versatile-data-kit
 versatile-data-kit copied to clipboard
versatile-data-kit copied to clipboard
Add API for alert cleanup
What is the feature request? What problem does it solve? The Control Service sends notification emails for completed data job executions. The notifications are based on alerts that are themselves based on metrics exposed by the Control Service for individual data jobs. If a job is disabled, the respective alert remains active forever and this may cause noise in monitoring.
As a Control Service operator, I would like to have an option to reset such alerts manually by using the Control Service's API.
Suggested solution Provide an API to reset alerts for specific jobs.
Acceptance criteria I am able to cancel active alerts by using the API of the Control Service.
Thanks for fling this issue, @tpalashki
If a job is disabled, the respective alert remains active forever and this may cause noise in monitoring.
What is not clear to me is why it remains active forever?
Control Service itself does not send execution notifications per se. Control Service exposes a set of metrics which can be used to create alerting rules and generate notifications. Control Service Helm chart provides such rules for Prometheus.
In a quickly made diagram (thanks to mermaid.ink) flow looks like this :
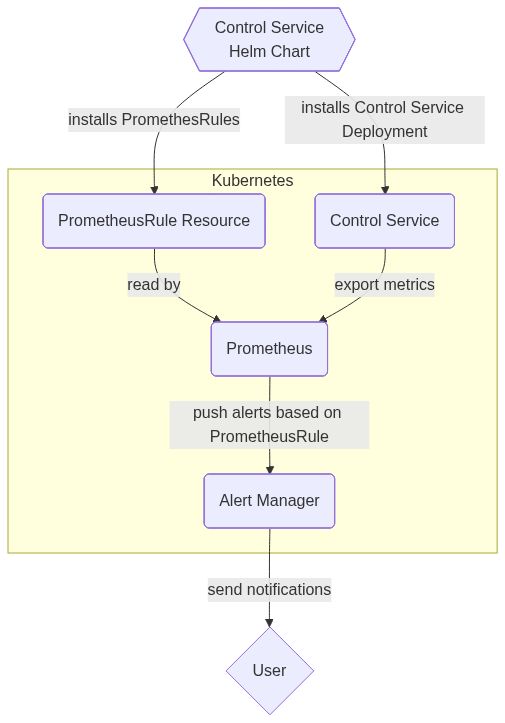
Is the problem in the PrometheusRules? Or is it a problem in the metrics exported by the Control Service ? Or is in the AlertManager Configuration?
If a job stops executing, its last termination status will remain unchanged and equal to the status of its last execution (let's assume it was a User Error). Consequently, the taurus_datajob_termination_status metrics will continue to expose value 3 (User Error) for this data job. The Prometheus rule for User Errors, which is based on this metric, will continue to evaluate to true. While this will not result in new notifications being sent, the alert itself will continue to be in a firing state as long as the rule that caused it evaluates to true.
To summarize: there is no problem with the metrics, rules, and notifications per se - they are working as designed. The problem is that if there is an error in job executions, this error will continue to show up until the job is fixed, which may take a long time.
In the description, we say "if a job is disabled". This is an API operation. If a user disables a job, then we can reset the termination_status so it no longer fires, right? Wouldn't this be more appropriate?
If a job is actively failing, sending an alert every now and then as a reminder seems a valid case. If a user wants to stop getting those notifications, they can unsubscribe.
Good point. This will be helpful, but it will not cover all use cases. For example, jobs that execute rarely (once a month) or jobs that never execute (with schedule way into the past/future) and are only executed manually. Also, this API will cover the status of job deployments.
I am wondering do we need an API or we can automatically clean them based on configuration.
Good idea. We can introduce a configuration similar to Prometheus (resolve_timeout) to specify the time after which the alert is automatically resolved.
Good idea. We can introduce a configuration similar to Prometheus (
resolve_timeout) to specify the time after which the alert is automatically resolved.
Sounds good. In my opinion we should reduce the operator duties as much as possible.