yolov5
 yolov5 copied to clipboard
yolov5 copied to clipboard
feat: Adds mlflow run logging
Saw https://github.com/ultralytics/yolov5/issues/4231 and https://github.com/ultralytics/yolov5/pull/7840 and figured I'd make a PR to add some rudimentary logging for Mlflow that I used for work.
- Assumes that mlflow and experiment is setup by user
- Logger creates a run and tracks params, metrics, and artifacts
To make use of this code:
- Run Mlflow ui
pip install mlflow==1.26.1
mlflow ui
- Run training code. eg.
python train.py --img 640 --batch 16 --epochs 3 --data coco128.yaml --weights yolov5n.pt --cache cache --save-period 1
This will create a run and log all params, metrics, artifacts, and log the model to the run. If no experiment is set, everything will be logged to the default experiment. Below is an example of a run:
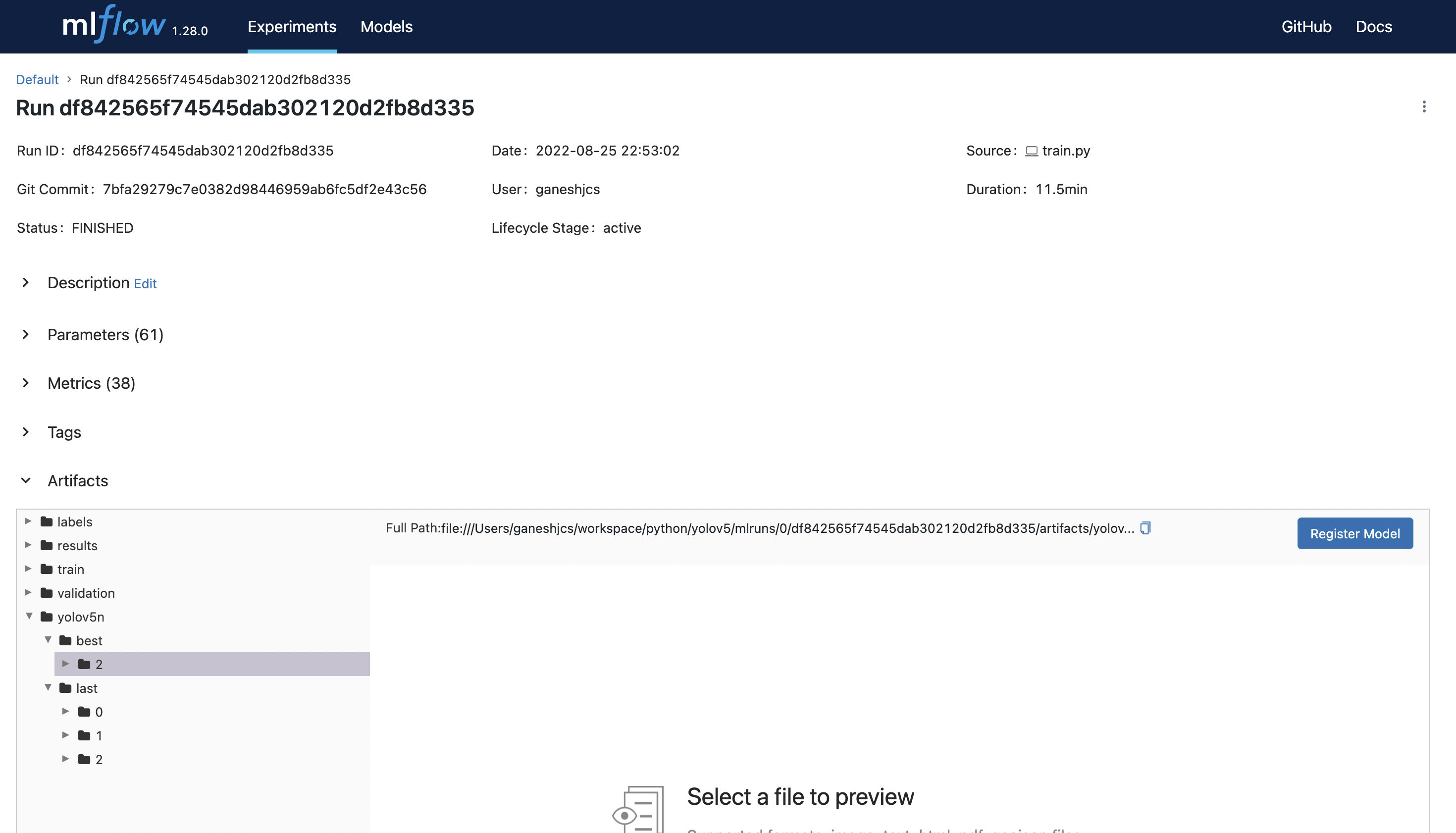
Alternatively, users can also run the code as an Mlflow Project. For that users would have to create their own MLproject file, specify the backend-config and conda.yaml and run the project as
mlflow run yolov5 -p {param1} --experiment-name {experiment-name} -b {databricks or local} --backend-config {set only if running on databricks}
and all of this will still work.
@glenn-jocher @AyushExel hi there! was wondering if this PR could be reviewed? TIA!
@ElefHead We currently have other higher priority tasks. We'll probably come back to this after 2 releases
Hi Sir, I think that, we must also add the mlflow part In the utils/loggers/init.py/ (def on_pretrain_routine_end(self):) method.
I think that, we must also add the mlflow part In the utils/loggers/init.py/ (def on_pretrain_routine_end(self):) method.
@fcan26 Thanks for the review, I have added those as well as the post train batch end artifacts and the validation batch artifacts. Updated the screenshot on the description.
@ElefHead Hi ElefHead, I'm very interested in your integration of mlflow into yolov5, I'm also working on yolov5 and mlflow recently.
I referenced this page, but the content of this page is a bit out of date. https://medium.com/codex/setting-up-mlflow-for-ultralytics-yolov5-1380b5f8cac5
At present, I have successfully integrated mlflow with yolov5, but the parameters and weights that can be tracked are not as rich as yours.
I set up the UI page of mlflow through the following mlflow command. I can specify the URL and Port number by myself:
mlflow server
--backend-store-uri sqlite:///mlflow.db
--default-artifact-root ./mlruns
--host 0.0.0.0 --port 8000 &
A s you said, "mlflow ui" will be automatically set up at "http://127.0.0.1:5000/", how can I specify the URL and Port number by myself?
@jayer95 You can do an export MLFLOW_TRACKING_URI=http://0.0.0.0:8000.
I haven't used mlflow server a lot because the last time I tried it out, I saw weird behavior. Maybe you can help me out.
@ElefHead Thank you, I use "export MLFLOW_TRACKING_URI=http://0.0.0.0:8000" to get the correct mlflow tracking url.
What kind of weird behaviors are you seeing?
I found that mlflow 1.27 is not as easy to use as 1.26.1.
This is my usage steps:
git clone https://github.com/ElefHead/yolov5.git (yours)
git checkout dev/mlflow-run-tracking
cd yolov5
mlflow server --backend-store-uri sqlite:///mlflow.db --default-artifact-root ./mlruns --host 0.0.0.0 --port 8000 &
export MLFLOW_TRACKING_URI="http://0.0.0.0:8000"
mlflow run . --env-manager local --experiment-name ultralytics/yolov5 -P epochs=3
Check url: http://0.0.0.0:8000
[MLproject]
name: ultralytics/yolov5
conda_env: mlflow.yml
entry_points:
main:
parameters:
img_size: {type: int, default: 640}
batch_size: {type: int, default: 16}
epochs: {type: int, default: 300}
data_file: {type: string, default: "./data/coco128.yaml"}
cfg_file: {type: string, default: "./models/yolov5s.yaml"}
weights_file: {type: string, default: "./yolov5s.pt"}
command: |
python train.py
--img {img_size}
--batch {batch_size}
--epochs {epochs}
--data {data_file}
--cfg {cfg_file}
--weights {weights_file}
So, mlflow run <local project> is broken in mlflow 1.27.0, the fix will be in next release.
Nothing major or worrying, I remember having to handle params differently - but I think the code here should all work fine. Mostly, just let me know if it doesn't work for some reason and I can try fixing it. :)
@ElefHead I know why. In the latest version 1.27, he asked us to step back to one level above yolov5 and execute:
mlflow run \#yolov5 --env-manager local --experiment-name ultralytics/yolov5 -P epochs=3
My operating system is Ubuntu, the official documents of 1.27 have instructions, I need to go to the upper directory of the project, and add "#" in front of the folder name of the project, because "#" is a symbol, so on Ubuntu, it must be add slash.
Yeah, it's because if the local folder is a git repo, it got treated as a git Uri.
https://github.com/mlflow/mlflow/issues/6194
@ElefHead
Hi, I don't know why, I used my own data (unofficial coco128) for training and got stuck at the first epoch, as shown below,
 I use "ctrl+c" to force close the training, the memory occupied by the gpu is not released, and htop can't see the pid, maybe you can help me out.
I use "ctrl+c" to force close the training, the memory occupied by the gpu is not released, and htop can't see the pid, maybe you can help me out.
hmm, @jayer95 - unfortunately idk how to recreate your exact experiment, but I could run an mlflow server the same way you run it and try out a bunch of runs and see if I see the same problem (I'd have to do it over the weekend). Technically, the mlflow logging part should do nothing with the GPU (till the end at least where the best model is reloaded to log to mlflow) or block none of these processes, unless there's something happening with the server running on the same instance.
@ElefHead I'll do a close experiment to try and find the problem, and at the same time, I'll prepare a reproducible dataset. I use "mlflow run" to start training and track mlflow logs, when I use the yolov5 official coco128 dataset, everything works fine. I'm thinking if it's because of my "mlflow run" command error.
I'll do a close experiment to try and find the problem, and at the same time, I'll prepare a reproducible dataset. I use "mlflow run" to start training and track mlflow logs, when I use the yolov5 official coco128 dataset, everything works fine. I'm thinking if it's because of my "mlflow run" command error.
Hi! I'm also working on the @ElefHead repo and trying to add a database. If you pull the repo directly and then run it, the project itself gives automatic uri and mlflow ui works. If you have integrated the database, you can try this command, mlflow ui --backend-store-uri sqlite:///mlruns.db My database integration is not finished yet, I ran a small project with this command.
- @jayer95 Also don't forget to add this command to main part of train.py mlflow.set_tracking_uri("sqlite:///mlruns.db")
@fcan26
Hi,
Thanks for your suggestion, about add this command to main part of train.py
mlflow.set_tracking_uri("sqlite:///mlruns.db")
What can it be used to do?
@fcan26 Hi, Thanks for your suggestion, about add this command to main part of train.py
mlflow.set_tracking_uri("sqlite:///mlruns.db")What can it be used to do? to connect database
when i followed your path i got this error :( mlflow run #yolov5 --env-manager local --experiment-name ultralytics/yolov5 -P epochs=3 2022/08/03 08:42:25 INFO mlflow.projects: 'ultralytics/yolov5' does not exist. Creating a new experiment 2022/08/03 08:42:25 ERROR mlflow.cli: === Could not find subdirectory yolov5 of ===
@ElefHead I found a small bugs today, when the weights I set during training is empty, it means that I do not use the pre-trained model, but let the model start training from scratch.
As follows:
mlflow run . \
--env-manager local \
--experiment-name ultralytics/yolov5 \
-P epochs=3 \
-P weights_file=''
When the training is complete, it will get the error:
Fusing layers...
YOLOv5s summary: 213 layers, 7225885 parameters, 0 gradients, 16.4 GFLOPs
Adding AutoShape...
Traceback (most recent call last):
File "train.py", line 642, in <module>
main(opt)
File "train.py", line 537, in main
train(opt.hyp, opt, device, callbacks)
File "train.py", line 442, in train
callbacks.run('on_train_end', last, best, plots, epoch, results)
File "/home/gvsai/workspace/mlflow/yolov5/utils/callbacks.py", line 71, in run
logger['callback'](*args, **kwargs)
File "/home/gvsai/workspace/mlflow/yolov5/utils/loggers/__init__.py", line 219, in on_train_end
self.mlflow.log_model(best)
File "/home/gvsai/workspace/mlflow/yolov5/utils/loggers/mlflow/mlflow_utils.py", line 85, in log_model
self.weights.unlink()
File "/home/gvsai/anaconda3/envs/mlflow/lib/python3.8/pathlib.py", line 1325, in unlink
self._accessor.unlink(self)
IsADirectoryError: [Errno 21] Is a directory: '.'
2022/08/03 17:54:20 ERROR mlflow.cli: === Run (ID '05158d98036e46c6a167c25badb23274') failed ===
https://github.com/ElefHead/yolov5/blob/dev/mlflow-run-tracking/utils/loggers/mlflow/mlflow_utils.py#L84
I modified it to:
if self.weights.exists() and self.weights.is_file() and (self.weights.parent.resolve() == ROOT.resolve()):
Problem solved, please review and refer.
@jayer95 Which part did you integrate TRACKING_URI="http://0.0.0.0:8000" into? and did you use mlflow.client ?
@fcan26 Hi, Thanks for your suggestion, about add this command to main part of train.py
mlflow.set_tracking_uri("sqlite:///mlruns.db")What can it be used to do? to connect database
Thank you for your explanation, I will give it a try, I have not added this line of code before. It seems that mlflow can automatically connect with the database through the following command:
mlflow server \
--backend-store-uri sqlite:///mlflow.db \
--default-artifact-root ./mlruns \
--host 0.0.0.0 --port 8000 &
export MLFLOW_TRACKING_URI="http://0.0.0.0:8000"
@fcan26 Hi, Thanks for your suggestion, about add this command to main part of train.py
mlflow.set_tracking_uri("sqlite:///mlruns.db")What can it be used to do? to connect databaseThank you for your explanation, I will give it a try, I have not added this line of code before. It seems that mlflow can automatically connect with the database through the following command:
mlflow server \ --backend-store-uri sqlite:///mlflow.db \ --default-artifact-root ./mlruns \ --host 0.0.0.0 --port 8000 &
export MLFLOW_TRACKING_URI="http://0.0.0.0:8000"
Thank u!
when i followed your path i got this error :( mlflow run #yolov5 --env-manager local --experiment-name ultralytics/yolov5 -P epochs=3 2022/08/03 08:42:25 INFO mlflow.projects: 'ultralytics/yolov5' does not exist. Creating a new experiment 2022/08/03 08:42:25 ERROR mlflow.cli: === Could not find subdirectory yolov5 of ===
This seems to be a bug. https://github.com/mlflow/mlflow/issues/6194
Which version of mlflow did you install? If it is 1.27, please "cd .." under the folder of yolov5, go back to the previous layer, and:
mlflow run \#yolov5 \
--env-manager local \
--experiment-name ultralytics/yolov5 \
-P epochs=3
@jayer95 Which part did you integrate TRACKING_URI="http://0.0.0.0:8000" into? and did you use mlflow.client ?
I entered the following commands manually:
export MLFLOW_TRACKING_URI="http://0.0.0.0:8000"
No, I didn't, I just started working on mlflow. Thanks for discussing with me!
@jayer95 Which part did you integrate TRACKING_URI="http://0.0.0.0:8000" into? and did you use mlflow.client ?
I entered the following commands manually:
export MLFLOW_TRACKING_URI="http://0.0.0.0:8000"No, I didn't, I just started working on mlflow. Thanks for discussing with me! Its my pleasure! I also thank you. I hope we can run the project properly in local with database integration.
@ElefHead I reset the server with the following command:
mlflow server \
--backend-store-uri sqlite:///mlflow.db \
--artifacts-destination s3://mlflowbucket \
--serve-artifacts \
--host 0.0.0.0 \
--port 8000
Now I can upload the "mlruns" to aws s3.
@ElefHead Currently, mlflow branch is working well. I found that the problem mentioned earlier about GPU memory leaks may be related to my 3090 under high load for a long time. When I restarted the computer, the problem was solved. @fcan26 And you?