leevis.com
 leevis.com copied to clipboard
leevis.com copied to clipboard
Blog
### 概述 naxsi 是第三方的一个WAF模块,更对请参考《[nginx 的 WAF 模块 naxsi](https://github.com/vislee/leevis.com/issues/143)》 ### 代码分析 模块指令比较多,指令配置比较复杂。因此指令解析的代码读起来比较费劲,结构体定义也多。 该模块支持nginx格式的指令【例如:main_rule】,也支持非nginx(可能是Apache格式)的指令【例如:MainRule】,文档中是非nginx格式的指令。 结合配置文件先来看下部分指令解析。吐槽一下该模块并没有遵守nginx的代码风格,我看的时候稍作优化 [AStyle](http://astyle.sourceforge.net/astyle.html) -A14 -p -j -c -Y -z2 -k3 -n *.c #### 指令解析 + 结构体 ```c // naxsi...
### 概述 [NAXSI](https://github.com/nbs-system/naxsi) 是开源的一个nginx模块。和[ModSecurity](https://github.com/SpiderLabs/ModSecurity) 类似。而ModSecurity目前对nginx支持不太好。 + 编译安装 ```sh ./auto/configure --add-module=../github.com/nbs-system/naxsi/naxsi_src ``` + 文档 [documentation](https://github.com/nbs-system/naxsi/wiki) ### 指令 #### 规则 NAXSI 提供了灵活的规则配置。先看一份[简单可读的规则](https://github.com/nbs-system/naxsi/blob/master/naxsi_config/naxsi_core.rules) 有个大概印象后接下来看规则的定义。 规则分为`MainRule|main_rule`和`BasicRule|basic_rule`。MainRule 配置在http块下,BasicRule配置在location块下。一般情况下main_rule用来配置规则,basic_rule用来配置白名单。 规则的语法如下图,除了id,其余的部分都必须要用双引号: 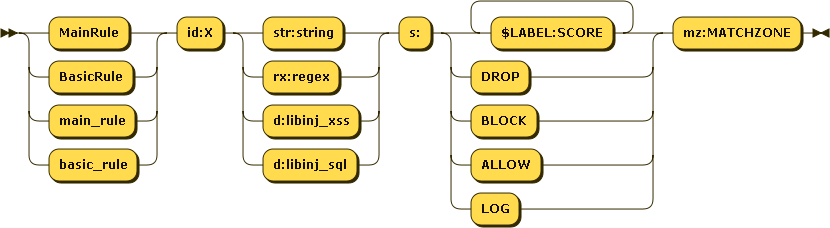 例如: ```nginxconf MainRule id:4242...
# 关于工作相关的一些思考 没有银弹,任何的情况下都需要你结合当初的情况找一个平衡点。而这个平衡点的选择就是你的经验和思考的结果。 + 关于架构、系统: 所有互联网中的大型系统,都可以拆分为很多小系统解决。而小的系统在互联网界都可以找到可复用的或者其思路是你可以借鉴的。所以技术上并不是难点,真正的难点是结合你的业务怎么拆分,拆分了以后怎么组合。 + 关于算法: 找到时间和空间的平衡点。 最快的算法O(1),hash表、数组。 一般的算法能达到O(N*logN)就可以在生产中使用了。 也不是说O(N\*N)就不能用,看场景和数据量。比如:nginx在启动阶段,构件location平衡二叉树用了插入排序。 所以,生产系统中我们是尽可能的把算法时间复杂度降到最低,但是通常情况下,快速排序、二分法查找已经就够了。 + 关于数据结构: 数组、链表、红黑树。数据是可以确定的,那么数组是个很好的选择。当有大量的增删操作存在时就需要用到链表或二叉树。没有顺序要求的时候,链表表现也可以接收,当有顺序要求的时候,链表的时间复杂度太高,需要用到跳表或平衡二叉树。平衡二叉树的实现太复杂,也没必要必须平衡,近平衡就可以,所以用红黑树。例如:nginx定时器就是一颗红黑树,在linux内核中也大量用到红黑树。 + 关于高性能: 最好的情况下是用业务逻辑把CPU性能压榨干,但是这个是不现实的,业务程序是跑在操作系统上面的,操作系统的运行是需要消耗CPU的。所以,能把CPU跑起来,尽可能的减小无谓的CPU消耗就可以了。 + 关于分布式: 不可以逾越的CAP,解决办法:一致性哈希算法、2阶段或3阶段提交。 + 关于回调函数: 合理的回调函数设计,一定是这个程序最精彩的地方。如果没有nginx的回调、没有openssl的回调,也就没有openresty的玩法。 + 关于我的技术栈: 接口用openresty写,后台服务用golang写。 + 关于代码规范:...
```lua -- mysql 链接 local mysql_singleton = function(host) local db = nil local create = function() if db then return db end local d, e = mysql:new() if not d...
### 概述 [stream proxy](http://nginx.org/en/docs/stream/ngx_stream_proxy_module.html) 模块是stream类型模块的重点。四层代理的主要功能实现模块。 该proxy模块也提供了proxy_pass指令把4层流量转发到上游。 ### 源码 stream类型的模块是通过一个ngx_stream_module的核心模块来管理的。 在stream指令的解析函数ngx_stream_block中,首先会创建一个ngx_stream_conf_ctx_t类型的上下文ctx,该结构体有两个指针数组的成员,用来保存stream类型模块的main和srv级别的配置。 ```c typedef struct { void **main_conf; // 指针数组指针 void **srv_conf; // 指针数组指针 } ngx_stream_conf_ctx_t; ctx = ngx_pcalloc(cf->pool, sizeof(ngx_stream_conf_ctx_t)); ctx->main_conf =...
### 概述 http协议的请求(request)分为3部分, 第一部分为请求行(request line),第二部分为请求头(request header),第三部分为请求体(request body)。 请求行格式: 请求方法 | 空格 | URI | 空格 | 协议版本 | 回车符 | 换行符 --------- | ---- | ---- | ----- | --------...
### 概述 早在nginx version 1.1.4 提供了keepalive指令,支持upstream的长链接。如果不配置该指令,ngx和ups每次请求都会建立一个新的tcp连接,请求结束后关闭。 ### 源码分析 nginx的模块化和异步回调可以让nginx支持模块来实现一些新功能。该功能是ngx_http_upstream_keepalive_module模块提供的,在src/http/modules/ngx_http_upstream_keepalive_module.c文件中。 #### 指令解析 在指令解析阶段通过,keepalive指令对应的回调函数ngx_http_upstream_keepalive来潜入ngx中。在该函数中,用该模块的结构体把原来的回调函数保存下来。把该模块的功能函数赋值。 ```c // 保存长链接 typedef struct { ngx_http_upstream_keepalive_srv_conf_t *conf; ngx_queue_t queue; ngx_connection_t *connection; socklen_t socklen; ngx_sockaddr_t sockaddr; } ngx_http_upstream_keepalive_cache_t;...

### 概述 域名在互联网中广泛应用,而http是建立在tcp/ip协议上的,tcp/ip协议只认识ip地址,所以就需要通过某个系统(DNS)把域名转换成ip地址供底层使用。 通常linux系统下,命令行使用dig查询,c语言使用gethostbyname或getaddrinfo函数查询。实际上都是发送一个网络请求到/etc/resolv.conf下的一个服务器查询。 nginx作为一个通用的服务器也会涉及到域名解析。例如,nginx 用作反向代理可以配置upstream是一个域名。` proxy_pass http://www.baidu.com/$request_uri; ` 那么www.baidu.com这个域名是什么时候解析的呢?又是如何解析的呢?如果没有添加$request_uri这个变量解析会有区别么? nginx是单进程异步非阻塞服务,如果用getaddrinfo来解析势必会导致nginx阻塞。在启动阶段阻塞一小会儿不会有大的影响,如果在服务处理阶段阻塞,会导致该进程所服务的客户端延迟甚至出错。 proxy_pass 对应的域名解析分为有变量和没有变量,没有变量的是在启动阶段解析, 而有变量的是在每次请求解析的,每次请求解析在nginx是怎么做的?还是异步回调。 ### DNS报文 nginx会拼装DNS查询报文,所以现了解一下DNS报文格式。也可以略过直接看大框架逻辑。 #### 报文格式 + 报文格式: ``` DNS format +--+--+--+--+--+--+--+ | Header | 报文头 +--+--+--+--+--+--+--+...
### 概述 upstream的server 支持配置域名。但是只是在启动的时候调用了glibc的getaddrinfo函数解析的,而不是通过`reslover`配置的域名服务器解析的。具体细节请看《nginx 域名动态解析》。 当域名对应的地址有变化时,nginx是不会自动更新的,只能通过重启nginx来解决。其实官方商业版是提供了解决方案的。在`server`这个指令提供了个resolve参数用来动态解析地址。就是说server配置的域名解析有更新,不用重启nginx了。商业版本不仅提供了动态解析,还可以通过REST API来修改upstream的server。 ### 实现 本人参考官方文档实现了一个模块,提供域名动态解析和REST API来修改upstream的server。 目前还处于测试阶段。大概先说一下实现思路。 nginx主线版本从1.9.0开源了一个ngx_http_upstream_zone_module模块。该模块在upstream这个block提供了一个`zone`指令。用来把upstream的信息保存到共享内存中。仅此而已,没有开源任何相关的用途。 那我们就可以基于该模块来实现域名动态解析和REST API。nginx的很多函数都是回调函数,在赋值和调用过程中我们可以嵌入我们的模块修改回调函数赋值,从而把我们的逻辑加入到nginx中。 upstream这个block有好多负载均衡策略的配置,例如ip_hash,我们可以参考该实现来把自己的实现嵌入到nginx中。 我们在upstream这个block提供一个指令`server_resolver`,在该指令的实现函数中把uscf->peer.init_upstream 回调修改成我们自己的实现ngx_http_upstream_init_resolver,从而把我们自己的逻辑嵌入到nginx中。该回调是在ngx_http_upstream_init_main_conf函数中被调用的。 回调函数也可以参考ip_hash的实现,先调用原来peer.init_upstream的回调函数初始化上游服务器。然后把我们的实现ngx_http_upstream_init_resolver_peer赋值us->peer.init函数指针么,在ngx_http_upstream_init_request函数中被调用。 我们可以在该函数ngx_http_upstream_init_resolver_peer中就实现解析域名。也可以继续赋值在upstream->peer.get或upstream->peer.free中解析域名。目前实现是在该函数就解析域名了。 在该函数ngx_http_upstream_init_resolver_peer中主要的任务是赋值负载均衡策略的回调函数,然后找一个需要解析的域名发起域名解析请求,并赋值好回调函数。从此域名解析就脱离upstream机制,当域名解析结果返回时调用添加的回调函数。把解析结果添加到upstream的server的共享内存中。销毁域名解析相关结构体和函数。 参考: http://nginx.org/en/docs/http/ngx_http_upstream_module.html http://nginx.org/en/docs/http/ngx_http_api_module.html
### 概述 该模块通过发起子请求来验证http请求。 ```sh location /test1 { auth_request /auth1; hello_world; hello_by "hello liwq"; } location /test2 { auth_request /auth2; } location /auth1 { return 200 "ok"; } location /auth2 {...