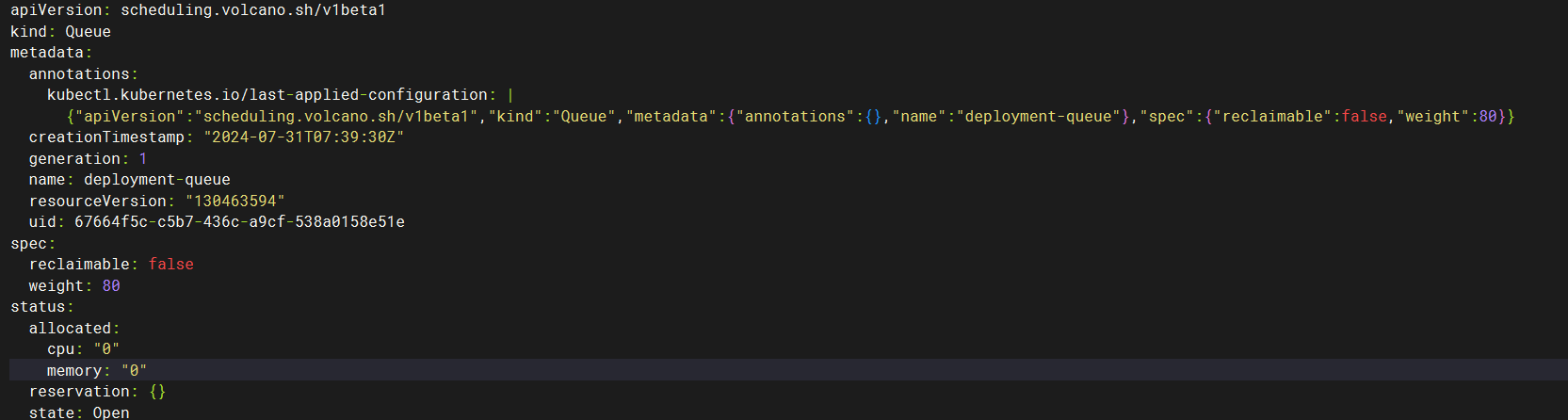
volcano calculates the true capacity
Description
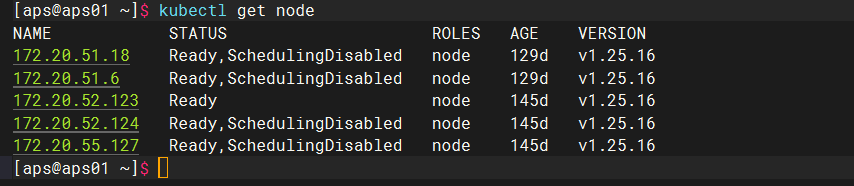
Current total resources
Only one node is available, and other nodes cannot be scheduled
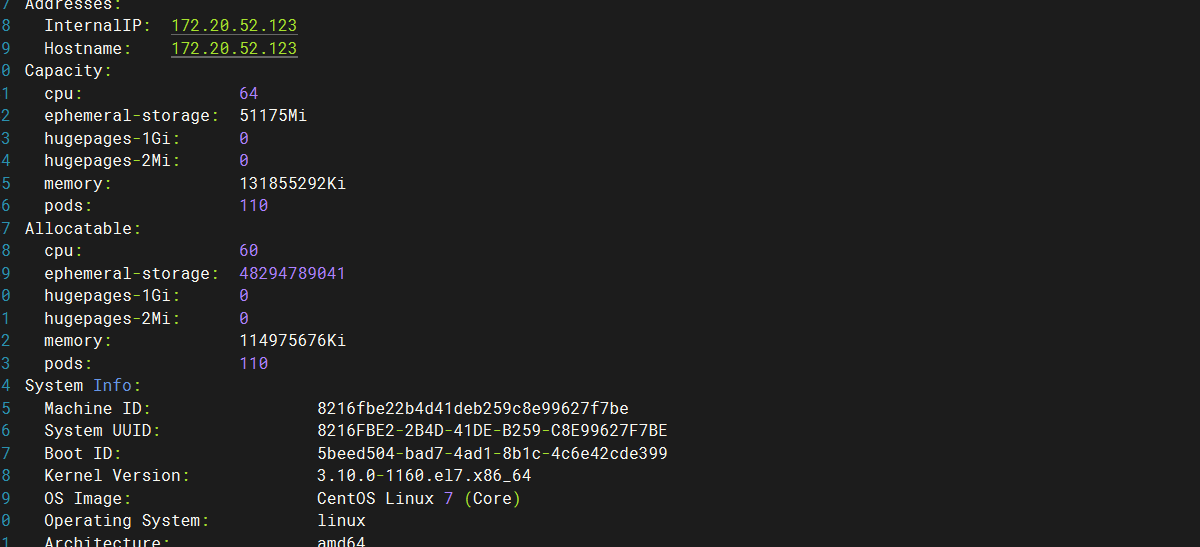
The value of a node resource is 60 based on cpu

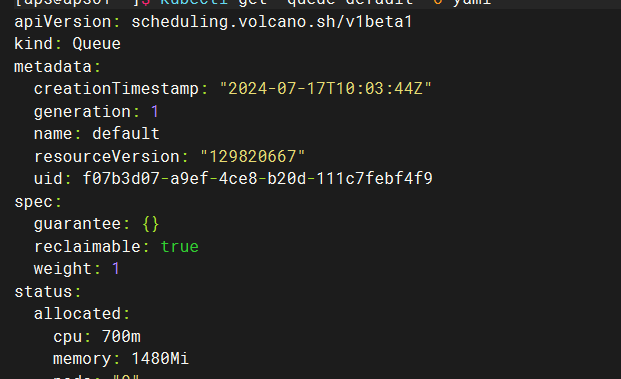
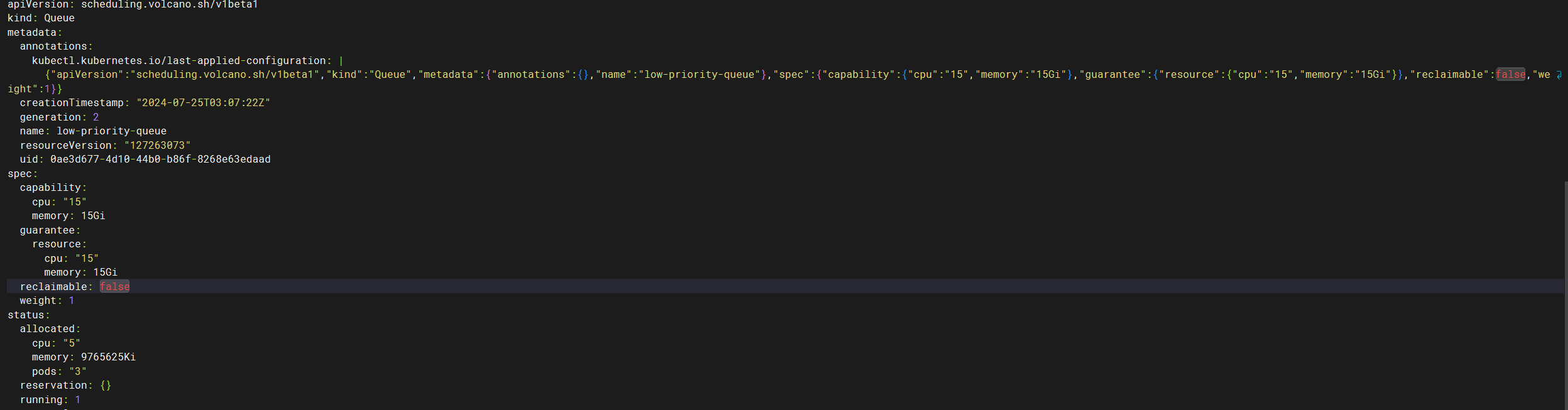
queue Settings
Three queues are configured
1.deault queue: weight=1 and 0.7c are allocated
- In the low-priority-queue queue, the default weight is 1 and guarantee is 15
3.deployment-queue. weight=88
Steps to reproduce the issue
Scenario 1
Create 3 podgroups in sequence under the deployment-queue queue
1.1 pod with 20c cpu usage
2.1 pod with 5c cpu usage
3.2 pods with 20c cpu usage
The expected result is: the first two podgroups are in Inqueue and the third is Pending.
The actual result is: all three podgroups are Inqueue, but the third podgroup will be Pending only if its cpu occupancy is 21c.
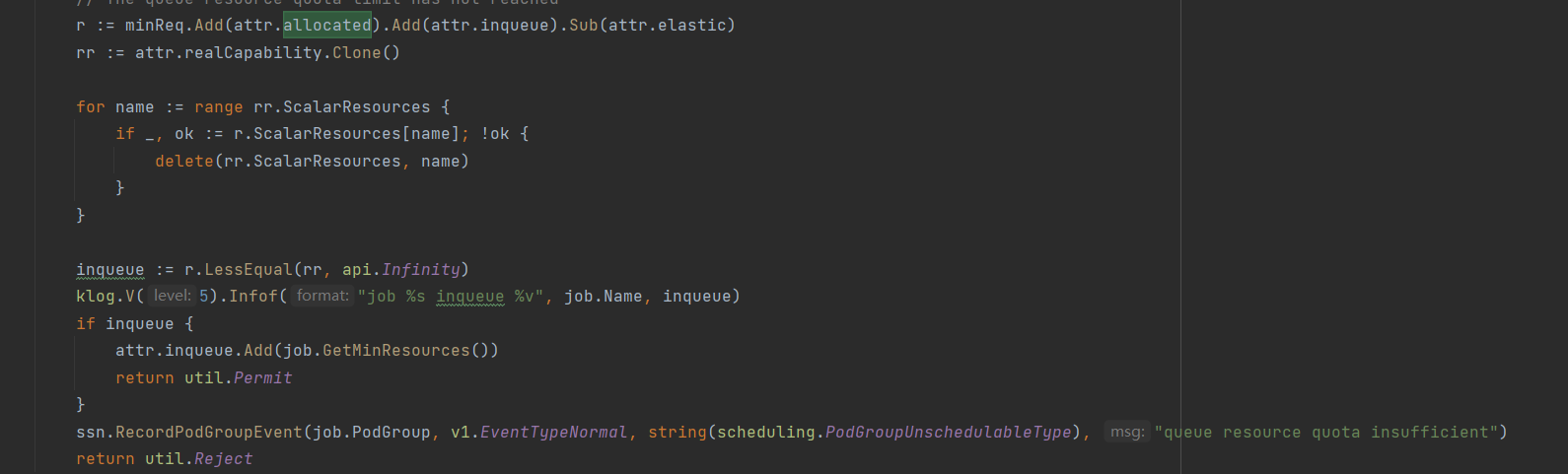
As seen in the source code, determining whether you can go from Pending to Inqueue is a function of the queue's realCapability-current-resource-queue-allocated-queue-inqueue-queue-elastic (the sum of minResource-Allocated for all podgroups)
All current resource values:
podgroup minResource cpu 20000.00
queue realCapability cpu 45000.00
queue allocated cpu 0.00
queue inqueue cpu 25000.00
queue elastic cpu 0.00
The above value is the most problematic queue realCapability, the deault queue has been allocated 0.7c, low-priority-queue queue pre-occupation of 15c, then the maximum capacity of the deployment-queue queue should be 60-0.7-15 = 44.3 is more appropriate.
Scenario 2
-
Create a podgroup and pod under the low-priority-queue queue to enable preemption of the low-priority-queue queue
-
Create 3 podgroups in turn under the deployment-queue queue
1.1 pod, cpu occupancy 10c
2.1 pods with 20c cpu usage
3.1 pods with 5 cpu usage
Create 3 pods in turn using the last 3 podgroups
! img
Modify the 1st podgroup to 2 pods with 20c cpu usage.
At this point, the status of the podgroup becomes Unknown.

Started the 1st podgroup as the 2nd pod, volcano-scheduler crashed and could no longer be started properly
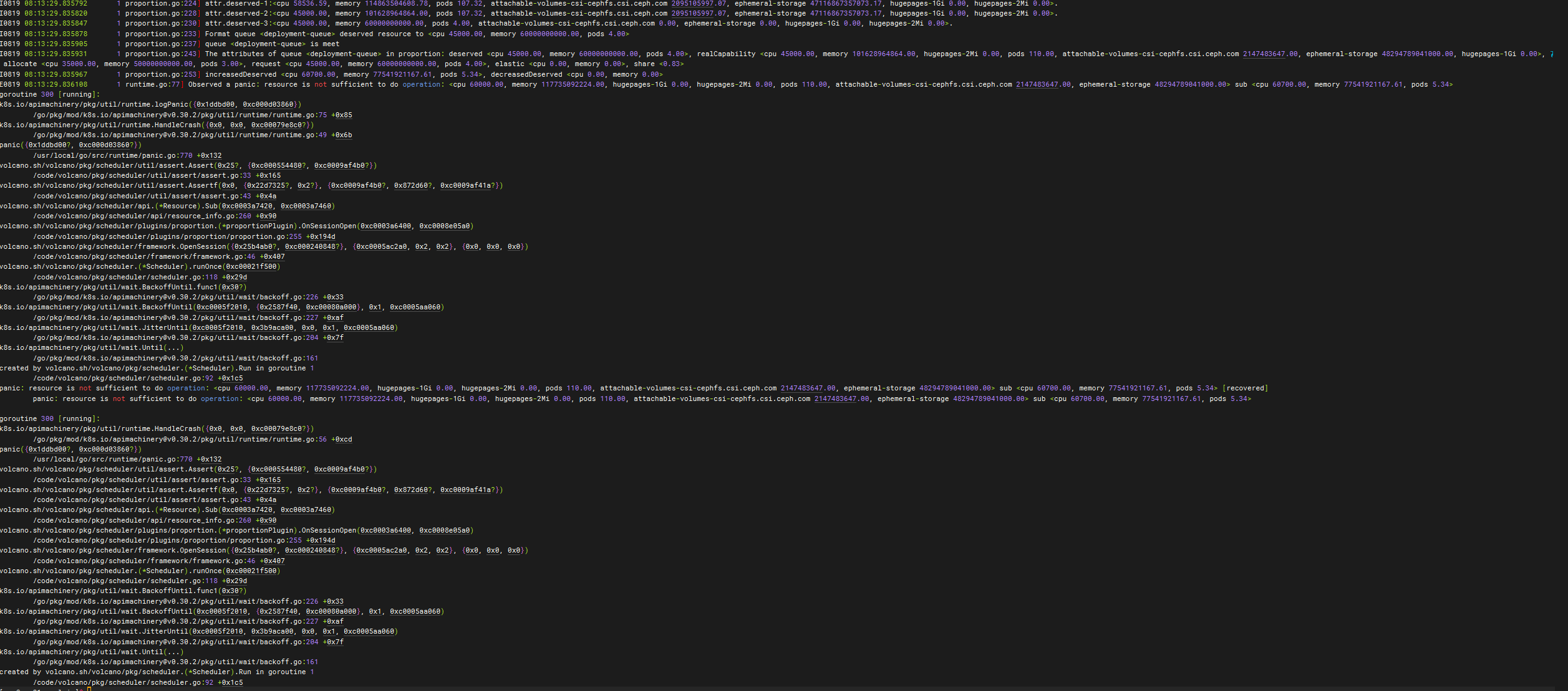
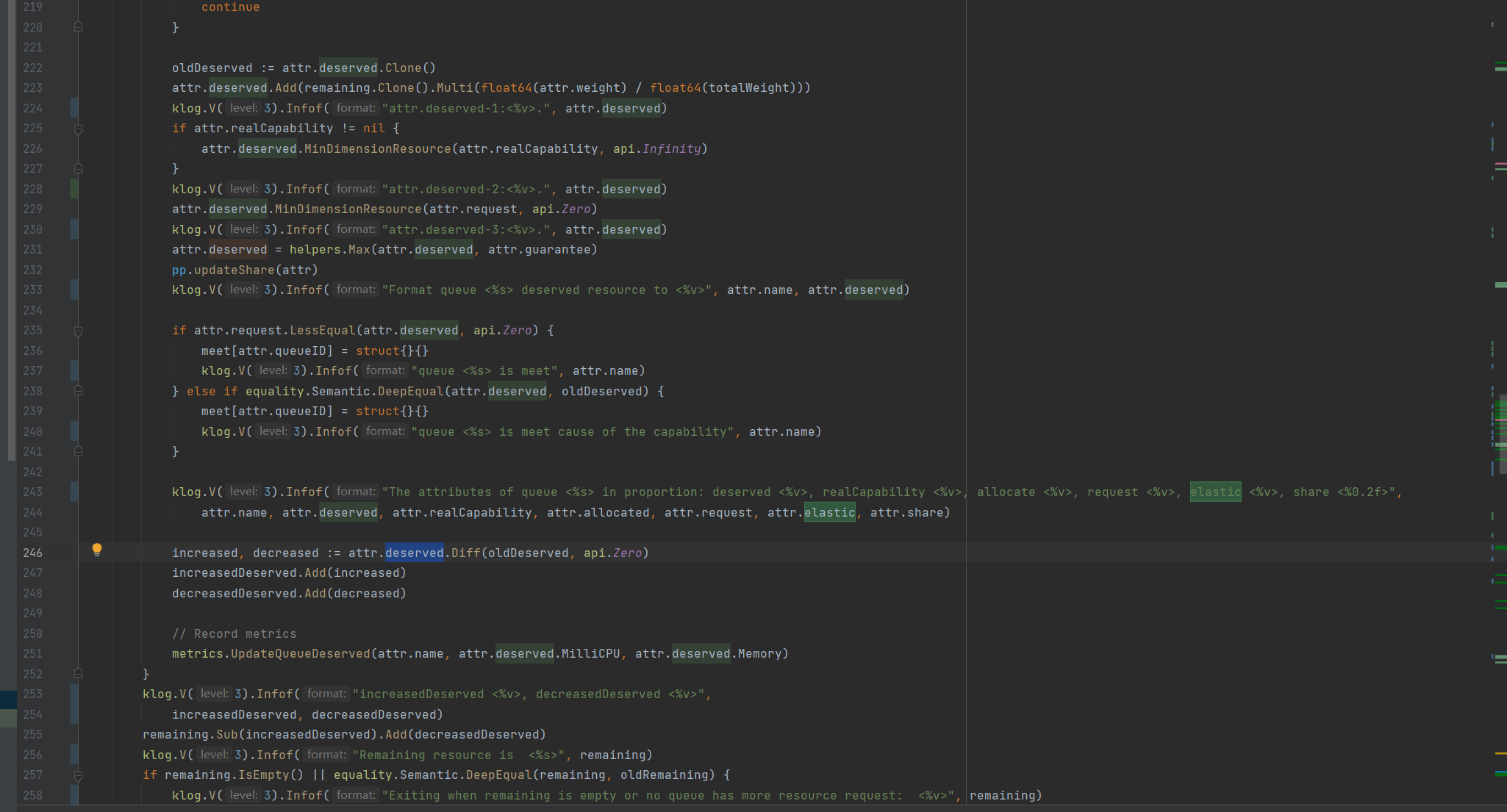
From the source code, the deserved makes is first calculated by weight (deault/low-priority-queue/deployment-queue:731.71/731.71/58536.59) and then compared to the realCapability (real capacity deault/low- priority-queue/deployment-queue:45000/60,000/45000) is taken to be small, and then compared to request (request volume deault/low-priority-queue/deployment-queue:700.00/100000.00/ 45000.00) is taken as small, and then with guarantee (preoccupation deault/low-priority-queue/deployment-queue:0/15000/0) is taken as large.
The deault/low-priority-queue/deployment-queue:700.00/15000.00/45000.00 is obtained by the above calculation.
And then add the sum to get 60700.00, more than the total resources 60000.00
It feels like the problem is still the queue realCapability, which also affects the request value. It feels like the deault queue has been allocated 0.7c, and the low-priority-queue queue is preoccupied with 15c, so the maximum capacity of the deployment-queue queue should be 60-0.7-15=44.3 more appropriately.
Describe the results you received and expected
Pods can be created normally and volcano does not report errors
What version of Volcano are you using?
1.10
Any other relevant information
No response
@ls-2018 As for scenario 1, you mean that we should consider other queue already allocated resources when calculating whether the podgroup can be inqueued? I think the logic now works correctly, when we calculate whether the podgroup can be inqueued, we use queue's (allocated + inqueue - elastic), not consider other queues allocated resource, in your scenario, although the podgroup can be inqueued, but the pod can'be allocated, so it works fine.
I can't reproduce scenario 2, do you use the deployment rather than vcjob? Why is here no 0.7c pod in your image?
Seems that in scenario 2, Sub causes the panic, but why is that...I can't reproduce it
Hello 👋 Looks like there was no activity on this issue for last 90 days. Do you mind updating us on the status? Is this still reproducible or needed? If yes, just comment on this PR or push a commit. Thanks! 🤗 If there will be no activity for 60 days, this issue will be closed (we can always reopen an issue if we need!).
Closing for now as there was no activity for last 90 days after marked as stale, let us know if you need this to be reopened! 🤗