pandas-ta
 pandas-ta copied to clipboard
pandas-ta copied to clipboard
Additional simplified interface
Is your feature request related to a problem? Please describe. Calculating an indicator is currently possible in 2 ways (that i am aware of).
import pandas_ta as pta
df['rsi'] = pta.rsi(df['close'])
df['atr'] = pta.atr(df['high'], df['low'], df['close'], 20)
# or
df.ta.rsi(append=True)
df.ta.atr(20, append=True)
While usage of the above is "okish" for simple indicators like RSI (which only requires close) - it'll become painful with other indicators, which also require open, high, low, and maybe also volume).
The "dataframe interface" on the other hand would provide this simplification, but forces certain naming conventions - which can break further usage down the line (maybe a name(s) argument could be provided here, on top of the prefix / postfix, so the name(s) is 100% stable/predictable.)
(the above would result in "ATR_20" - which would change to ATR_21 if the number changes ...
While this can work for some cases, it can also cause issues if trying to find the right value for this.
Obviously this can become tricky for "multi-column" indicators ... where a list of names with the correct lenght might work.
As the "dataframe interface" already assumes certain facts about the underlying dataframe, an (additional) interface as follows would be great:
import pandas_ta.abstract as pta
df['rsi'] = pta.rsi(df)
df['atr'] = pta.atr(df, 20)
While for RSI, there's not much "saved letters" - for other indicators (like atr in the above sample) this can provide quite some simplification for the user.
It'd provide full control on the "resulting" dataframe column name, while simplifying the user's life.
Implementation-wise, i guess this can be mostly auto-generated - and might result in a slightly different import (similar to how the ta-lib python wrapper handles this).
note Maybe i'm overlooking an alternative here which allows this already ... but i haven't quite found a way that provides both the simplicity (i'm lazy when typing), as well as freedom in column naming.
Hey @xmatthias,
Maybe i'm overlooking an alternative here which allows this already ... but i haven't quite found a way that provides both the simplicity (i'm lazy when typing), as well as freedom in column naming.
I am lazy when typing as well. So perhaps the third Programming Convention, Pandas TA Strategy, as mentioned on the README may be what you want.
It is a ta DataFrame Extension method, df.ta.strategy(), that one can automatically append indicators to the current df; less typing. This Jupyter Notebook shows examples on how to create Custom Strategies, including column naming like the last cell.
Here is a modified use case similar to the last cell in the Jupyter Notebook with Column Naming that you are interested in:
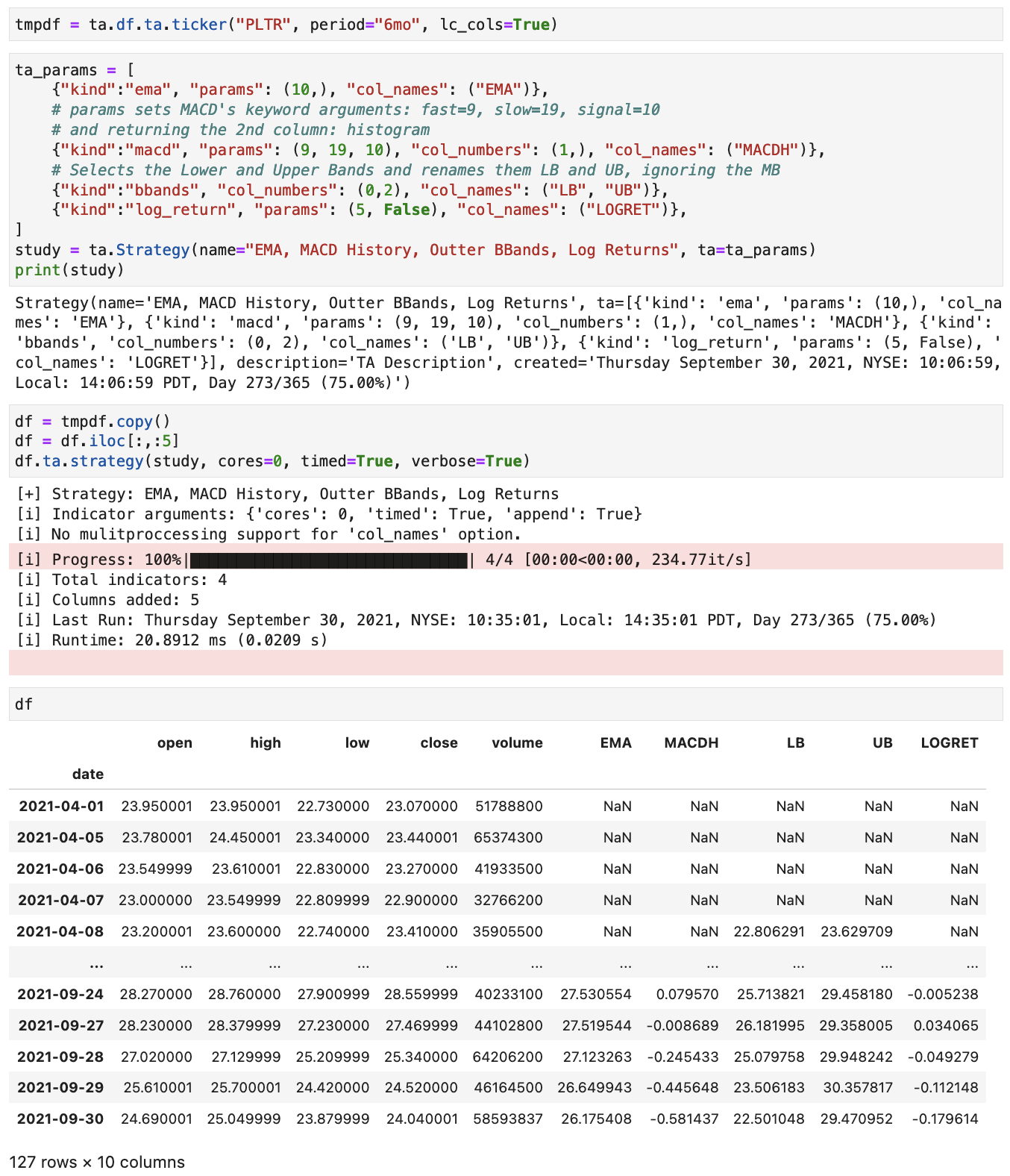
Note: When using 'col_names', there is [i] No mulitproccessing support for 'col_names' option. So this might be the only issue if there are a ton of indicators that need to be ran.
Potential New DataFrame Extension Property
I have also been thinking of adding another settable DataFrame Extension Property, like df.ta.study, which allows a user to specify a json file defining a Custom Strategy.
For example, consider sample.json:
{
"name": "Sample JSON Strategy",
"description": "Sample JSON Strategy Test",
"ta": [
{"kind": "ema", "length": 10, "sma": false},
{"kind": "sma", "length": 50, "talib": false},
{
"kind": "bbands",
"talib": true,
"col_numbers": [0, 1, 2],
"col_names": ["BBL", "BBM", "BBU"]
},
{
"kind": "atr",
"length": 50,
"talib": true,
"col_names": ["ATR"]
}
]
}
from json import load as json_load
import pandas_ta as ta
tmpdf = ta.df.ta.ticker("PLTR", period="6mo", lc_cols=True)
def load_strategy(path:str):
strat, json_strat = None, json_load(open(path))
strat = json_strat[0] if isinstance(json_strat, list) and len(json_strat) == 1 else json_strat
for indicator in strat["ta"]:
if "col_numbers" in indicator and len(indicator["col_numbers"]):
indicator["col_numbers"] = tuple(indicator["col_numbers"])
if "col_names" in indicator and len(indicator["col_names"]):
indicator["col_names"] = tuple(indicator["col_names"])
if strat is not None and hasattr(strat, "description") and len(strat):
return ta.Strategy(name=strat["name"], ta=strat["ta"], description=strat["description"])
else:
return ta.Strategy(name=strat["name"], ta=strat["ta"])
study = load_strategy("./sample.json")
df = tmpdf.copy() # Download
df = df.iloc[:,:-2] # Remove 'dividends' and 'stock splits' columns
df.ta.strategy(study, timed=True, verbose=True)
df = df.iloc[:,3:] # Ignore 'open', 'high', 'low' and 'volume' for charting
df.drop(columns=["volume"], inplace=True)
# Plot everything but 'ATR' since it has a different scale
colors = ["black", "green", "red", "violet", "purple", "violet"]
df.iloc[:,:-1].plot(figsize=(16,10), color=colors, title=study.name, grid=True)
Result

Thoughts on loading a JSON strategy/study that I outlined with the help of a DataFrame Extension Property?
Hope this answers the question and helps!
KJ
yes(ish) - while it will kindof satisfies what i'm looking for - it's also quite verbose when only looking for 1-2 indicators.
Obviously, if i have a full strategy (with 5-10+ indicators) - df.Strategy() will for sure be an option, but if i just need one or 2 indicators to be named in a certain way - it's quite a verbose way to specify the indicators.
When using 'col_names', there is [i] No mulitproccessing support for 'col_names' option.
i'm not sure i understand the reason for this limitation - i guess it's to avoid setting the same column twice - but i guess that could be checked before spawning out into processes (?)
I'm honestly not quite sure what benefit the "json" would bring over the strategy - at least in the sample above, you've only got 2 additional attributes (description, name) - the rest (everything within ta) seems to be almost identical to the existing strategy() method.
In the end, if i really want to store my strategy as json, i can simply use json.read(<somefilename>) and use the output of that as input for df.ta.strategy(json.read('profitstrategy.json')) - so personally, i see little added benefit at this point, but maybe you have a specific usecase in mind for this?
@twopirllc
[i] No mulitproccessing support for 'col_names' option.
What would be the reason behind it? I was thinking we could do a first pass across all indicators to get the output column_names to check for any collisions and only start processing once sure that all column names are unique. Thoughts?
@xmatthias What is a desired behavior when you want 2 or more of same indicator (say SMA5 and SMA50 or RSI14 and RSI50)?
df.ta.rsi(append=True)
df.ta.rsi(50, append=True)
When we print a Strategy, will printing the output column_names simplify user experience?
custom_a = ta.Strategy(name="A", ta=[{"kind": "sma"}, {"kind": "sma", "length": 50}, {"kind": "sma", "length": 200}])
print(custom_a)
Strategy(name='A', ta=[{'kind': 'sma', 'output_column_names': ['SMA_10']}, {'kind': 'sma', 'length': 50, 'output_column_names': ['SMA_50']}, {'kind': 'sma', 'length': 200, 'output_column_names': ['SMA_50']}], description='TA Description', created='Saturday June 19, 2021, NYSE: 7:59:38, Local: 11:59:38 PDT, Day 170/365 (47.00%)')
@twopirllc Any thoughts?