pandera
 pandera copied to clipboard
pandera copied to clipboard
write to YAML - support custom checks
In the pandera documentation it is mentioned that currently, only built-in Check methods are supported under the checks key when writing schema to yaml.
When I execute code below, yaml schema will nicely show the checks key even for the custom check, but unfortunately only for the last custom check if the same custom check is included more than once with different inputs. As I need to build some reporting capabilities on top of pandera it would be super useful to have all the custom checks included, otherwise it will be difficult to track the validated schema.
Just wanted to share that I would find this a very useful addition in case this feature is not yet on the roadmap,
import pandera.extensions as extensions
import pandera as pa
import pandas as pd
@extensions.register_check_method(
statistics=["columns_to_sum", "target_column"], supported_types=pd.DataFrame,
)
def equals_colsum(df, *, columns_to_sum, target_column):
return df[columns_to_sum].sum(axis=1) == df[target_column]
df= pd.DataFrame(
{
"a": [1.0, 2.0, 3.0],
"b": [4.0, 2.0, 6.0],
"c": [5.0, 4.0, 9.0],
"d": [6.0, 7.0, 8.0],
}
)
schema = pa.DataFrameSchema(
checks=[pa.Check.equals_colsum(["a", "b"], "c"),
pa.Check.equals_colsum(["a", "b"], "d")]
)
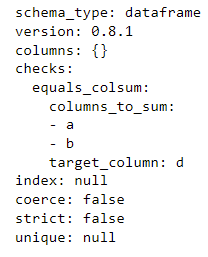
yaml_schema = schema.to_yaml()
print(yaml_schema)
hi @benjaminbluhm this feature makes sense to have!
The original assumption of the checks key in the yaml format was that, generally speaking, the built-in checks are unique, but it's clear this was the wrong assumption :)
So the problem here is that, in the yaml file, the data under the checks key is a mapping of check names to their statistics (in this case equals_colsum maps to its statistics columns_to_sum and target_column.
Only the last one is being serialized since it overrides the previous one.
checks=[pa.Check.equals_colsum(["a", "b"], "c"), # the first one
pa.Check.equals_colsum(["a", "b"], "d")] # is overriden ^^
So this poses the challenge: how to serialize multiple built-in or registered checks?
Solution 1: Serialize checks as a list instead of a mapping
checks:
- equals_colsum:
columns_to_sum: ["a", "b"]
target_column: "c"
- equals_colsum:
columns_to_sum: ["a", "b"]
target_column: "d"
Solution 2: Add an index identifier for checks with the same key
checks:
equals_colsum0:
columns_to_sum: ["a", "b"]
target_column: "c"
equals_colsum1:
columns_to_sum: ["a", "b"]
target_column: "d"
I sort of like solution (1) better, as it reflects the actual list of checks that a user specifies when defining a DataFrameSchema. The con of (1) is that it changes the yaml format data structure... which means we'd need to add complexity to the codebase to handle yaml schemas for different versions of pandera. I think this is fine, since I'd anticipate the yaml schema would need to be updated in the future anyway.
What do you think?
Just added the "help wanted" tag here, let me know if you want to contribute to this feature! @benjaminbluhm
In the mean time, a workaround here would be to collapse the multiple checks into a single one. I generally don't recommend this, since the error reporting wouldn't be able to tell you which target column caused the error, but to enable your use case it makes sense:
# WARNING: NOT TESTED!
@extensions.register_check_method(
statistics=["columns_to_sum", "target_columns"], supported_types=pd.DataFrame,
)
def equals_colsum(df, *, columns_to_sum, target_columns):
results = []
for target_column in target_columns:
results.append(df[columns_to_sum].sum(axis=1) == df[target_column])
return pd.concat(results, axis="columns").all(axis="columns")
Hi @cosmicBboy, thanks for proposed workaround!
Regarding proposed solutions, I would also favor solution (1) as it reflects the actual function name specified by the user.
Can you point towards the code parts / sketch the adjustments that would need to be implemented for this change?
hi @benjaminbluhm, sorry for the delay in responding!
So the main function to look at is _serialize_dataframe_stats
Right now it outputs a dict where keys are check names and values are a dict containing all the check metadata, so that should output a list.
You may also need to change parse_checks, which similarly returns a dict of check names to Check objects. This'll also need to output a list of checks.
For backwards compatibility, _deserialize_schema and _deserialize_check_stats need to handle the case for parsing the dict-based checks and raising a warning to re-serialize those schemas to the new format.
Let me know if you have the capacity to help with this change!