so-vits-svc-fork
 so-vits-svc-fork copied to clipboard
so-vits-svc-fork copied to clipboard
Inference is generating worse output in current version
Describe the bug On current versions of so-vits-svc-fork (anything newer than commit hash cbd3896), inference is causing a more robotic and artifacted output than previous versions. I can downgrade to cbd3896 and my inference is spot on, however, when I update to the current version, it sounds way worse with zero changes to anything besides updating so-vits-svc-fork
To Reproduce Train or use a model on hash cbd3896 and infer with that version, then update to the current version - with the exact same arguments and files, infer with the latest. The sound will be significantly worse.
Additional context I can upload audio examples if necessary of the two different versions that will use:
- the same model
- the same input file
- the same exact command line arguments
and show: different (overall way worse) output on the current version
in file: hash_cbd3896_harvard3dio_3648.wav - this was generated monday on hash cbd3896 hash_ec135ac_harvard3_dio-1_3648.wav - this was generated yesterday on hash ec135ac hash_cbd3896_harvard3_dio-newrun_3648.wav - this was generated yesterday on hash cbd3896
All of these were generated using the same model on the same computer with the same input and same command line arguments - this should produce an identical file but as you can clearly hear, something is wrong with inference.
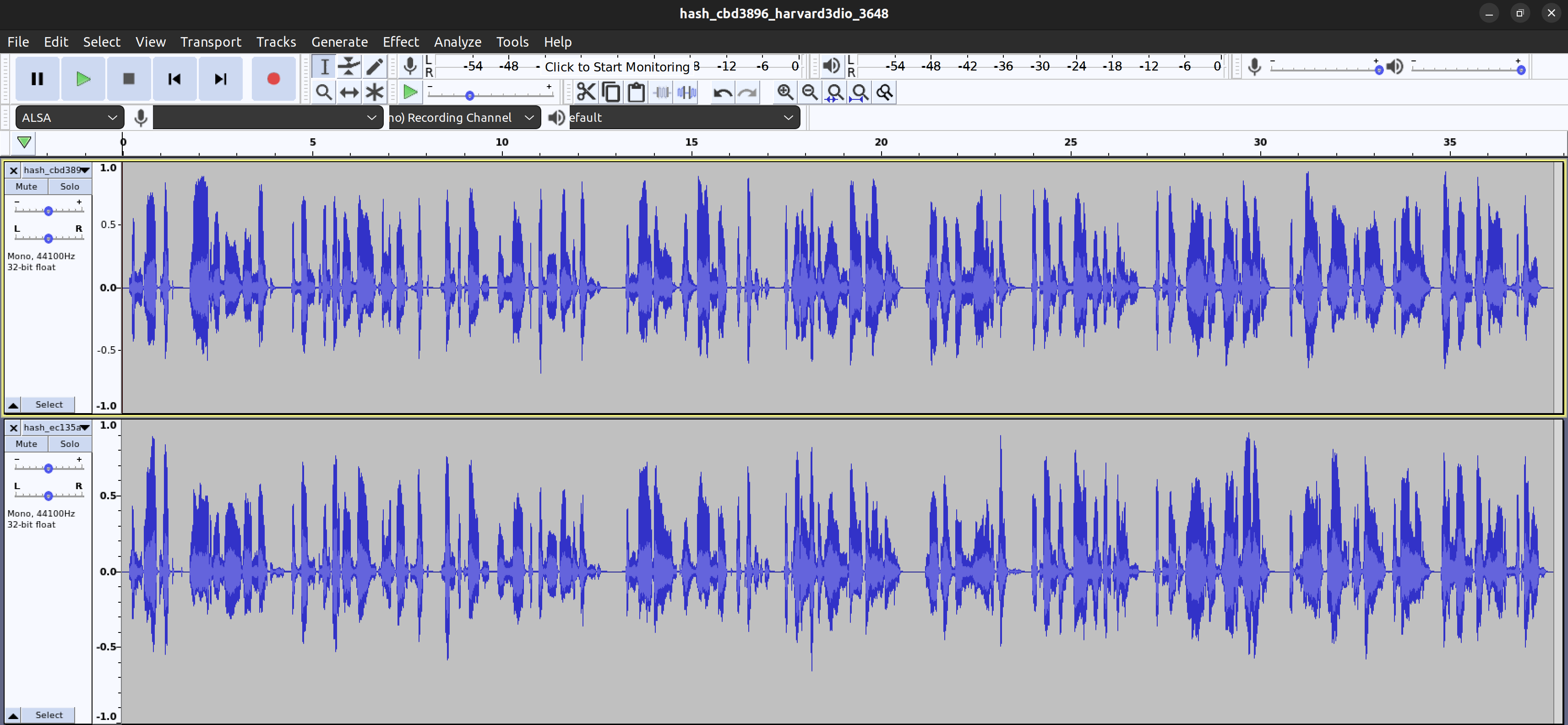
Here's a waveform view of hash_cbd3896_harvard3dio_3648 vs hash_ec135ac_harvard3_dio-1_3648
even in the wave form you can see peaks are different, things look more jagged as well
(Upper older builds == good, lower current builds == bad)