sos
 sos copied to clipboard
sos copied to clipboard
Workload of substeps for cluster execution.
Running a large number of external tasks executed on a cluster system could be frustrating with cluster-related failures. It is appealing to stop using external tasks and execute the workflow entirely on a cluster system ( https://vatlab.github.io/sos-docs/doc/user_guide/remote_execution.html#Executing-workflows-on-cluster-systems ).
In this scenario substeps are distributed to workers, almost randomly. However, a complex workflow can have a variety of substeps, some large and some small and it is difficult to control the resources used by them. For example, if multiple large substeps are distributed to a single worker (with one or multiple workers), they might bring down the computing node, while other computing nodes are using only a fraction of the resources allocated.
A seemingly reasonable solution is to honor
task: mem='', cores=''
with -q none during the dispatch of substeps.
It is appealing to stop using external tasks and execute the workflow entirely on a cluster system
This means interacting with the queue system once and let SoS take from there? How many jobs will we see on the queue for this case? If it is a single SoS job, what if it requires lots of resources and therefore never get to run due to queue priority issues? Sorry if I don't get the idea, but I want to clarify how it works and why it is more robust.
I would very much like to see a more robust cluster execution, but still taking advantage of the queue system by striking a balance between number of jobs submitted and execution time per job. The MPI feature we implemented this summer seems to best serve the purpose although it is not robust (anything to do with the internal ssh communications?) and thus I mostly still submit single node jobs for production.
some large and some small and it is difficult to control the resources used by them
But isnt this is also an issue with the previous external task mechanism? or you are saying for previous case PBS can potentially take care of it, but for the proposed new executor they were just randomly distributed? Still previously different substeps will use the same allocated resources.
I was not particularly bothered by the problem of heterogeneous resource usage for substeps because I usually guestimate the heaviest substep for a step and assign resources based on that substep. It's a bit conservative but this is what people would probably have done anyways when they directly submit batch job scripts -- that is, usually no fine-tuning for a particular substep.
This means interacting with the queue system once and let SoS take from there?
Yes, https://vatlab.github.io/sos-docs/doc/user_guide/remote_execution.html#Executing-workflows-on-cluster-systems illustrates the idea.
How many jobs will we see on the queue for this case?
One.
If it is a single SoS job, what if it requires lots of resources and therefore never get to run due to queue priority issues?
Technically speaking the overall resources used would be the same anyway.
I want to clarify how it works
WIth the new workflow PBS engine I am working on (not ready yet), you should be able to do something like
sos run workflow [parameters] -r cluster nodes=6 cores=5 mem=2G
to submit the workflow to the cluster.
why it is more robust.
There is no guarantee of robustness. This ticket is listing one of the potential problems, and the workers could be made more robust by automatically start itself in case of error etc. The point is that there is less interaction with the PBS system so whatever problem remains could be tackled on the SoS side.
it is not robust (anything to do with the internal ssh communications?) and thus I mostly still submit single node jobs for production.
In theory there is no need for persistent ssh to remote workers because once the worker is started it will communicate through zmq. I kept the process because with the current implementation (how the worker starts) the workers would be killed once the ssh connection is disconnected....
These are things need to be improved for remote execution.
But isnt this is also an issue with the previous external task mechanism? or you are saying for previous case PBS can potentially take care of it, but for the proposed new executor they were just randomly distributed? Still previously different substeps will use the same allocated resources.
The task mechanism has the advantage that resources for individual tasks are specified so PBS knows the "large" and "small" tasks. For the new execution model there is no task so large and small substeps are sent to workers regardless of available resources on workers, thus this ticket.
I was not particularly bothered by the problem of heterogeneous resource usage for substeps because I usually guestimate the heaviest substep for a step and assign resources based on that substep.
This is what people usually do, and https://github.com/vatlab/sos/issues/1296 already took care of some of the same issue here.
Technically speaking the overall resources used would be the same anyway.
True, but the priority in the queue might be different as PBS has to find a bulk resource rather than running when available. ... but for my particular case (of having a quite nice cluster here) this does not bother me as much as the robustness issue.
there is less interaction with the PBS system so whatever problem remains could be tackled on the SoS side.
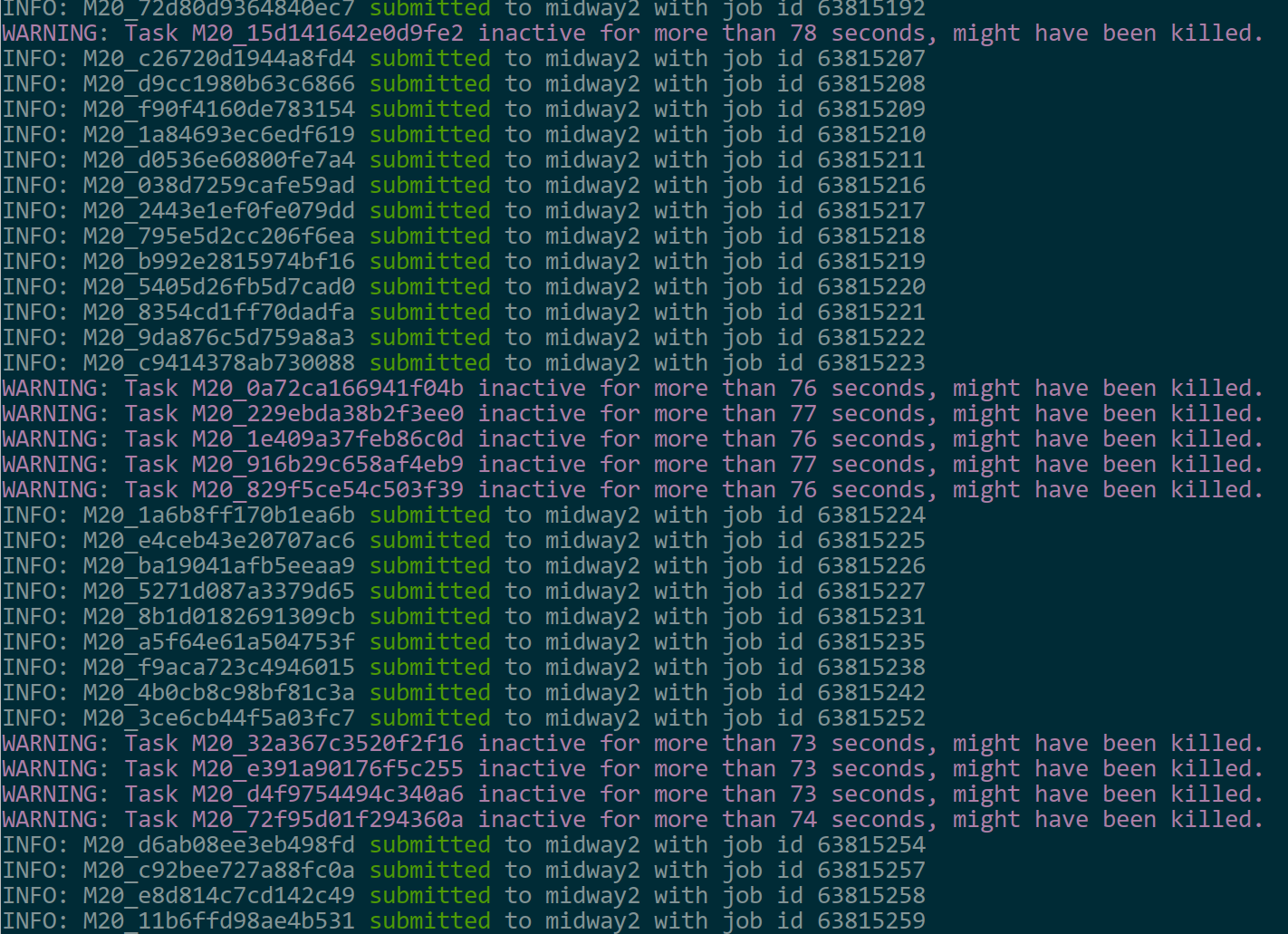
This is nice -- yes that's what I suspect the non-robust behavior stems from. For example here is a screenshot of my terminal as of right now:
We have this problem all the time and the only solution was to resubmit. It can be frustrating for large benchmarks.
The task mechanism has the advantage that resources for individual tasks are specified so PBS knows the "large" and "small" tasks
PBS only knows large and small tasks at step level right? That is, different steps may have different resource requirement but all substeps are going to use the same resource. My understanding is that with the new behavior you are working on now, there will be no distinction between resources used by different steps, unless as you said there is a way to honor those specifications?
there will be no distinction between resources used by different steps, unless as you said there is a way to honor those specifications?
Yes, because in that case all substeps are randomly distributed to available workers, so all workers on a node might be taking heavy substeps and fail.
#1296 says there should be at most N large steps being executed, regardless of workers. So if we have for example 8 workers on a single node, at most 2 large steps would be running on it if we set concurrent=2. The rest of the workers will be idling or taking smaller substeps from other steps, and reduces the risk of node failure.
Honoring task: mem='4G' with queue=None is another idea brought up in #1296 and was dismissed because it was trivial to implement concurrent=N, and right now SoS does not know the worker configuration. I mean, currently we submit workflow to the cluster with a template (unknow to SoS), and SoS only get the -j option from the cluster system, without information on how much ram was allocated for each worker...
Overall I think it is more important to fix the task inactive for xx seconds issue but I cannot yet reproduce it reliably here to figure out why that happened. Because inactivity is detected by the change of pulse files, it could be caused by the slowness of the file system when there are a large number of tasks, each touching its pulse file for every 10 seconds or so. Or it could be caused by the threading model of tasks execution, meaning if the main thread is executing an external command the pulse thread never got executed to change the pulse file. I suspected the latter but my experiments did not confirm it.
Is it possible/easy to honor task: mem='', cores='' for -q none approach that we are discussing here (I guess the answer is yes since we now can do it for task already)? If so, then what would be the advantage to use task over non-task execution, in the context of running on a conventional cluster with input and output defined (so re-execution will not have to rely on task signature)?
what would be the advantage to use task over non-task execution
In my case tasks are "independent" of SoS processes so my notebook server would be killed/closed with running tasks, and i can open the notebook again to see if the tasks are done.
This might not be important if you are willing to wait but in our cluster we are not allowed to execute anything on the head node so without task we have to either run nothing on the cluster, or run everything on the cluster, which is not what I wanted.
Thanks for clarifying it. Then for my applications it seems not using task while still able to submit to PBS is a better approach because there will be less overhead and hopefully more robust (which is the most crucial).
Another reason is resource management, as this ticket represents. A large workflow can consist of large and small steps and with varying requirements for resources. Tasks allow us to submit resource demanding jobs with different resource requirements to cluster, while executing less demanding steps locally. This might not be important for your workflows because you have more or less uniform tasks, but is important for mine.
Even more important might be interactive data analysis since I usually do not have a complete workflow at hand to run, rather a sequence of steps that need to be executed interactively. It is then essential for me to submit single steps to clusters....
I'd like to confirm the interface here for this ticket: if we specify
task: mem= ..., queue = None
and run with -r machine_name with corresponding setup in hosts.yml as a PBS queue + a template for job submissions, then it will simply wrap computations in substeps as PBS batch scripts and submit? Then without writing to ~/.sos/task folder how do we check for error messages -- now they are sos status but without task I assume they will be in stderr files?
-r works in a totally different way. It does not use task: mem=.... and its status cannot be monitored by sos status. All it does are
- Copy the script to remote host
- Generate a shell script from
workflow_template, withwalltimeetc passing from command line (e.g.sos run -r host walltime=01:00:00). - The shell script is submitted, and
.errand.outis as specified in the template. There is no.taskfile to capture.errand.outetc.
Thanks for clarifying. Question remains for 2: from the beginning of this ticket I was under the impression that we will try to utilize task to set the parameters. We had it before with using task but with queue=None so it doesnt submit task. That allows us to switch between task and non-task applications. I think it is natural to allow -r honor task. A big advantage is that trunk_size and trunk_workers are still relevant for -r without task. They can then be specified here and users can switch back and forth between the two modes of runs easily.
What this ticket talks about is that currently sos workers takes substeps regardless of the "size" of substeps. So if we are using 8 workers, 4 each on 2 hosts, one host might take 4 big substeps and die, and another one might take 4 small substeps and is more or less idle. The problem is that
- SoS do not know the "capacity" of workers (e.g. how much ram it has etc)
- SoS can know the "size" of the substep through
task, but this is meaningless because of 1. trunk_sizeetc are not important in-rmode andtrunk_size=1would be better because the "finer" trunks would allow better load balancing of workers.
Without 1, we cannot really prevent the cited problem by comparing "requested resource" (known) and "available resource" (unknown), but we can potentially do better load balancing. That is to say, we submit the same 8 substeps to 8 workers on 2 nodes, but we can try to spread large substeps to 2 nodes.
So if we are using 8 workers, 4 each on 2 hosts, one host might take 4 big substeps and die, and another one might take 4 small substeps and is more or less idle
This is understandable. But to my understanding, trunk_size and trunk_workers in the non-task context can be useful in specifying how many substeps goes into one file, and how are they going to be distributed to other nodes. I suppose it will boil down to submitting a PBS script with, eg,
Rscript /tmp/tmp1.R
Rscript /tmp/tmp2.R
...
Rscript /tmp/tmp{trunk_size}.R
and perhaps they will run in parallel in batches of 4, if we additionally set trunk_workers=4, or even cross nodes. These are basic PBS behavior not involving fine-scale resource allocations. Is that doable? I'm merely thinking of balanced , hundreds of substeps and the natural way to run them is to put many of them in one PBS job and still allow for commend level parallel execution.
trunk_size and trunk_workers in the non-task context can be useful in specifying how many substeps goes into one file,
You idea is trying to group small substeps so that all "execution unit" (not task) have roughly the same size. This would require user intervention and the execution of "big rocks" can lead to problems.
My idea is to identifying the large "execution unit" (big rocks) and the strategy is to spread them better among nodes/workers. Then the smaller substeps would become "sand" that can fill the cracks of each worker easily, leading to more balanced workload distribution.
Well, for now I was not even trying to balance the workload ... I think there was some more fundamental issues (or misunderstanding?) that needs to be addressed to. Suppose all substeps have the same workload. Then with trunk_size=1 it means one substep per job which will result in lots of substeps. I was referring to something naive, as multiple Rscript executions in a PBS file, instead of just one line of them. This "big rock" still consists of multiple explicit lines of commands and the total walltime will be the sum of their walltime. I assume homogeneous mem for all substeps but in principle mem can also be the max(mem) of all substeps. If some of the substeps failed for whatever reason then the next run will be able to regroup the failed ones and submit again.
It seems a natural behavior to me for getting a simple version to work. Am I missing something here? Of course beyond this point we can worry about balancing loads.
trunk_size is not relevant in this case.
For every substep, we have, for example, a single R-script. With task, it will be a task. With trunk_size, it will be a master task with multiple tasks, but each task (R-script) will still be executed separately, controlled by the master task executor.
Without task each substep (R script) is sent to a worker, and a worker starts a Rscript process to process the script. The difference here is that things happens in RAM and Network, and is much faster than task (on disk with extra processing). But at the end the day you are still running N Rscript commands to process N R scripts. (And this is why I said that tasks are suitable for large jobs so the overhead of tasks are negligible. trunk_size reduces cluster interaction, but does not reduce the "task" overhead for each substep.).
Therefore, in the case with a large number of small substeps, there is no problem with load balancing and it is much more efficient to run it with -r on cluster without task.
I see the distinction. But then for non-task cluster jobs with -r, how do you specify how many R scripts to go into one job submission? That's what I dont understand about the interface. I thought we can "abuse" task_size argument to achieve this.
BTW I'm now at the stage of of running large number of small substeps that I think would be a great opportunity to test this -r feature as is. But I want to make sure I get the interface configured correctly.
For -r, you only get one job submission for a single sos run command, which is likely a multi-node multi-core job that executes all substeps.
Yes, and that will lead to all the problems discussed in this ticket about resource distributions. I guess I'm proposing a mode of execution very similar to task but not using task. It only involves populating a PBS script with multiple R commands. I wonder what's the hurdle for that mechanism.
So you are basically proposing the use of tasks to execute subworkflows (#476). In that case you can
[work]
input: for_each=dict(i=range(10000))
R:
process {i}
[10]
task:
sos_run('work')
where work can execute a large amount of substeps without task burden.
This is not currently supported because subworkflows are complex stuff and you basically need to encapsulate the entire workflow and all variables in task, and the existing task_executor cannot handle multiple steps at all.
Okay then let's table the discussion for later. I hope you see my motivation here is to be able to submit jobs the same way as we currently have for task (multiple jobs not one job) which I like, but avoid the overhead of task.
Then a compromised solution would be
[work]
task:
input: for_each=dict(i=range(10000))
R:
process {i}
[10]
sos_run('work')
which basically sends the entire step as a task, with all the substeps. The amount of information to be encapsulated is still limited to the step, and the task_executor does not need such a dramatic change. In this case you are getting one task for a step, trunk_size does not make sense but trunk_workers might work.
Note that, however, whereas we can now run tasks at substep level and skip passed substeps, running the entire step as task will not be able to achieve this so any failed substep will lead to the failure of the entire step.