yolov5
 yolov5 copied to clipboard
yolov5 copied to clipboard
Hyperparameter Evolution
📚 This guide explains hyperparameter evolution for YOLOv5 🚀. Hyperparameter evolution is a method of Hyperparameter Optimization using a Genetic Algorithm (GA) for optimization. UPDATED 28 March 2023.
Hyperparameters in ML control various aspects of training, and finding optimal values for them can be a challenge. Traditional methods like grid searches can quickly become intractable due to 1) the high dimensional search space 2) unknown correlations among the dimensions, and 3) expensive nature of evaluating the fitness at each point, making GA a suitable candidate for hyperparameter searches.
Before You Start
Clone repo and install requirements.txt in a Python>=3.7.0 environment, including PyTorch>=1.7. Models and datasets download automatically from the latest YOLOv5 release.
git clone https://github.com/ultralytics/yolov5 # clone
cd yolov5
pip install -r requirements.txt # install
1. Initialize Hyperparameters
YOLOv5 has about 30 hyperparameters used for various training settings. These are defined in *.yaml files in the /data directory. Better initial guesses will produce better final results, so it is important to initialize these values properly before evolving. If in doubt, simply use the default values, which are optimized for YOLOv5 COCO training from scratch.
https://github.com/ultralytics/yolov5/blob/2da2466168116a9fa81f4acab744dc9fe8f90cac/data/hyps/hyp.scratch-low.yaml#L2-L34
2. Define Fitness
Fitness is the value we seek to maximize. In YOLOv5 we define a default fitness function as a weighted combination of metrics: [email protected] contributes 10% of the weight and [email protected]:0.95 contributes the remaining 90%, with Precision P and Recall R absent. You may adjust these as you see fit or use the default fitness definition (recommended).
https://github.com/ultralytics/yolov5/blob/4103ce9ad0393cc27f6c80457894ad7be0cb1f0d/utils/metrics.py#L12-L16
3. Evolve
Evolution is performed about a base scenario which we seek to improve upon. The base scenario in this example is finetuning COCO128 for 10 epochs using pretrained YOLOv5s. The base scenario training command is:
python train.py --epochs 10 --data coco128.yaml --weights yolov5s.pt --cache
To evolve hyperparameters specific to this scenario, starting from our initial values defined in Section 1., and maximizing the fitness defined in Section 2., append --evolve:
# Single-GPU
python train.py --epochs 10 --data coco128.yaml --weights yolov5s.pt --cache --evolve
# Multi-GPU
for i in 0 1 2 3 4 5 6 7; do
sleep $(expr 30 \* $i) && # 30-second delay (optional)
echo 'Starting GPU '$i'...' &&
nohup python train.py --epochs 10 --data coco128.yaml --weights yolov5s.pt --cache --device $i --evolve > evolve_gpu_$i.log &
done
# Multi-GPU bash-while (not recommended)
for i in 0 1 2 3 4 5 6 7; do
sleep $(expr 30 \* $i) && # 30-second delay (optional)
echo 'Starting GPU '$i'...' &&
"$(while true; do nohup python train.py... --device $i --evolve 1 > evolve_gpu_$i.log; done)" &
done
The default evolution settings will run the base scenario 300 times, i.e. for 300 generations. You can modify generations via the --evolve argument, i.e. python train.py --evolve 1000.
https://github.com/ultralytics/yolov5/blob/6a3ee7cf03efb17fbffde0e68b1a854e80fe3213/train.py#L608
The main genetic operators are crossover and mutation. In this work mutation is used, with a 80% probability and a 0.04 variance to create new offspring based on a combination of the best parents from all previous generations. Results are logged to runs/evolve/exp/evolve.csv, and the highest fitness offspring is saved every generation as runs/evolve/hyp_evolved.yaml:
# YOLOv5 Hyperparameter Evolution Results
# Best generation: 287
# Last generation: 300
# metrics/precision, metrics/recall, metrics/mAP_0.5, metrics/mAP_0.5:0.95, val/box_loss, val/obj_loss, val/cls_loss
# 0.54634, 0.55625, 0.58201, 0.33665, 0.056451, 0.042892, 0.013441
lr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3)
lrf: 0.2 # final OneCycleLR learning rate (lr0 * lrf)
momentum: 0.937 # SGD momentum/Adam beta1
weight_decay: 0.0005 # optimizer weight decay 5e-4
warmup_epochs: 3.0 # warmup epochs (fractions ok)
warmup_momentum: 0.8 # warmup initial momentum
warmup_bias_lr: 0.1 # warmup initial bias lr
box: 0.05 # box loss gain
cls: 0.5 # cls loss gain
cls_pw: 1.0 # cls BCELoss positive_weight
obj: 1.0 # obj loss gain (scale with pixels)
obj_pw: 1.0 # obj BCELoss positive_weight
iou_t: 0.20 # IoU training threshold
anchor_t: 4.0 # anchor-multiple threshold
# anchors: 3 # anchors per output layer (0 to ignore)
fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
hsv_h: 0.015 # image HSV-Hue augmentation (fraction)
hsv_s: 0.7 # image HSV-Saturation augmentation (fraction)
hsv_v: 0.4 # image HSV-Value augmentation (fraction)
degrees: 0.0 # image rotation (+/- deg)
translate: 0.1 # image translation (+/- fraction)
scale: 0.5 # image scale (+/- gain)
shear: 0.0 # image shear (+/- deg)
perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
flipud: 0.0 # image flip up-down (probability)
fliplr: 0.5 # image flip left-right (probability)
mosaic: 1.0 # image mosaic (probability)
mixup: 0.0 # image mixup (probability)
copy_paste: 0.0 # segment copy-paste (probability)
We recommend a minimum of 300 generations of evolution for best results. Note that evolution is generally expensive and time consuming, as the base scenario is trained hundreds of times, possibly requiring hundreds or thousands of GPU hours.
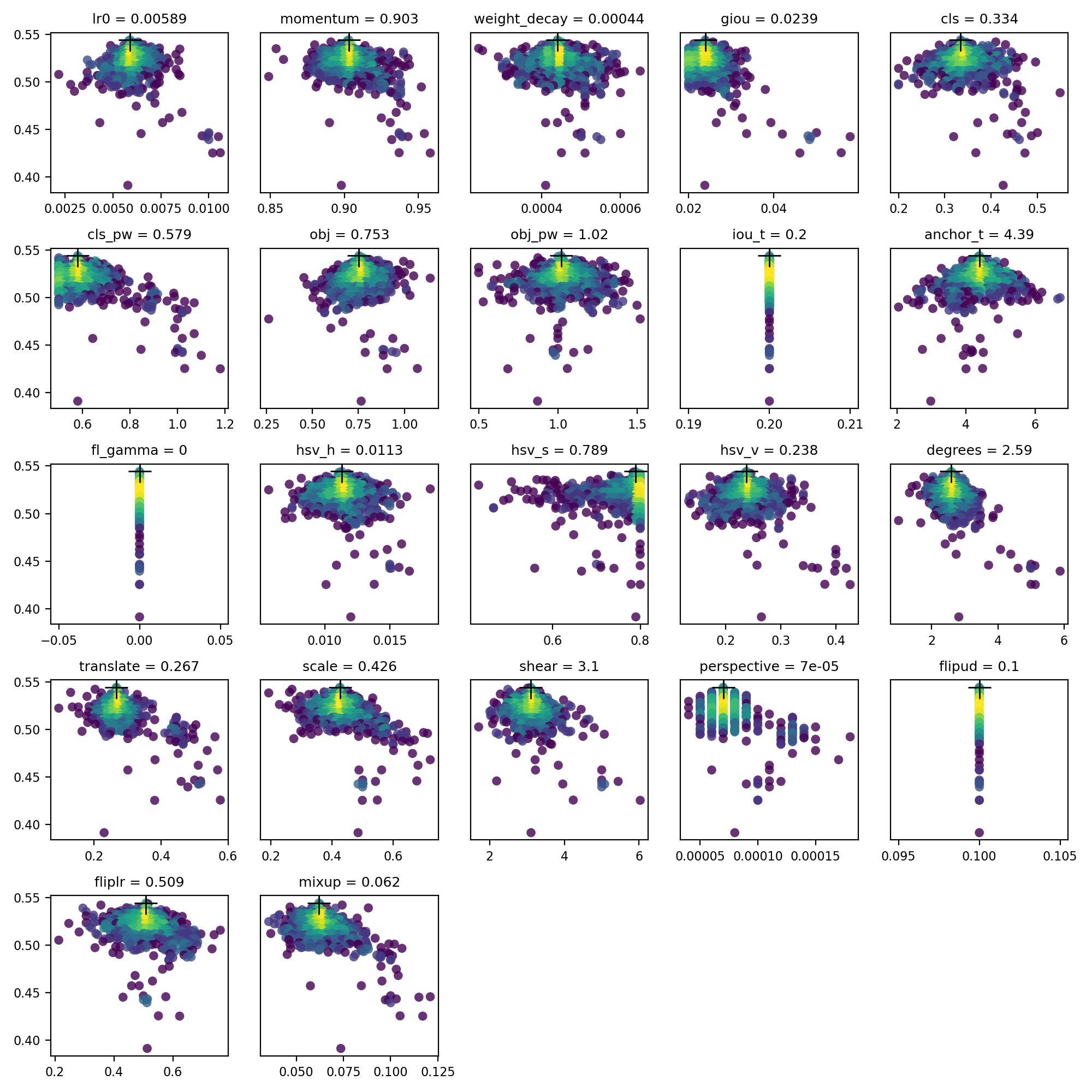
4. Visualize
evolve.csv is plotted as evolve.png by utils.plots.plot_evolve() after evolution finishes with one subplot per hyperparameter showing fitness (y axis) vs hyperparameter values (x axis). Yellow indicates higher concentrations. Vertical distributions indicate that a parameter has been disabled and does not mutate. This is user selectable in the meta dictionary in train.py, and is useful for fixing parameters and preventing them from evolving.
Environments
YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including CUDA/CUDNN, Python and PyTorch preinstalled):
- Notebooks with free GPU:



- Google Cloud Deep Learning VM. See GCP Quickstart Guide
- Amazon Deep Learning AMI. See AWS Quickstart Guide
- Docker Image. See Docker Quickstart Guide

Status
![]()
If this badge is green, all YOLOv5 GitHub Actions Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 training, validation, inference, export and benchmarks on MacOS, Windows, and Ubuntu every 24 hours and on every commit.
@glenn-jocher I trained with --evolve, --nosave hyper parameter but i didnt receive last weights in runs folder.
@buimanhlinh96 , evolve is will find the best hyper params after 10 epoch (if you didn't change it), you will want to take what was found to be the best and do a full training!
@glenn-jocher did you find 10 epoch to give a decent indication about a full training? Is it whats the most cost efficient from what you have seen ?
@Ownmarc there is no fixed evolve scenario. You create the scenario and then just append --evolve to it and let it work. If you want to evolve full training, well, you know what to do. Any assumption about results from shorter training correlating with results of longer trainings is up to you.
And did you find any correlations between model sizes ? Will some "best" hyp on yolov5s also do a good job on yolov5x or would it require its own evolve ?
@Ownmarc I have not evolved per model, but it's fairly obvious that whatever works best for a 7M parameter model will not be identical to whatever works best for a 90M parameter model.
@glenn-jocher , I believe the V3.0 release has changed in the train.py. I didn't find the hyp at L18-43 in train.py . Instead , I found the
data/hyp.scratch.yaml
file with hyp set. so, if I want to change the hyp to training , rewrite the hyp.scratch.yaml file is OK, right?
.
@Frank1126lin yes that's correct:
hyp.scratch.yamlwill be automatically used by defaulthyp.custom.yamlcan be force-selected bypython train.py --hyp hyp.custom.yaml
https://github.com/ultralytics/yolov5/blob/c2523be634a94da2b1b2a43c11b25827a0de990d/train.py#L445
@buimanhlinh96 ,hello, did you find the best hyp result after training with --evolve?
Hello, I run : python train.py --epochs 10 --data coco128.yaml --cfg yolov5s.yaml --weights yolov5s.pt --cache --evolve
and got an error like:
Namespace(adam=False, batch_size=16, bucket='', cache_images=True, cfg='./models/yolov5s.yaml', data='./data/coco128.yaml', device='', epochs=3, evolve=True, global_rank=-1, hyp='data/hyp.scratch.yaml', image_weights=False, img_size=[640, 640], local_rank=-1, logdir='runs/', multi_scale=False, name='', noautoanchor=False, nosave=False, notest=False, rect=False, resume=False, single_cls=False, sync_bn=False, total_batch_size=16, weights='', workers=8, world_size=1)
Traceback (most recent call last):
File "train.py", line 525, in
Hello, I run : python train.py --epochs 10 --data coco128.yaml --cfg yolov5s.yaml --weights yolov5s.pt --cache --evolve
and got an error like:
Namespace(adam=False, batch_size=16, bucket='', cache_images=True, cfg='./models/yolov5s.yaml', data='./data/coco128.yaml', device='', epochs=3, evolve=True, global_rank=-1, hyp='data/hyp.scratch.yaml', image_weights=False, img_size=[640, 640], local_rank=-1, logdir='runs/', multi_scale=False, name='', noautoanchor=False, nosave=False, notest=False, rect=False, resume=False, single_cls=False, sync_bn=False, total_batch_size=16, weights='', workers=8, world_size=1) Traceback (most recent call last): File "train.py", line 525, in hyp[k] = max(hyp[k], v[1]) # lower limit KeyError: 'anchors'
I also have same problem.
Hello, I run : python train.py --epochs 10 --data coco128.yaml --cfg yolov5s.yaml --weights yolov5s.pt --cache --evolve and got an error like: Namespace(adam=False, batch_size=16, bucket='', cache_images=True, cfg='./models/yolov5s.yaml', data='./data/coco128.yaml', device='', epochs=3, evolve=True, global_rank=-1, hyp='data/hyp.scratch.yaml', image_weights=False, img_size=[640, 640], local_rank=-1, logdir='runs/', multi_scale=False, name='', noautoanchor=False, nosave=False, notest=False, rect=False, resume=False, single_cls=False, sync_bn=False, total_batch_size=16, weights='', workers=8, world_size=1) Traceback (most recent call last): File "train.py", line 525, in hyp[k] = max(hyp[k], v[1]) # lower limit KeyError: 'anchors'
I also have same problem.
remove ‘anchor’ line will slove the problem
Hello, I run : python train.py --epochs 10 --data coco128.yaml --cfg yolov5s.yaml --weights yolov5s.pt --cache --evolve and got an error like: Namespace(adam=False, batch_size=16, bucket='', cache_images=True, cfg='./models/yolov5s.yaml', data='./data/coco128.yaml', device='', epochs=3, evolve=True, global_rank=-1, hyp='data/hyp.scratch.yaml', image_weights=False, img_size=[640, 640], local_rank=-1, logdir='runs/', multi_scale=False, name='', noautoanchor=False, nosave=False, notest=False, rect=False, resume=False, single_cls=False, sync_bn=False, total_batch_size=16, weights='', workers=8, world_size=1) Traceback (most recent call last): File "train.py", line 525, in hyp[k] = max(hyp[k], v[1]) # lower limit KeyError: 'anchors'
I also have same problem.
remove ‘anchor’ line will slove the problem
Thanks for helping. Could you explain more ? Which anchor line (in training or yaml)?
Removed this line and worked, But I need some explanation. Thanks again
Constrain to limits
for k, v in meta.items():
hyp[k] = max(hyp[k], v[1]) # lower limit
hyp[k] = min(hyp[k], v[2]) # upper limit
hyp[k] = round(hyp[k], 5) # significant digits
Hello, I run : python train.py --epochs 10 --data coco128.yaml --cfg yolov5s.yaml --weights yolov5s.pt --cache --evolve and got an error like: Namespace(adam=False, batch_size=16, bucket='', cache_images=True, cfg='./models/yolov5s.yaml', data='./data/coco128.yaml', device='', epochs=3, evolve=True, global_rank=-1, hyp='data/hyp.scratch.yaml', image_weights=False, img_size=[640, 640], local_rank=-1, logdir='runs/', multi_scale=False, name='', noautoanchor=False, nosave=False, notest=False, rect=False, resume=False, single_cls=False, sync_bn=False, total_batch_size=16, weights='', workers=8, world_size=1) Traceback (most recent call last): File "train.py", line 525, in hyp[k] = max(hyp[k], v[1]) # lower limit KeyError: 'anchors'
I also have same problem.
remove ‘anchor’ line will slove the problem
Thanks for helping. Could you explain more ? Which anchor line (in training or yaml)?
Removed this line and worked, But I need some explanation. Thanks again
Constrain to limits
for k, v in meta.items(): hyp[k] = max(hyp[k], v[1]) # lower limit hyp[k] = min(hyp[k], v[2]) # upper limit hyp[k] = round(hyp[k], 5) # significant digits
line475 in train.py: 'iou_t': (0, 0.1, 0.7), # IoU training threshold 'anchor_t': (1, 2.0, 8.0), # anchor-multiple threshold #'anchors': (2, 2.0, 10.0), # anchors per output grid (0 to ignore) 'fl_gamma': (0, 0.0, 2.0), # focal loss gamma (efficientDet default gamma=1.5) 'hsv_h': (1, 0.0, 0.1), # image HSV-Hue augmentation (fraction)
Hello, I run : python train.py --epochs 10 --data coco128.yaml --cfg yolov5s.yaml --weights yolov5s.pt --cache --evolve and got an error like: Namespace(adam=False, batch_size=16, bucket='', cache_images=True, cfg='./models/yolov5s.yaml', data='./data/coco128.yaml', device='', epochs=3, evolve=True, global_rank=-1, hyp='data/hyp.scratch.yaml', image_weights=False, img_size=[640, 640], local_rank=-1, logdir='runs/', multi_scale=False, name='', noautoanchor=False, nosave=False, notest=False, rect=False, resume=False, single_cls=False, sync_bn=False, total_batch_size=16, weights='', workers=8, world_size=1) Traceback (most recent call last): File "train.py", line 525, in hyp[k] = max(hyp[k], v[1]) # lower limit KeyError: 'anchors'
I also have same problem.
remove ‘anchor’ line will slove the problem
Thanks for helping. Could you explain more ? Which anchor line (in training or yaml)?
Removed this line and worked, But I need some explanation. Thanks again
Constrain to limits
for k, v in meta.items(): hyp[k] = max(hyp[k], v[1]) # lower limit hyp[k] = min(hyp[k], v[2]) # upper limit hyp[k] = round(hyp[k], 5) # significant digitsline475 in train.py: 'iou_t': (0, 0.1, 0.7), # IoU training threshold 'anchor_t': (1, 2.0, 8.0), # anchor-multiple threshold #'anchors': (2, 2.0, 10.0), # anchors per output grid (0 to ignore) 'fl_gamma': (0, 0.0, 2.0), # focal loss gamma (efficientDet default gamma=1.5) 'hsv_h': (1, 0.0, 0.1), # image HSV-Hue augmentation (fraction)
Many Thanks...
#'anchors
Is commenting out anchors line will affect the hyper parameters?
@Samjith888 autoanchor will create new anchors if a value is found for hyp['anchors'], overriding any anchor information you specify in your model.yaml. i.e. you can set anchors: 5 to force autoanchor to create 5 new anchors per output layer, replacing the existing anchors. Hyperparameter evolution will evolve you an optimal number of anchors using this parameter.
@glenn-jocher You mean that if you comment out ['anchors'] in the 'hyp.scratch.yaml' file, the autoanchor will not work.Will yolov5_master produce anchors based on the value of my model.yaml ['anchors']?
If we do not comment the ['anchors'] in the 'hyp.scratch.yaml' file, will autoanchor produce the specified number of anchors on each Detect layer?
@xinxin342 if a nonzero anchor hyperparameter is found, existing anchor information will be deleted and new anchors will be force-autocomputed.
Is there an argument to limit the maximum number of object detection per frame?
@Sergey-sib your question is not related to hyperparameter evolution. https://github.com/ultralytics/yolov5/blob/0fda95aaf4e74db6505a343b8d2162782f4ab444/utils/general.py#L610
Hi @glenn-jocher The command: for i in 0 1 2 3; do nohup python train.py --epochs 10 --data coco128.yaml --weights yolov5s.pt --cache --evolve --device $i & done Seems that for multi-gpu evolution, it just repeat same progress in 4 GPUs with same parameters.
For example, I want to choose a best learning rate from the range of (0.1, 0.5), and the generations is 200. My understanding is that it will try 200 different lr to find a best one. Right? So for multi-gpu evolution, if use the command for i in 0 1 2 3; do nohup python train.py --epochs 10 --data coco128.yaml --weights yolov5s.pt --cache --evolve --device $i & done It seems just repeat it four times? I think it should be something like that each gpu trys 50 different lr for the range of (0.1,0.2) (0.2,0.3) (0.3,0.4) and (0.4,0.5).
Please correct me if my understanding is not right. Thanks.
@cxzhou95 the tutorial commands are correct. The multi-GPU tutorial command instructs four GPUs to evolve 300 generations each, reading and writing to a common evolve.txt. If not stopped prematurely this will evolve 1200 generations on all hyperparameters.
I see. Thanks a lot!
Glenn Jocher [email protected]于2020年10月25日 周日18:20写道:
@cxzhou95 https://github.com/cxzhou95 the tutorial commands are correct. The multi-GPU tutorial command instructs four GPUs to evolve 300 generations each, reading and writing to a common evolve.txt. If not stopped prematurely this will evolve 1200 generations on all hyperparameters.
— You are receiving this because you were mentioned. Reply to this email directly, view it on GitHub https://docs.ultralytics.com/yolov5/tutorials/hyperparameter_evolution#issuecomment-716123602, or unsubscribe https://github.com/notifications/unsubscribe-auth/AIHI4L5WNWEQ4ZGVRPOW2EDSMP3WVANCNFSM4PSWHVPQ .
how to decide the hyperparameter of yolov5s 、 the hyperparameter of yolov5m、 the hyperparameter of yolov5l? they are setting with the same hyperparameter?
@alicera hyperparameters are evolved on YOLOv5m and then used across all models.
hellow,my command is python train.py --epochs 10 --data coco128.yaml --weights yolov5s.pt --cache --evolve
Does that mean I will evolve 10 * 300 times?
Does every epochs evolve 300 times?
Or did it evolve 300 times in these 10 epochs?
thank you so much.
@python-faker --evolve evolves the base train.py command for 300 generations. The base command is irrelevant.
@glenn-jocher I am a little confused about evolve, is it used for training or just find the hyperparameters by train a few epochs and then use the hyp found to retrain? Thanks.