twilight
 twilight copied to clipboard
twilight copied to clipboard
refactor!(gateway): restructure the crate
Refactor and restructure the twilight-gateway crate from the ground up, providing a simpler implementation that is easier to follow the implementation details of and easier to use.
There are two primary routes this PR accomplishes to achieve these goals: removing the cluster and removing the shard processor. The cluster largely duplicated much of the shard and significantly increased the API surface of the crate. Instead of duplicating the base shard types we can make them more flexible to allow for mass creation of shards, which is what the cluster achieved. Meanwhile, the shard processor was a background task that actually "ran" the logic and state of the shard and its Websocket connections, so by removing it we can de-duplicate API between the previous shard and shard processor into just the shard.
The API is dramatically simplifies with these changes. In summary, this brings the API down to a shard, its configuration, event type flags, message ratelimiter, and Websocket messages, streams for initializing multiple shards, along with some small supporting types. In comparison to the previous API, the previous API included mostly all this and nearly double the types to support a cluster half of the API.
A bonus benefit of this is that everything* has been refactored. The internals of shards are now more understandable, cruft that has collected over the years has been removed, and the flow of the code is easier to understand for those attempting to learn it. Internal documentation, both explicit and self-documented, has been greatly improved along with this.
This refactor and restructure is based on discussion from Discord and from discussion #1639.
Todo:
- [x] Document everything, including private items
- [x] Update examples
- [x] Move Ready type to model crate
- [x] Reconcile with commits to
nextthat have been overwritten - [x] Cleanup a couple of complicated match statements
- [x] Add support for streaming shards for cluster buckets
- [x] Fix connection closes sometimes not restarting the shard and going into an infinite loop
- [x] Exponential backoff on failed reconnects
- [x] Re-implement TLS connector sharing from #1058
- [x] Explain the flow of how things work in internal documentation
- [x] Provide simple crate example
- [x] Cluster alternative for streams of events across shards
- [x]
twilight-gateway-queuedocumentation will need to be updated - [x] check for any remaining references to the Cluster
- [x] provide an alternative to
ClusterBuilder::shard_presencein thestreammodule functions (take Fn instead of a Config) - [ ] give user mutably referenced messages instead of owned
Public Documentation
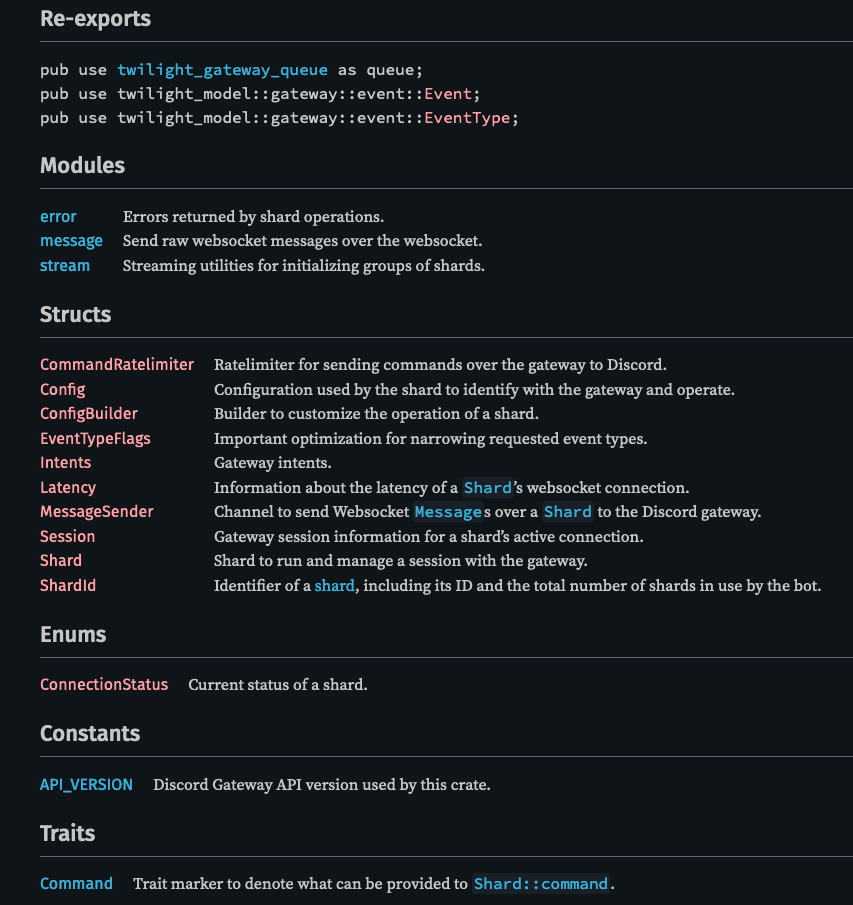
Private Documentation
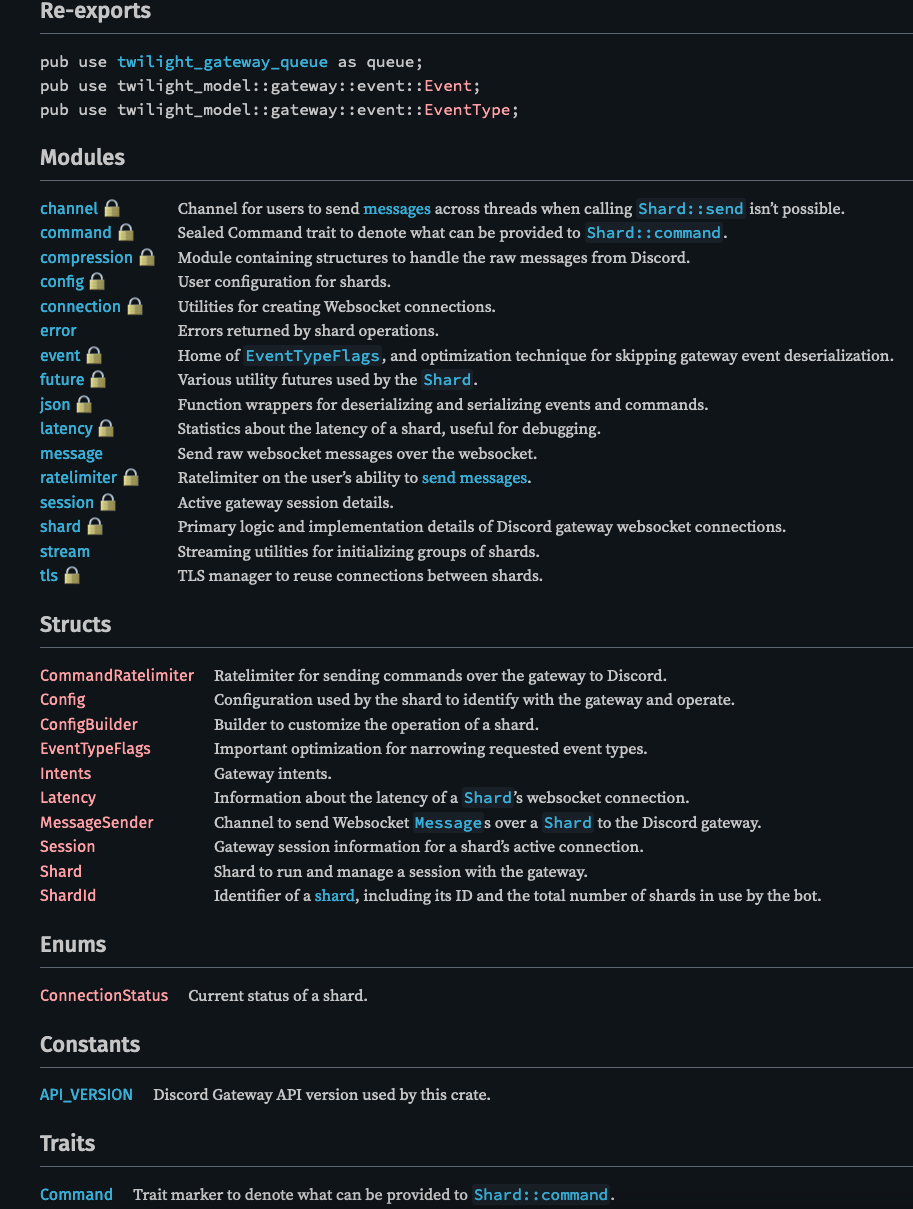
Could
unreachable_pubto the deny list? (See my comment in https://github.com/twilight-rs/twilight/discussions/1644.)
As-is this doesn't catch any accidental private types. This creates a lot of false positives and would require marking everything public with pub(crate), even in private modules. I think that's a conversation of its own.
Rest of the comments have been addressed. I went with ShardId::number since we can't go with ShardId::id due to duplication, ShardId::index is confusing when the value being 0-indexed matters due to the total being 1-indexed, and ShardId::this can't be used due to this being an alias for self. Any other suggestions welcome
I think we should probably have a nice way to handle clusters before merging it since there is no reason for everyone to invent their own here.
Although a bit incomplete right now, the stream module is meant to support creating groups of shards. Is there something larger you envision a cluster being able to do? In our previous iteration of the gateway, it basically duplicated the methods of the Shard while taking an index, which is the same as map.get(index)?.method(...) if the user collects the streams into a map.
Is there something larger you envision a cluster being able to do?
The main thing I would like to see is for a way to go from the stream of shards and make it possible to call next_{event, message} on them at once taking the first available.
So something like the following:
struct Cluster { /* stuff */}
impl Cluster {
fn new(shards: ShardStream) -> Self;
fn next_event(&mut self) -> Result<(ShardID, Event)>;
}
I feel like that is the only part that is needed of the api, and possible also to send a event on a given shard in the stream.
Is there something larger you envision a cluster being able to do?
The main thing I would like to see is for a way to go from the stream of shards and make it possible to call next_{event, message} on them at once taking the first available.
So something like the following:
struct Cluster { /* stuff */} impl Cluster { fn new(shards: ShardStream) -> Self; fn next_event(&mut self) -> Result<(ShardID, Event)>; }I feel like that is the only part that is needed of the api, and possible also to send a event on a given shard in the stream.
I would like to avoid a cluster, and the way I'm going about this is tricky! But I think I can get something for this working
I would like to avoid a cluster, and the way I'm going about this is tricky! But I think I can get something for this working
Yeah I understand that, I just remember it being a pain when I implemented the cluster to get it working in a good way, so I would rather have that in the library than need everyone to implement it for themselves.
I think providing an example implementation is the best, provided it's not overly complex. The "Cluster" should also concurrently listen to incoming events (select (if cancel-safe) or tokio::spawn) like the current Cluster.
@7596ff Re-requested review since I have answered or resolved all open comments
@Erk- Re-requested review, all comments addressed other than the cluster alternative request which is WIP
@vilgotf Re-requested review
nits addressed. does anyone have comments about the overall direction of the pr as a whole
nits addressed. does anyone have comments about the overall direction of the pr as a whole
I'm ready to approve this after a blessed Cluster alternative (can be an example) is available.
ClusterBuilder::shard_presence has effectively been removed, which was a requested feature, so that should be added back somehow.
Couldn't this be implemented by just having ConfigBuilder::presence be:
pub fn presence<F: Fn(ShardId) -> Option<UpdatePresencePayload>>(self, presence: F) -> Self
Cause why have two ways of doing the same thing?
It does cause "problems" with Config::presence having an unclear return type, but this method could, and maybe should, be hidden anyways (same with Config::identify_properties).
@Erk- I have provided a cluster events alternative:
use futures::StreamExt;
use std::{collections::HashMap, env, future};
use twilight_gateway::{stream::{self, ShardEventStream}, Config, Intents};
let token = env::var("DISCORD_TOKEN")?;
// callback to create a config for each shard, useful for when not all shards
// have the same configuration, such as for per-shard presences
let config_callback = |_| Config::new(token.clone(), Intents::GUILDS);
let mut shards = stream::start_recommended(token.clone(), config_callback)
.await?
.filter_map(|shard_result| async move { shard_result.ok() })
.collect::<Vec<_>>()
.await;
let mut stream = ShardEventStream::new(shards.iter_mut());
loop {
let (shard, event) = match stream.next().await {
Some(Ok((shard, event))) => (shard, event),
Some(Err(source)) => {
tracing::warn!(?source, "error receiving event");
if source.is_fatal() {
break;
}
continue;
},
None => break,
};
println!("received event on shard {}: {event:?}", shard.id());
}
The same exists for Shard::next_message.
Due to the new cluster alternative returning mutable references to shards, the list item on the checklist, "give user mutably referenced messages instead of owned", may not be possible. Providing users with websocket messages that have mutable (required for simd-json) references to the compression buffer (in order to re-use the allocated buffer between messages) may not be possible. I'll have to think. Notably, even if we didn't provide mutable references to the shards, users would still have to be able to get mutable references to shards themselves some other way in order to use Shard::command.
Other than that optimization, this PR is ready.
why have the stream's Item be (ShardRef, Message) instead of (ShardId, Message)?
Notably, even if we didn't provide mutable references to the shards, users would still have to be able to get mutable references to shards themselves some other way in order to use Shard::command.
Shard::command is not needed because of Shard::sender.
Now that
ShardEventis removed I've thought of the difference betweenEvent,GatewayEventandDispatchEvent.Eventis now just a flattenedGatewayEvent, which in turn is aDispatchEventplus some gateway internal events. Does it still make sense fornext_event()to returnEvent? Should it not just returnDispatchEvent?
it's desirable to allow people to still match over non-dispatch gateway events
why have the stream's
Itembe(ShardRef, Message)instead of(ShardId, Message)?
these event/message stream implementations keep a list of unordered futures of all shards between ready polls of the stream. if we didn't do this, we would have to re-build the list of futures each successful poll. this prevents having to re-build, allocate, poll, and wait for every future to resolve again. because of this, we need to keep mutable references to shards. if we give users shard IDs but not the shard, then users can't obtain a reference - immutable or otherwise - to the shard, because doing so is illegal while it's mutably borrowed. therefore, having a reference that re-inserts the shard into the stream on drop gets around this and allows users to actually use the shard that created the event. having a stream and a separate list of shards users could fetch only worked before with the cluster because the stream operated off of N mpsc channels, which is horridly inefficient compared to this solution
Shard::commandis not needed because ofShard::sender.
maybe so, but because of the above restriction we can still allow users to call shard::command
Does this not mean that you will need to handle a message completely before being able to get another message. Eg if you moved the shard into another task and had it running in a loop no other messages would be received?
no, it just means that you need to handle using the shard completely before being able to get another message. users can receive a ShardRef and Event, obtain whatever info from the shard they need to process events (such as obtaining a message sender or the latency), and then spawn a task and provide the task the message sender and event. the shard will be dropped, re-inserted, and poll again while the event task is processing
Would it not be best if this implements Send?
given the above context I don't personally believe that's necessary