VisualThinker-R1-Zero
 VisualThinker-R1-Zero copied to clipboard
VisualThinker-R1-Zero copied to clipboard
Explore the Multimodal “Aha Moment” on 2B Model
VisualThinker-R1-Zero: First ever R1-Zero's Aha Moment on just a 2B non-SFT Model
![]()
VisualThinker-R1-Zero is a replication of DeepSeek-R1-Zero in visual reasoning. We are the first to successfully observe the emergent “aha moment” and increased response length in visual reasoning on just a 2B non-SFT models.
For more details, please refer to the notion report.
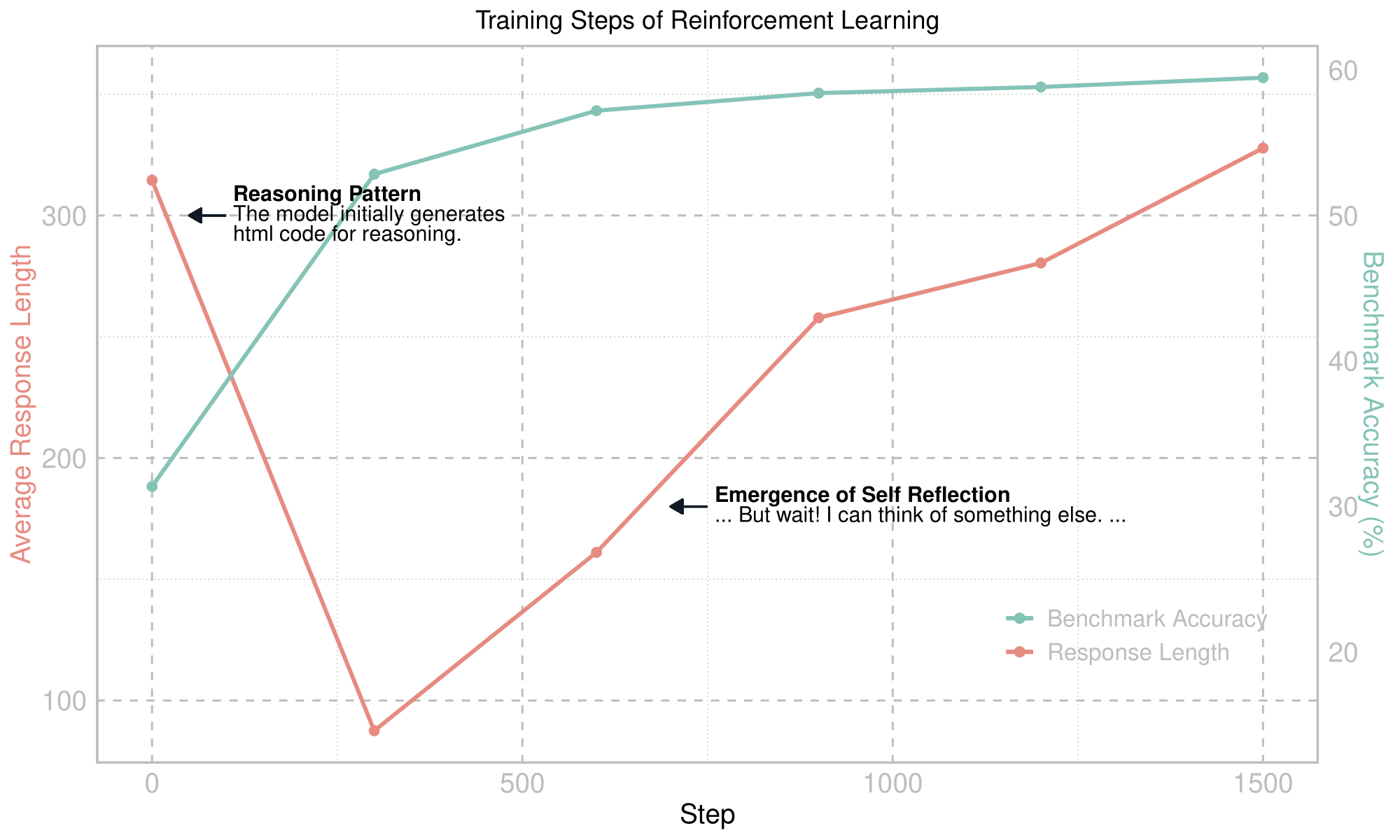
Training dynamics of our VisualThinker-R1-Zero training starting from the Qwen-VL-2B, without SFT or reward models. An aha moment and increasing response length is ever observed at a multimodal model.
🔮 Highlights
- We are the first to successfully produce the emergent “aha moment” and increased response length for multimodal reasoning on just a non-SFT 2B model.
- We showed that vision-centric tasks could also benefit from improved reasoning capabilities.
Similar to DeepSeek R1, self reflection behavior is also observed during our RL training on vision-centric reasoning tasks. The model exhibits an emergent ability to rethink and correct its mistakes:
. . .
Therefore, dark brown wooden bed with white blanket is not above the doorway.
But wait! I can think of something else.
Maybe it's just higher than above the doorway, but slightly lower than above the doorway.
. . .
📢 Updates
- 2025-03-16: 🤗We released the model checkpoint at huggingface!
- 2025-02-26: 🔥We share our main findings in this notion blog.
- 2025-02-26: 🔥We release the VisualThinker R1 Zero repo.
💻 Hardware Requirements
* estimated
| Method | Bits | 2B |
|---|---|---|
| GRPO Full Fine-Tuning | AMP | 4*80GB |
🧱 Setup
bash setup.sh
🤗 Prepare Dataset
cd src/data/SAT
bash prepare_dataset.sh
🏋️ Training
GRPO Training
To reproduce the multimodal aha moment, run the following code to train the non-SFT model with GRPO on SAT:
cd src/open-r1-multimodal
bash run_grpo_SAT.sh # Adjust open-r1-multimodal/configs/zero3.yaml or zero2.yaml accordingly
SFT Training
To obtain SFT model for comparison, run the following code to train the non-SFT model on SAT:
cd src/open-r1-multimodal
bash run_sft.sh # Adjust open-r1-multimodal/configs/zero3.yaml or zero2.yaml accordingly
📈 Evaluation
CVBench Evaluation
We provide following commands to reproduce our evaluation results on the CVBench. First change to evaluation directory:
cd src/eval
To evaluate Base + GRPO (VisualThinker R1 Zero) model:
python evaluate_Qwen2_VL_CVBench-base.py --model_path <path_to_your_model> \
--bs 8 \
--use_reasoning_prompt
To evaluate Base model:
python evaluate_Qwen2_VL_CVBench-base.py --model_path <path_to_your_model> \
--bs 8 \
--no-use_reasoning_prompt
To evaluate Instruct + GRPO model:
python evaluate_Qwen2_VL_CVBench.py --model_path <path_to_your_model> \
--bs 8 \
--use_reasoning_prompt
To evaluate Instruct model:
python evaluate_Qwen2_VL_CVBench.py --model_path <path_to_your_model> \
--bs 8 \
--no-use_reasoning_prompt
🔍 Resources
Full experiment log: Upcoming
Models CKPT: 🤗VisualThinker-R1-Zero at huggingface
:coffee: Stay Connected!
We are always open to engaging discussions, collaborations, or even just sharing a virtual coffee. To get in touch or join our team, visit TurningPoint AI's homepage for contact information.
📖 Acknowledgements
We sincerely thank DeepSeek, Open-R1, QwenVL, Open-R1-Multimodal, R1-V, SAT, and CV-Bench for providing open source resources that laid the foundation of our project.
🤝 Contributors
Here are the key contributors from TurningPoint AI to this project:
Hengguang Zhou1* , Xirui Li1* , Ruochen Wang1† , Minhao Cheng2, Tianyi Zhou3 and Cho-Jui Hsieh14
* Project Leads, † Main Advisor 1University of California, Los Angeles, 2Penn State University, 3University of Maryland and 4Google Research
:white_check_mark: Cite
If you find our work useful for your projects, please kindly cite the following BibTeX:
@misc{zhou2025r1zerosahamomentvisual,
title={R1-Zero's "Aha Moment" in Visual Reasoning on a 2B Non-SFT Model},
author={Hengguang Zhou and Xirui Li and Ruochen Wang and Minhao Cheng and Tianyi Zhou and Cho-Jui Hsieh},
year={2025},
eprint={2503.05132},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2503.05132},
}
Metadata
Owner
Metadata
Explore the Multimodal “Aha Moment” on 2B Model