yolov5
 yolov5 copied to clipboard
yolov5 copied to clipboard
Multi-GPU instance segmentation training crashing after latest commits from Dec 2, 2022
Search before asking
- [X] I have searched the YOLOv5 issues and found no similar bug report.
YOLOv5 Component
No response
Bug
main(opt)
File "/home/aboggaram/projects/yolov5/segment/train.py", line 554, in main
train(opt.hyp, opt, device, callbacks)
File "/home/aboggaram/projects/yolov5/segment/train.py", line 309, in train
pred = model(imgs) # forward
File "/home/aboggaram/miniconda3/envs/yolov5/lib/python3.9/site-packages/torch/nn/modules/module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "/home/aboggaram/miniconda3/envs/yolov5/lib/python3.9/site-packages/torch/nn/parallel/distributed.py", line 994, in forward
if torch.is_grad_enabled() and self.reducer._rebuild_buckets():
RuntimeError: Expected to have finished reduction in the prior iteration before starting a new one. This error indicates that your training graph has changed in this iteration, e.g., one parameter is used in first iteration, but then got unused in the second iteration. this is not compatible with static_graph set to True.
Parameter indices which did not receive grad for rank 1: 375 376 377 378 379 380 381 382 383
In addition, you can set the environment variable TORCH_DISTRIBUTED_DEBUG to either INFO or DETAIL to print out information about which particular parameters did not receive gradient on this rank as part of this error
WARNING:torch.distributed.elastic.multiprocessing.api:Sending process 846723 closing signal SIGTERM
ERROR:torch.distributed.elastic.multiprocessing.api:failed (exitcode: 1) local_rank: 1 (pid: 846724) of binary: /home/aboggaram/miniconda3/envs/yolov5/bin/python3
Traceback (most recent call last):
File "/home/aboggaram/miniconda3/envs/yolov5/lib/python3.9/runpy.py", line 197, in _run_module_as_main
return _run_code(code, main_globals, None,
File "/home/aboggaram/miniconda3/envs/yolov5/lib/python3.9/runpy.py", line 87, in _run_code
exec(code, run_globals)
File "/home/aboggaram/miniconda3/envs/yolov5/lib/python3.9/site-packages/torch/distributed/run.py", line 765, in <module>
main()
File "/home/aboggaram/miniconda3/envs/yolov5/lib/python3.9/site-packages/torch/distributed/elastic/multiprocessing/errors/__init__.py", line 345, in wrapper
return f(*args, **kwargs)
File "/home/aboggaram/miniconda3/envs/yolov5/lib/python3.9/site-packages/torch/distributed/run.py", line 761, in main
run(args)
File "/home/aboggaram/miniconda3/envs/yolov5/lib/python3.9/site-packages/torch/distributed/run.py", line 752, in run
elastic_launch(
File "/home/aboggaram/miniconda3/envs/yolov5/lib/python3.9/site-packages/torch/distributed/launcher/api.py", line 131, in __call__
return launch_agent(self._config, self._entrypoint, list(args))
File "/home/aboggaram/miniconda3/envs/yolov5/lib/python3.9/site-packages/torch/distributed/launcher/api.py", line 245, in launch_agent
raise ChildFailedError(
torch.distributed.elastic.multiprocessing.errors.ChildFailedError:
============================================================
segment/train.py FAILED
------------------------------------------------------------
Failures:
<NO_OTHER_FAILURES>
------------------------------------------------------------
Root Cause (first observed failure):
[0]:
time : 2022-12-05_18:16:02
host : michaelangelo
rank : 1 (local_rank: 1)
exitcode : 1 (pid: 846724)
error_file: <N/A>
traceback : To enable traceback see: https://pytorch.org/docs/stable/elastic/errors.html
============================================================
Environment
github: up to date with https://github.com/ultralytics/yolov5 ✅
YOLOv5 🚀 v7.0-40-g81c38490 Python-3.9.12 torch-1.12.1 CUDA:0 (NVIDIA GeForce RTX 3090, 24268MiB)
CUDA:1 (NVIDIA GeForce RTX 3090, 24266MiB)
Ubuntu 22.04
Minimal Reproducible Example
time python3 -m torch.distributed.run \
--nproc_per_node 2 \
segment/train.py \
--device 0,1 \
--epochs 500 \
--hyp "${hyperparameter_config}" \
--optimizer "AdamW" \
--batch-size 4 \
--multi-scale \
--data "${dataset_config}" \
--img "${image_size}"
Additional
The code was working fine until I merged with the upstream main branch @gl
Are you willing to submit a PR?
- [X] Yes I'd like to help by submitting a PR!
👋 Hello @achbogga, thank you for your interest in YOLOv5 🚀! Please visit our ⭐️ Tutorials to get started, where you can find quickstart guides for simple tasks like Custom Data Training all the way to advanced concepts like Hyperparameter Evolution.
If this is a 🐛 Bug Report, please provide screenshots and minimum viable code to reproduce your issue, otherwise we can not help you.
If this is a custom training ❓ Question, please provide as much information as possible, including dataset images, training logs, screenshots, and a public link to online W&B logging if available.
For business inquiries or professional support requests please visit https://ultralytics.com or email [email protected].
Requirements
Python>=3.7.0 with all requirements.txt installed including PyTorch>=1.7. To get started:
git clone https://github.com/ultralytics/yolov5 # clone
cd yolov5
pip install -r requirements.txt # install
Environments
YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including CUDA/CUDNN, Python and PyTorch preinstalled):
- Notebooks with free GPU:



- Google Cloud Deep Learning VM. See GCP Quickstart Guide
- Amazon Deep Learning AMI. See AWS Quickstart Guide
- Docker Image. See Docker Quickstart Guide

Status
![]()
If this badge is green, all YOLOv5 GitHub Actions Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 training, validation, inference, export and benchmarks on MacOS, Windows, and Ubuntu every 24 hours and on every commit.
@achbogga DDP segmentation training runs correctly following usage example in segment/train.py.
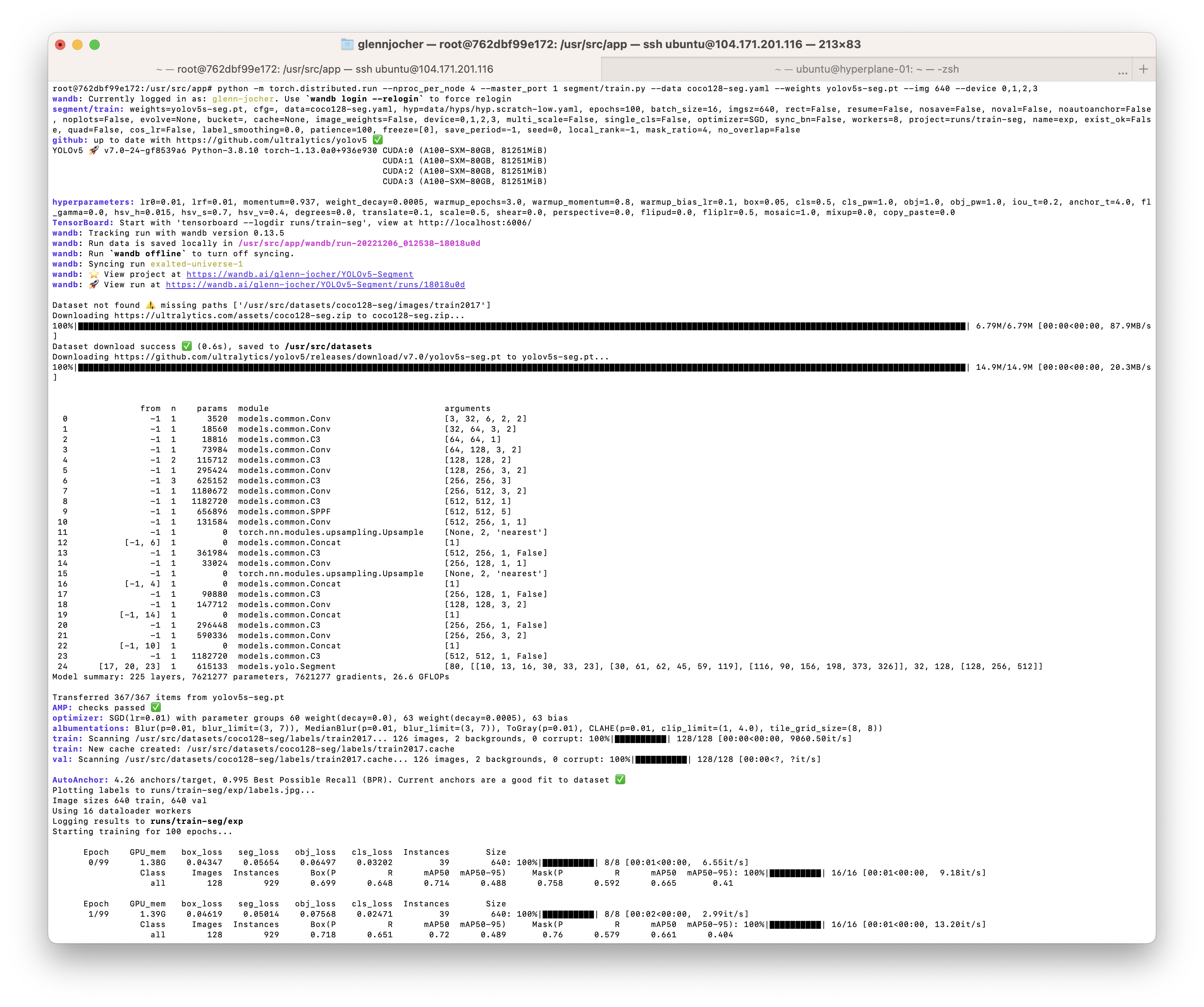
Your error is telling you something you've done is incompatible with static_graph=True:
RuntimeError: Expected to have finished reduction in the prior iteration before starting a new one. This error indicates that your training graph has changed in this iteration, e.g., one parameter is used in first iteration, but then got unused in the second iteration. this is not compatible with static_graph set to True.
This setting is in utils/torch_utils.py
There is a error when I run segment/train with 1280 or 1600 imgsz in DDP mode, It happenes around 20% of the first epoch. I am confused, because it is ok when the imgsz is 640 or 960. The error is as fellows:
RuntimeError: Expected to have finished reduction in the prior iteration before starting a new one. This error indicates that your training graph has changed in this iteration, e.g., one parameter is used in first iteration, but then got unused in the second iteration. this is not compatible with static_graph set to True.
I tried to set static_graph to True, but it is useless. Looking forward to your reply! Thanks!
There are some other method I have tried which is alse useless.
--> set DDP parameters static_graph=False, find_unused_parameters=False
@glenn-jocher No luck after setting the static_graph=False. Same error!
WARNING:__main__:
*****************************************
Setting OMP_NUM_THREADS environment variable for each process to be 1 in default, to avoid your system being overloaded, please further tune the variable for optimal performance in your application as needed.
*****************************************
segment/train: weights=/home/aboggaram/models/yolov5x-seg.pt, cfg=, data=/home/aboggaram/projects/yolov5/data/octiva.yaml, hyp=/home/aboggaram/projects/yolov5/data/hyps/octiva_hyp.scratch-low.yaml, epochs=500, batch_size=4, imgsz=640, rect=False, resume=False, nosave=False, noval=False, noautoanchor=False, noplots=False, evolve=None, bucket=, cache=None, image_weights=False, device=0,1, multi_scale=True, single_cls=False, optimizer=AdamW, sync_bn=False, workers=8, project=/home/aboggaram/models/octiva_yolov5_instance_segmentation_2022-12-06, name=train_image_size_640_, exist_ok=False, quad=False, cos_lr=False, label_smoothing=0.0, patience=100, freeze=[0], save_period=-1, seed=0, local_rank=-1, mask_ratio=4, no_overlap=False
github: up to date with https://github.com/ultralytics/yolov5 ✅
YOLOv5 🚀 v7.0-40-g81c38490 Python-3.9.12 torch-1.12.1 CUDA:0 (NVIDIA GeForce RTX 3090, 24268MiB)
CUDA:1 (NVIDIA GeForce RTX 3090, 24266MiB)
hyperparameters: lr0=0.001, lrf=0.01, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=0.05, cls=0.5, cls_pw=1.0, obj=1.0, obj_pw=1.0, iou_t=0.2, anchor_t=4.0, fl_gamma=0.0, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, mosaic=0.1, mixup=0.0, copy_paste=0.0
TensorBoard: Start with 'tensorboard --logdir /home/aboggaram/models/octiva_yolov5_instance_segmentation_2022-12-06', view at http://localhost:6006/
Overriding model.yaml nc=80 with nc=3
from n params module arguments
0 -1 1 8800 models.common.Conv [3, 80, 6, 2, 2]
1 -1 1 115520 models.common.Conv [80, 160, 3, 2]
2 -1 4 309120 models.common.C3 [160, 160, 4]
3 -1 1 461440 models.common.Conv [160, 320, 3, 2]
4 -1 8 2259200 models.common.C3 [320, 320, 8]
5 -1 1 1844480 models.common.Conv [320, 640, 3, 2]
6 -1 12 13125120 models.common.C3 [640, 640, 12]
7 -1 1 7375360 models.common.Conv [640, 1280, 3, 2]
8 -1 4 19676160 models.common.C3 [1280, 1280, 4]
9 -1 1 4099840 models.common.SPPF [1280, 1280, 5]
10 -1 1 820480 models.common.Conv [1280, 640, 1, 1]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 6] 1 0 models.common.Concat [1]
13 -1 4 5332480 models.common.C3 [1280, 640, 4, False]
14 -1 1 205440 models.common.Conv [640, 320, 1, 1]
15 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
16 [-1, 4] 1 0 models.common.Concat [1]
17 -1 4 1335040 models.common.C3 [640, 320, 4, False]
18 -1 1 922240 models.common.Conv [320, 320, 3, 2]
19 [-1, 14] 1 0 models.common.Concat [1]
20 -1 4 4922880 models.common.C3 [640, 640, 4, False]
21 -1 1 3687680 models.common.Conv [640, 640, 3, 2]
22 [-1, 10] 1 0 models.common.Concat [1]
23 -1 4 19676160 models.common.C3 [1280, 1280, 4, False]
24 [17, 20, 23] 1 2123944 models.yolo.Segment [3, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], 32, 320, [320, 640, 1280]]
Model summary: 456 layers, 88301384 parameters, 88301384 gradients, 265.0 GFLOPs
Transferred 757/763 items from /home/aboggaram/models/yolov5x-seg.pt
AMP: checks passed ✅
optimizer: AdamW(lr=0.001) with parameter groups 126 weight(decay=0.0), 129 weight(decay=0.0005), 129 bias
albumentations: Blur(p=0.01, blur_limit=(3, 7)), MedianBlur(p=0.01, blur_limit=(3, 7)), ToGray(p=0.01), CLAHE(p=0.01, clip_limit=(1, 4.0), tile_grid_size=(8, 8))
train: Scanning /home/aboggaram/data/Octiva/yolov7_instance_segmentation_format_Dec_2_2022/train/labels.cache... 2818 images, 606 backgrounds, 0 corrupt: 100%|██████████| 3424/3424 [00:00<?, ?it/s]
val: Scanning /home/aboggaram/data/Octiva/yolov7_instance_segmentation_format_Dec_2_2022/test/labels.cache... 385 images, 0 backgrounds, 0 corrupt: 100%|██████████| 385/385 [00:00<?, ?it/s]
AutoAnchor: 4.22 anchors/target, 0.968 Best Possible Recall (BPR). Anchors are a poor fit to dataset ⚠️, attempting to improve...
AutoAnchor: WARNING ⚠️ Extremely small objects found: 4495 of 142986 labels are <3 pixels in size
AutoAnchor: Running kmeans for 9 anchors on 140515 points...
AutoAnchor: Evolving anchors with Genetic Algorithm: fitness = 0.6852: 100%|██████████| 1000/1000 [00:21<00:00, 46.39it/s]
AutoAnchor: thr=0.25: 0.9768 best possible recall, 4.59 anchors past thr
AutoAnchor: n=9, img_size=640, metric_all=0.301/0.676-mean/best, past_thr=0.465-mean: 7,9, 17,16, 9,30, 21,37, 48,21, 32,61, 70,47, 79,105, 211,267
AutoAnchor: Done ✅ (optional: update model *.yaml to use these anchors in the future)
Plotting labels to /home/aboggaram/models/octiva_yolov5_instance_segmentation_2022-12-06/train_image_size_640_2/labels.jpg...
Image sizes 640 train, 640 val
Using 4 dataloader workers
Logging results to /home/aboggaram/models/octiva_yolov5_instance_segmentation_2022-12-06/train_image_size_640_2
Starting training for 500 epochs...
Epoch GPU_mem box_loss seg_loss obj_loss cls_loss Instances Size
0/499 9.16G 0.1104 0.07921 0.1958 0.03491 163 448: 6%|▌ | 50/856 [00:11<02:42, 4.96it/s]Traceback (most recent call last):
File "/home/aboggaram/projects/yolov5/segment/train.py", line 658, in <module>
main(opt)
File "/home/aboggaram/projects/yolov5/segment/train.py", line 554, in main
train(opt.hyp, opt, device, callbacks)
File "/home/aboggaram/projects/yolov5/segment/train.py", line 309, in train
pred = model(imgs) # forward
File "/home/aboggaram/miniconda3/envs/yolov5/lib/python3.9/site-packages/torch/nn/modules/module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "/home/aboggaram/miniconda3/envs/yolov5/lib/python3.9/site-packages/torch/nn/parallel/distributed.py", line 994, in forward
if torch.is_grad_enabled() and self.reducer._rebuild_buckets():
RuntimeError: Expected to have finished reduction in the prior iteration before starting a new one. This error indicates that your module has parameters that were not used in producing loss. You can enable unused parameter detection by passing the keyword argument `find_unused_parameters=True` to `torch.nn.parallel.DistributedDataParallel`, and by
making sure all `forward` function outputs participate in calculating loss.
If you already have done the above, then the distributed data parallel module wasn't able to locate the output tensors in the return value of your module's `forward` function. Please include the loss function and the structure of the return value of `forward` of your module when reporting this issue (e.g. list, dict, iterable).
Parameter indices which did not receive grad for rank 1: 375 376 377 378 379 380 381 382 383
In addition, you can set the environment variable TORCH_DISTRIBUTED_DEBUG to either INFO or DETAIL to print out information about which particular parameters did not receive gradient on this rank as part of this error
WARNING:torch.distributed.elastic.multiprocessing.api:Sending process 852610 closing signal SIGTERM
ERROR:torch.distributed.elastic.multiprocessing.api:failed (exitcode: 1) local_rank: 1 (pid: 852611) of binary: /home/aboggaram/miniconda3/envs/yolov5/bin/python3
Traceback (most recent call last):
File "/home/aboggaram/miniconda3/envs/yolov5/lib/python3.9/runpy.py", line 197, in _run_module_as_main
return _run_code(code, main_globals, None,
File "/home/aboggaram/miniconda3/envs/yolov5/lib/python3.9/runpy.py", line 87, in _run_code
exec(code, run_globals)
File "/home/aboggaram/miniconda3/envs/yolov5/lib/python3.9/site-packages/torch/distributed/run.py", line 765, in <module>
main()
File "/home/aboggaram/miniconda3/envs/yolov5/lib/python3.9/site-packages/torch/distributed/elastic/multiprocessing/errors/__init__.py", line 345, in wrapper
return f(*args, **kwargs)
File "/home/aboggaram/miniconda3/envs/yolov5/lib/python3.9/site-packages/torch/distributed/run.py", line 761, in main
run(args)
File "/home/aboggaram/miniconda3/envs/yolov5/lib/python3.9/site-packages/torch/distributed/run.py", line 752, in run
elastic_launch(
File "/home/aboggaram/miniconda3/envs/yolov5/lib/python3.9/site-packages/torch/distributed/launcher/api.py", line 131, in __call__
return launch_agent(self._config, self._entrypoint, list(args))
File "/home/aboggaram/miniconda3/envs/yolov5/lib/python3.9/site-packages/torch/distributed/launcher/api.py", line 245, in launch_agent
raise ChildFailedError(
torch.distributed.elastic.multiprocessing.errors.ChildFailedError:
============================================================
segment/train.py FAILED
------------------------------------------------------------
Failures:
<NO_OTHER_FAILURES>
------------------------------------------------------------
Root Cause (first observed failure):
[0]:
time : 2022-12-06_14:07:30
host : michaelangelo
rank : 1 (local_rank: 1)
exitcode : 1 (pid: 852611)
error_file: <N/A>
traceback : To enable traceback see: https://pytorch.org/docs/stable/elastic/errors.html
@TurboPlus @achbogga to investigate an issue it needs to be reproducible by us. If you can reproduce this error in a common environment (i.e. our Docker image) using a common dataset (i.e. COOC128-seg) then please let us know. Otherwise there is no action for us to take. As I mentioned above I already tried this in https://github.com/ultralytics/yolov5/issues/10410#issuecomment-1338555263 and everything works correctly.
We've created a few short guidelines below to help users provide what we need in order to start investigating a possible problem.
How to create a Minimal, Reproducible Example
When asking a question, people will be better able to provide help if you provide code that they can easily understand and use to reproduce the problem. This is referred to by community members as creating a minimum reproducible example. Your code that reproduces the problem should be:
- ✅ Minimal – Use as little code as possible to produce the problem
- ✅ Complete – Provide all parts someone else needs to reproduce the problem
- ✅ Reproducible – Test the code you're about to provide to make sure it reproduces the problem
For Ultralytics to provide assistance your code should also be:
- ✅ Current – Verify that your code is up-to-date with GitHub master, and if necessary
git pullorgit clonea new copy to ensure your problem has not already been solved in master. - ✅ Unmodified – Your problem must be reproducible using official YOLOv5 code without changes. Ultralytics does not provide support for custom code ⚠️.
If you believe your problem meets all the above criteria, please close this issue and raise a new one using the 🐛 Bug Report template with a minimum reproducible example to help us better understand and diagnose your problem.
Thank you! 😃
👋 Hello, this issue has been automatically marked as stale because it has not had recent activity. Please note it will be closed if no further activity occurs.
Access additional YOLOv5 🚀 resources:
- Wiki – https://github.com/ultralytics/yolov5/wiki
- Tutorials – https://docs.ultralytics.com/yolov5
- Docs – https://docs.ultralytics.com
Access additional Ultralytics ⚡ resources:
- Ultralytics HUB – https://ultralytics.com/hub
- Vision API – https://ultralytics.com/yolov5
- About Us – https://ultralytics.com/about
- Join Our Team – https://ultralytics.com/work
- Contact Us – https://ultralytics.com/contact
Feel free to inform us of any other issues you discover or feature requests that come to mind in the future. Pull Requests (PRs) are also always welcomed!
Thank you for your contributions to YOLOv5 🚀 and Vision AI ⭐!
There is a error when I run segment/train with 1280 or 1600 imgsz in DDP mode, It happenes around 20% of the first epoch. I am confused, because it is ok when the imgsz is 640 or 960. The error is as fellows:
@glenn-jocher I have exactly the same issue! Crashes in the first epoch with bigger image size with DDP. There is definitely something going on here. YOLO for segmentation also crashes for many other features, like model ensambling, TTA, --save-txt and many others!
@achbogga @glenn-jocher I am experiencing the same issue with DDP and segmentation. The code hangs there in the second epoch. The issues occurs with or without the docker. The code runs just fine with DP or on a single gpu. If I remove the --sync-bn flag, hen I get the following error at the end of epoch 2. The code runs fine on the default COCO dataset and this issue happened only for my custom dataset...if the issue is with my dataset so why it works just fine without DDP?
Traceback (most recent call last):
File "segment/train.py", line 658, in <module>
main(opt)
File "segment/train.py", line 554, in main
train(opt.hyp, opt, device, callbacks)
File "segment/train.py", line 309, in train
pred = model(imgs) # forward
File "/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "/usr/local/lib/python3.8/dist-packages/torch/nn/parallel/distributed.py", line 1026, in forward
if torch.is_grad_enabled() and self.reducer._rebuild_buckets():
RuntimeError: Expected to have finished reduction in the prior iteration before starting a new one. This error indicates that your training graph has changed in this iteration, e.g., one parameter is used in first iteration, but then got unused in the second iteration. this is not compatible with static_graph set to True.
Parameter indices which did not receive grad for rank 6: 375 376 377 378 379 380 381 382 383
In addition, you can set the environment variable TORCH_DISTRIBUTED_DEBUG to either INFO or DETAIL to print out information about which particular parameters did not receive gradient on this rank as part of this error
WARNING:torch.distributed.elastic.multiprocessing.api:Sending process 95 closing signal SIGTERM
WARNING:torch.distributed.elastic.multiprocessing.api:Sending process 96 closing signal SIGTERM
WARNING:torch.distributed.elastic.multiprocessing.api:Sending process 97 closing signal SIGTERM
WARNING:torch.distributed.elastic.multiprocessing.api:Sending process 98 closing signal SIGTERM
WARNING:torch.distributed.elastic.multiprocessing.api:Sending process 99 closing signal SIGTERM
WARNING:torch.distributed.elastic.multiprocessing.api:Sending process 100 closing signal SIGTERM
WARNING:torch.distributed.elastic.multiprocessing.api:Sending process 104 closing signal SIGTERM
ERROR:torch.distributed.elastic.multiprocessing.api:failed (exitcode: 1) local_rank: 6 (pid: 102) of binary: /usr/bin/python
Traceback (most recent call last):
File "/usr/lib/python3.8/runpy.py", line 194, in _run_module_as_main
return _run_code(code, main_globals, None,
File "/usr/lib/python3.8/runpy.py", line 87, in _run_code
exec(code, run_globals)
File "/usr/local/lib/python3.8/dist-packages/torch/distributed/run.py", line 766, in <module>
main()
File "/usr/local/lib/python3.8/dist-packages/torch/distributed/elastic/multiprocessing/errors/__init__.py", line 346, in wrapper
return f(*args, **kwargs)
File "/usr/local/lib/python3.8/dist-packages/torch/distributed/run.py", line 762, in main
run(args)
File "/usr/local/lib/python3.8/dist-packages/torch/distributed/run.py", line 753, in run
elastic_launch(
File "/usr/local/lib/python3.8/dist-packages/torch/distributed/launcher/api.py", line 132, in __call__
return launch_agent(self._config, self._entrypoint, list(args))
File "/usr/local/lib/python3.8/dist-packages/torch/distributed/launcher/api.py", line 246, in launch_agent
raise ChildFailedError(
torch.distributed.elastic.multiprocessing.errors.ChildFailedError:
============================================================
segment/train.py FAILED
------------------------------------------------------------
Failures:
<NO_OTHER_FAILURES>
------------------------------------------------------------
Root Cause (first observed failure):
[0]:
time : 2023-01-07_19:02:02
host : 421889788c52
rank : 6 (local_rank: 6)
exitcode : 1 (pid: 102)
error_file: <N/A>
traceback : To enable traceback see: https://pytorch.org/docs/stable/elastic/errors.html
after increasing the batch size to at least 6 per gpus, the codes does not hang but generates another error after 6 epochs:
operation timeout: WorkNCCL(SeqNum=23360, OpType=ALLREDUCE, Timeout(ms)=1800000) ran for 1809059 milliseconds before timing out.
[E ProcessGroupNCCL.cpp:821] [Rank 5] Watchdog caught collective operation timeout: WorkNCCL(SeqNum=23360, OpType=ALLREDUCE, Timeout(ms)=1800000) ran for 1809070 milliseconds before timing out.
[E ProcessGroupNCCL.cpp:821] [Rank 3] Watchdog caught collective operation timeout: WorkNCCL(SeqNum=23360, OpType=ALLREDUCE, Timeout(ms)=1800000) ran for 1809112 milliseconds before timing out.
[E ProcessGroupNCCL.cpp:821] [Rank 1] Watchdog caught collective operation timeout: WorkNCCL(SeqNum=23360, OpType=ALLREDUCE, Timeout(ms)=1800000) ran for 1809115 milliseconds before timing out.
[E ProcessGroupNCCL.cpp:821] [Rank 4] Watchdog caught collective operation timeout: WorkNCCL(SeqNum=23360, OpType=ALLREDUCE, Timeout(ms)=1800000) ran for 1809110 milliseconds before timing out.
[E ProcessGroupNCCL.cpp:821] [Rank 7] Watchdog caught collective operation timeout: WorkNCCL(SeqNum=23360, OpType=ALLREDUCE, Timeout(ms)=1800000) ran for 1809115 milliseconds before timing out.
[E ProcessGroupNCCL.cpp:821] [Rank 6] Watchdog caught collective operation timeout: WorkNCCL(SeqNum=23360, OpType=ALLREDUCE, Timeout(ms)=1800000) ran for 1809113 milliseconds before timing out.
[E ProcessGroupNCCL.cpp:821] [Rank 0] Watchdog caught collective operation timeout: WorkNCCL(SeqNum=23360, OpType=ALLREDUCE, Timeout(ms)=1800000) ran for 1809355 milliseconds before timing out.
Traceback (most recent call last):
File "segment/train.py", line 658, in <module>
main(opt)
File "segment/train.py", line 554, in main
train(opt.hyp, opt, device, callbacks)
File "segment/train.py", line 317, in train
scaler.scale(loss).backward()
File "/usr/local/lib/python3.8/dist-packages/torch/_tensor.py", line 488, in backward
torch.autograd.backward(
File "/usr/local/lib/python3.8/dist-packages/torch/autograd/__init__.py", line 197, in backward
Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
File "/usr/local/lib/python3.8/dist-packages/torch/autograd/function.py", line 267, in apply
return user_fn(self, *args)
File "/usr/local/lib/python3.8/dist-packages/torch/nn/modules/_functions.py", line 130, in backward
torch.distributed.all_reduce(
File "/usr/local/lib/python3.8/dist-packages/torch/distributed/distributed_c10d.py", line 1536, in all_reduce
work = group.allreduce([tensor], opts)
RuntimeError: NCCL communicator was aborted on rank 3. Original reason for failure was: [Rank 3] Watchdog caught collective operation timeout: WorkNCCL(SeqNum=23360, OpType=ALLREDUCE, Timeout(ms)=1800000) ran for 1809112 milliseconds before timing out.
WARNING:torch.distributed.elastic.multiprocessing.api:Sending process 95 closing signal SIGTERM
WARNING:torch.distributed.elastic.multiprocessing.api:Sending process 96 closing signal SIGTERM
WARNING:torch.distributed.elastic.multiprocessing.api:Sending process 97 closing signal SIGTERM
WARNING:torch.distributed.elastic.multiprocessing.api:Sending process 99 closing signal SIGTERM
WARNING:torch.distributed.elastic.multiprocessing.api:Sending process 100 closing signal SIGTERM
WARNING:torch.distributed.elastic.multiprocessing.api:Sending process 102 closing signal SIGTERM
WARNING:torch.distributed.elastic.multiprocessing.api:Sending process 104 closing signal SIGTERM
ERROR:torch.distributed.elastic.multiprocessing.api:failed (exitcode: 1) local_rank: 3 (pid: 98) of binary: /usr/bin/python
Traceback (most recent call last):
File "/usr/lib/python3.8/runpy.py", line 194, in _run_module_as_main
return _run_code(code, main_globals, None,
File "/usr/lib/python3.8/runpy.py", line 87, in _run_code
exec(code, run_globals)
File "/usr/local/lib/python3.8/dist-packages/torch/distributed/run.py", line 766, in <module>
main()
File "/usr/local/lib/python3.8/dist-packages/torch/distributed/elastic/multiprocessing/errors/__init__.py", line 346, in wrapper
return f(*args, **kwargs)
File "/usr/local/lib/python3.8/dist-packages/torch/distributed/run.py", line 762, in main
run(args)
File "/usr/local/lib/python3.8/dist-packages/torch/distributed/run.py", line 753, in run
elastic_launch(
File "/usr/local/lib/python3.8/dist-packages/torch/distributed/launcher/api.py", line 132, in __call__
return launch_agent(self._config, self._entrypoint, list(args))
File "/usr/local/lib/python3.8/dist-packages/torch/distributed/launcher/api.py", line 246, in launch_agent
raise ChildFailedError(
torch.distributed.elastic.multiprocessing.errors.ChildFailedError:
============================================================
segment/train.py FAILED
------------------------------------------------------------
Failures:
<NO_OTHER_FAILURES>
------------------------------------------------------------
Root Cause (first observed failure):
[0]:
time : 2023-01-07_21:25:53
host : e2e79cee659c
rank : 3 (local_rank: 3)
exitcode : 1 (pid: 98)
error_file: <N/A>
traceback : To enable traceback see: https://pytorch.org/docs/stable/elastic/errors.html
============================================================
After spending a good amount of time of this issue, I could fix the problem by increasing the batch size to the highest possible (for my images of 1152*1152, I set batch size as 56 for 8 gpus) and using a smaller size model.
Still crashes for me with any batch size and without --sync-bn, see https://github.com/ultralytics/yolov5/issues/10716
👋 Hello, this issue has been automatically marked as stale because it has not had recent activity. Please note it will be closed if no further activity occurs.
Access additional YOLOv5 🚀 resources:
- Wiki – https://github.com/ultralytics/yolov5/wiki
- Tutorials – https://docs.ultralytics.com/yolov5
- Docs – https://docs.ultralytics.com
Access additional Ultralytics ⚡ resources:
- Ultralytics HUB – https://ultralytics.com/hub
- Vision API – https://ultralytics.com/yolov5
- About Us – https://ultralytics.com/about
- Join Our Team – https://ultralytics.com/work
- Contact Us – https://ultralytics.com/contact
Feel free to inform us of any other issues you discover or feature requests that come to mind in the future. Pull Requests (PRs) are also always welcomed!
Thank you for your contributions to YOLOv5 🚀 and Vision AI ⭐!