vecto
 vecto copied to clipboard
vecto copied to clipboard
Fail to reproduce the result in "Subcharacter Information in Japanese Embeddings: When Is It Worth It?"
Hi.
I tried to use this project to reproduce the results in
Karpinska, Marzena, et al. "Subcharacter Information in Japanese Embeddings: When Is It Worth It?." Proceedings of the Workshop on the Relevance of Linguistic Structure in Neural Architectures for NLP. 2018.
I used the openly shared JP word vectors (without character and subcharacter).
However I found that for each subset the result is much lower than the paper. (Method = 3CosAdd)
My code to see the result is as follows:
jBATS_folder = '../analogy_results/word_analogy/JBATS_1.0/'
result_file = os.path.join(jBATS_folder, '19.05.29_21.14.41', 'results.json')
with open(result_file, 'r') as f:
data = json.load(f)
for subset in data:
print(len(subset['details']))
print(subset['result'])
The result is as follows:
2450
{'cnt_questions_correct': 1090, 'cnt_questions_total': 2450, 'accuracy': 0.4448979591836735}
2550
{'cnt_questions_correct': 2558, 'cnt_questions_total': 5000, 'accuracy': 0.5116}
3192
{'cnt_questions_correct': 3537, 'cnt_questions_total': 8192, 'accuracy': 0.4317626953125}
2450
{'cnt_questions_correct': 5636, 'cnt_questions_total': 10642, 'accuracy': 0.529599699304642}
2450
{'cnt_questions_correct': 6832, 'cnt_questions_total': 13092, 'accuracy': 0.5218454017720745}
3192
{'cnt_questions_correct': 7826, 'cnt_questions_total': 16284, 'accuracy': 0.48059444853844263}
2450
{'cnt_questions_correct': 8885, 'cnt_questions_total': 18734, 'accuracy': 0.47427137824276716}
2450
{'cnt_questions_correct': 10426, 'cnt_questions_total': 21184, 'accuracy': 0.49216389728096677}
2450
{'cnt_questions_correct': 11819, 'cnt_questions_total': 23634, 'accuracy': 0.500084623847}
2450
{'cnt_questions_correct': 12853, 'cnt_questions_total': 26084, 'accuracy': 0.49275417880693145}
2450
{'cnt_questions_correct': 13217, 'cnt_questions_total': 28534, 'accuracy': 0.46320179435059927}
2450
{'cnt_questions_correct': 14000, 'cnt_questions_total': 30984, 'accuracy': 0.4518461141234185}
2450
{'cnt_questions_correct': 14365, 'cnt_questions_total': 33434, 'accuracy': 0.42965244960220134}
2450
{'cnt_questions_correct': 14621, 'cnt_questions_total': 35884, 'accuracy': 0.40745178909820534}
2450
{'cnt_questions_correct': 14955, 'cnt_questions_total': 38334, 'accuracy': 0.3901236500234779}
2652
{'cnt_questions_correct': 15478, 'cnt_questions_total': 40986, 'accuracy': 0.3776411457570878}
2450
{'cnt_questions_correct': 15695, 'cnt_questions_total': 43436, 'accuracy': 0.36133621880467814}
2450
{'cnt_questions_correct': 15926, 'cnt_questions_total': 45886, 'accuracy': 0.347077539990411}
2450
{'cnt_questions_correct': 16339, 'cnt_questions_total': 48336, 'accuracy': 0.33802962595167163}
2450
{'cnt_questions_correct': 17286, 'cnt_questions_total': 50786, 'accuracy': 0.3403693931398417}
2450
{'cnt_questions_correct': 17980, 'cnt_questions_total': 53236, 'accuracy': 0.33774137801487714}
2352
{'cnt_questions_correct': 18442, 'cnt_questions_total': 55588, 'accuracy': 0.3317622508455062}
2162
{'cnt_questions_correct': 19739, 'cnt_questions_total': 57750, 'accuracy': 0.3418008658008658}
2450
{'cnt_questions_correct': 19949, 'cnt_questions_total': 60200, 'accuracy': 0.33137873754152825}
2450
{'cnt_questions_correct': 20158, 'cnt_questions_total': 62650, 'accuracy': 0.321755786113328}
2450
{'cnt_questions_correct': 20252, 'cnt_questions_total': 65100, 'accuracy': 0.3110906298003072}
2450
{'cnt_questions_correct': 20253, 'cnt_questions_total': 67550, 'accuracy': 0.2998223538119911}
2450
{'cnt_questions_correct': 20472, 'cnt_questions_total': 70000, 'accuracy': 0.29245714285714286}
2450
{'cnt_questions_correct': 20640, 'cnt_questions_total': 72450, 'accuracy': 0.28488612836438926}
2550
{'cnt_questions_correct': 20657, 'cnt_questions_total': 75000, 'accuracy': 0.27542666666666665}
2450
{'cnt_questions_correct': 20741, 'cnt_questions_total': 77450, 'accuracy': 0.26779857972885734}
2450
{'cnt_questions_correct': 20869, 'cnt_questions_total': 79900, 'accuracy': 0.26118898623279097}
2450
{'cnt_questions_correct': 21030, 'cnt_questions_total': 82350, 'accuracy': 0.2553734061930783}
2450
{'cnt_questions_correct': 21086, 'cnt_questions_total': 84800, 'accuracy': 0.24865566037735848}
2450
{'cnt_questions_correct': 21170, 'cnt_questions_total': 87250, 'accuracy': 0.24263610315186246}
2450
{'cnt_questions_correct': 21242, 'cnt_questions_total': 89700, 'accuracy': 0.23681159420289855}
2450
{'cnt_questions_correct': 21375, 'cnt_questions_total': 92150, 'accuracy': 0.23195876288659795}
2450
{'cnt_questions_correct': 21636, 'cnt_questions_total': 94600, 'accuracy': 0.22871035940803383}
2450
{'cnt_questions_correct': 21859, 'cnt_questions_total': 97050, 'accuracy': 0.2252344152498712}
2450
{'cnt_questions_correct': 22208, 'cnt_questions_total': 99500, 'accuracy': 0.2231959798994975}
The command to run the task is,
python -m vecto benchmark analogy Karpinska/word/vectors Karpinska/JBATS_1.0 --path_out analogy_results/ --method 3CosAdd
The embeddings and jBATS set are from http://vecto.space/projects/jBATS/
Could you please tell me what is the result in the outputfile and how to get the accuracy on each subset correctly?
Thank you.
I guess 2450 is 50*49 for the number of a:b=c:d pairs. However, I found that the result is much lower than the paper with the opened word embeddings. Is the program wrong?
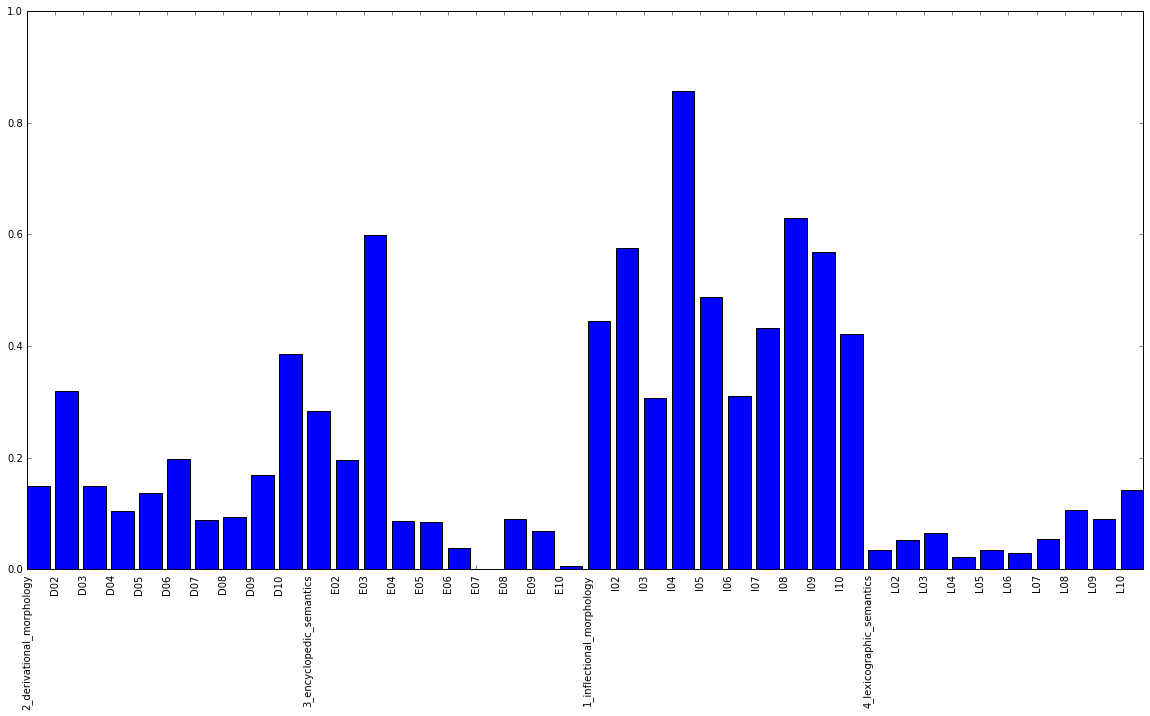
I changed the accumulated score to the respective score for each subset and plot the result.
code:
accuracy_reports_c2 = []
pre1=0
pre2=0
for data_set in data:
corrects = data_set['result']['cnt_questions_correct'] - pre1
total = data_set['result']['cnt_questions_total'] - pre2
pre1 = data_set['result']['cnt_questions_correct']
pre2 = data_set['result']['cnt_questions_total']
accuracy_c2 = corrects/total
print(corrects, total, accuracy_c2)
accuracy_reports_c2.append(accuracy_c2)
accuracy_reports_new_c2 = accuracy_reports_c2[10:20] + accuracy_reports_c2[20:30] + accuracy_reports_c2[0:10] + accuracy_reports_c2[30:40]
subcat_ids=[]
for data_set in data:
subcat = (data_set['experiment_setup']['subcategory'])
print(subcat)
subcat_id = subcat.split(' ')[0]
subcat_ids.append(subcat_id)
subcat_ids_new = subcat_ids[10:20] + subcat_ids[20:30] + subcat_ids[0:10] + subcat_ids[30:40]
%matplotlib inline
import matplotlib.pyplot as plt
plt.figure(figsize=(20, 10))
plt.ylim(top=1)
plt.xticks(range(len(accuracy_reports_new_c2)), subcat_ids_new)
plt.bar(range(len(accuracy_reports_new_c2)), accuracy_reports_new_c2)
Figure:
Hi, I'm attending NAACL 2019 now, but will try to check your issue soon. Aren't you coming to this conference yourself by any chance? If so, you can catch me here.
Hi,
1, So sorry that there is indeed a bug in analogy test code, where we accumulated the scores. We have already fixed it, please try the latest code.
2, For the accuracy of each category, you can just count the correct examples and divide by the total examples.
3, The embedding we published is trained on both wiki and mainichi, so the results are different than the paper reported. I just re-tested the embedding (SG) using the latest code (LRCos), and gets
1_inflectional_morphology 0.8008130081300813 2_derivational_morphology 0.47478991596638653 3_encyclopedic_semantics 0.43768115942028984 4_lexicographic_semantics 0.14549653579676675, which is higher than the paper in inf and der category. However, let me know if you need the embeddings trained only on wiki.