant difference in training. I have kept all of the hyperparameters the same except for increasing num_rollouts to 128:
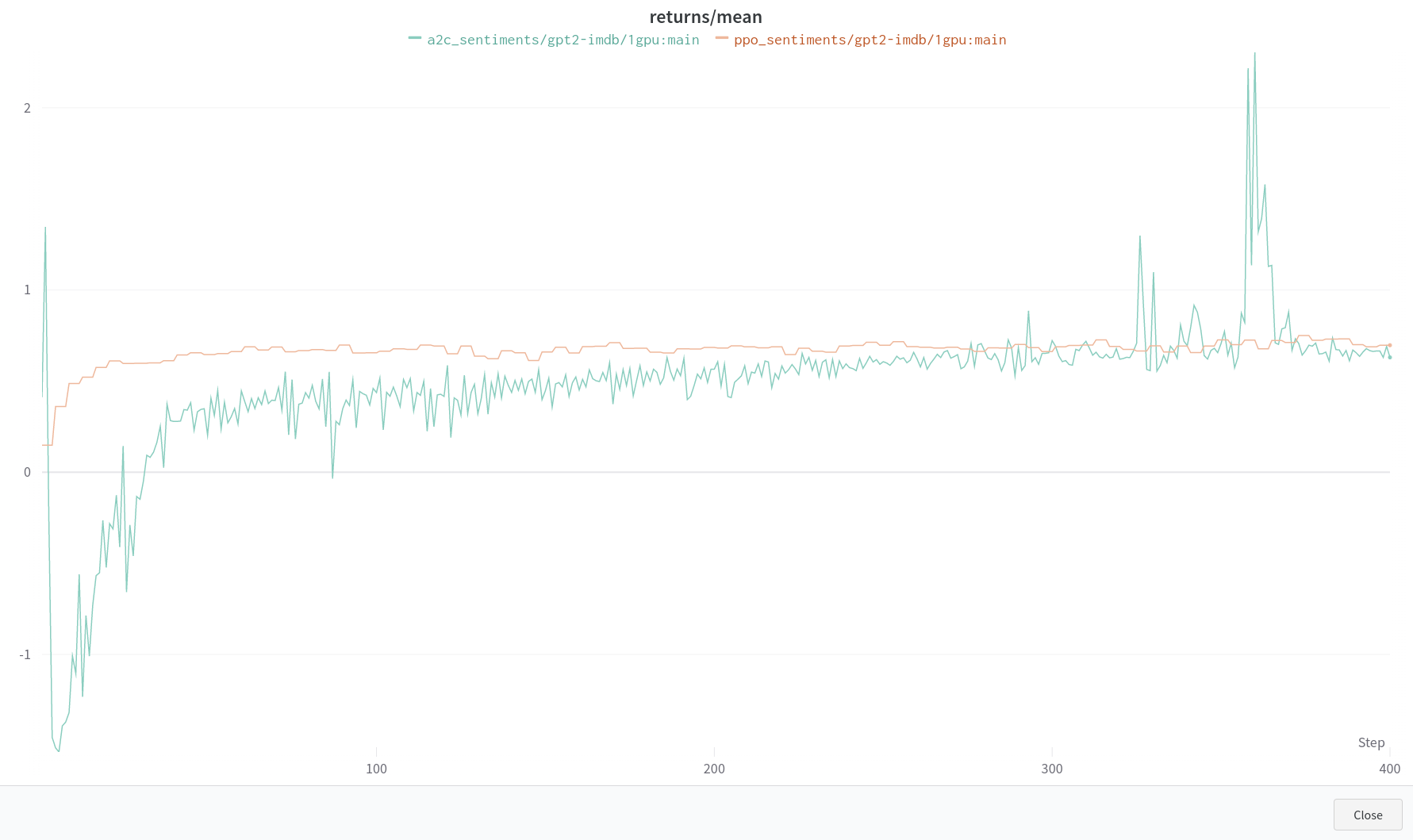
Thank you,
Enrico