server
 server copied to clipboard
server copied to clipboard
Unexpected shape for input 'TEXT' for model 'ensemble_model'. Expected [-1,-1], got [2]
Description I'm able to deploy fine-tuned "bert-base-uncased" model on Triton inference server and wants to implement dynamic batching then while inference I am getting a following error.
Error details InferenceServerException: unexpected shape for input 'TEXT' for model 'ensemble_model'. Expected [-1,-1], got [2]
I understand that first dimension is batch_size and second dimension is sequence_length hence I tried reshaping the query.set_data_from_numpy(np.asarray([sentence] * batch_size, dtype=object).reshape(batch_size, 1)) so it has a shape of (2,1) which is expected by the model but I observed that length of requests in tokenizer model.py script is 1 but I expect it to be 2 because we are sending a batch of 2 requests.
I think we have to correct the client script to send the sequences in batch. Kindly request you help me on this issue.
Triton Information Triton Server Version 2.22.0 NVIDIA Release 22.05
Using Triton container: '007439368137.dkr.ecr.us-east-2.amazonaws.com/sagemaker-tritonserver:22.05-py3'
Preprocessing config file name: "tokenizer" max_batch_size: 8 backend: "python"
input [ { name: "TEXT" data_type: TYPE_STRING dims: [-1] } ]
output [ { name: "input_ids" data_type: TYPE_INT64 dims: [-1] }, { name: "attention_mask" data_type: TYPE_INT64 dims: [-1] }, { name: "token_type_ids" data_type: TYPE_INT64 dims: [-1] } ]
instance_group [ { count: 1 kind: KIND_GPU } ] dynamic_batching { }
Client script
def run_inference(sentence, model_name='ensemble_model', url='127.0.0.1:8000', model_version='1'):
triton_client = tritonclient.http.InferenceServerClient(url=url, verbose=VERBOSE)`
model_metadata = triton_client.get_model_metadata(model_name=model_name, model_version=model_version)
model_config = triton_client.get_model_config(model_name=model_name, model_version=model_version)
batch_size = 2
query = tritonclient.http.InferInput(name="TEXT", shape=(batch_size,), datatype="BYTES")
model_score = tritonclient.http.InferRequestedOutput(name="score", binary_data=False)
query.set_data_from_numpy(np.asarray([sentence] * batch_size, dtype=object))
response = triton_client.infer(
model_name=model_name, model_version=model_version, inputs=[query], outputs=[model_score]
)
embeddings = response.as_numpy('score')
Expected behavior I would like to send dynamic batches to preprocessor/tokenizer model then tokenize the each batch request then send the "input_ids", "token_type_ids" and "attention_mask" to BERT model to get the model predictions.
Thanks in advance.
Hi @alxmamaev @dyastremsky @Tabrizian @rmccorm4
Hope you are doing well. Could anyone please address this issue?
Thank you.
To clarify, are you asking why there is only one request object being sent when you expect it to be 2 because of batching? With dynamic batching, the first dimension is the batch size. Since you are sending a request of size [2, 1], there is only one request. The dynamic batcher will batch the requests on the first dimension up to your max_batch_size (e.g. if it's 8... it'll wait up to the max delay and take care of batching them for you) and your model should be able to handle them, then it'll send the response(s) back. In this case, there would only be one response (representing your 2 batched requests).
Dynamic batching is something that happens inside Triton. It helps with maximizing throughput. The server will still treat your requests as individual requests and send back the associated responses. It will not break up the request into multiple objects. It has no concept of batching, just that it's receiving your request and sending back the associated response.
@dyastremsky Please correct my understanding.
If we set max_batch_size: 0
then this means that our deployed model will not be supporting batch inference. We can set the exact dimension dims: [ 1 ] for input_TEXT which means we can send single input text in one request.
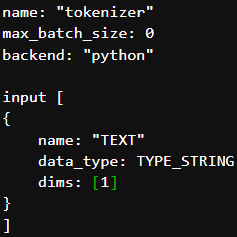
then we can set the exact dimension dims: [ 2 ] for input_TEXT which means we can send two input text in one request.
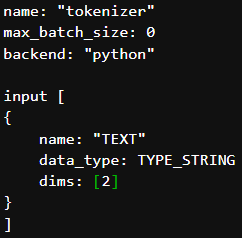
then we can set the dimension dims: [ -1 ] for input_TEXT which means we can send any number of input text in one request.
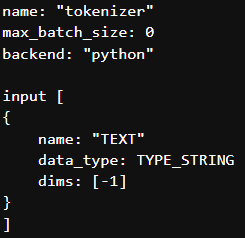
Note: There would be only one request in all above cases.
If we set max_batch_size: 2 it means that we can send up to 2 input text (requests) with some delay and it's batched accordingly.
then what could be dim for TEXT in config.pbtxt and please correct my client script to send 2 input texts (requests)?
FYI: I did define the following config then I'm getting following error InferenceServerException: unexpected shape for input 'TEXT' for model 'ensemble_model'. Expected [-1,-1], got [1]
I used client script which I shared in my previous comment to test this dynamic batching feature.
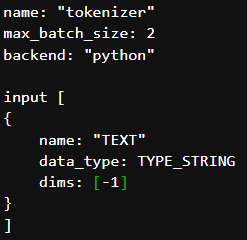
Thanks
Your understanding is correct. I believe the default delay is 0ms, so if you want to increase it, see here for the config fields: https://github.com/triton-inference-server/server/blob/main/docs/user_guide/model_configuration.md#delayed-batching
As far as the dimensions, enabling dynamic batching (i.e. setting max_batch_size >0) means that your input has an extra dimension of -1 appended as the first dimension. So say your max_batch_size was 2 and your non-batch dimensions were [2, 3], you'd need to submit requests with dimensions [-1, 2, 3], where -1 is a variable dimension (up to 2). With what you're trying to do here, I think your dimensions in the config would be blank and that should work.
@dyastremsky I tried it with following options.
- As you suggested, I tried setting dims blank in config file then I'm getting following error.
E0926 17:37:41.418746 1 model_lifecycle.cc:596] failed to load 'tokenizer' version 1: Invalid argument: model input must specify 'dims' for tokenizer
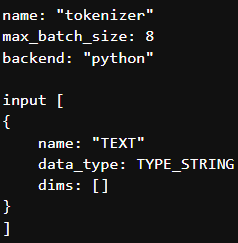
- I also tried not setting the dims then getting following error.
E0926 17:41:52.189095 1 model_lifecycle.cc:596] failed to load 'tokenizer' version 1: Invalid argument: model input must specify 'dims' for tokenizer
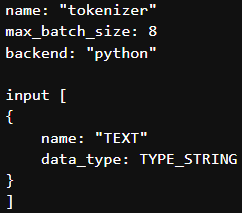
- Finally I tried setting the dims : [1] then as expected getting shape mismatch error.
InferenceServerException: [request id: <id_unknown>] unexpected shape for input 'TEXT' for model 'ensemble_model'. Expected [-1,1], got [1]
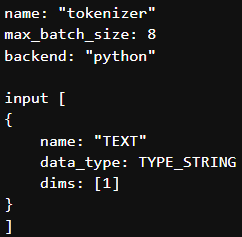
FYI: I tried it with latest 22.08 triton container.
Could you please help on this issue?
Thanks
Apologies, I wasn't sure if you could submit empty dimensions and I guess you can't. And I'm thinking that's probably not what you're aiming for... as that means you're just sending the batch size for each request, but no values.
I'm looking at this a bit closer. Your original intuition is correct. The batch size you should be sending is the batch dimension and the values (e.g. [2, 1]). It looks like your script is missing the second dimension: InferInput(name="TEXT", shape=(batch_size,), datatype="BYTES") should be InferInput(name="TEXT", shape=(batch_size,second_dimension), datatype="BYTES").
String test for reference, in case helpful: https://github.com/triton-inference-server/server/blob/main/qa/L0_string_io/string_client_test.py
No worries. Let me clarify in details.
- If we set
max_batch_size: 0then we know that deployed model will not be supporting batch inference.
Client script:
InferInput(name="TEXT", shape=(batch_size,), datatype="BYTES")
Which means I can send only one Text to model, if we look at above script then first dimension is batch_size (as per above screenshot it's 1) and second dimension is length of Text which is dynamic hence I kept it empty in above script.
FYI: Able to process inference request with above inference script and config so we are good with this use case.
I request you to focus only on Dynamic batching feature.
- Dynamic batching: If we set
max_batch_size: 8it means that we can send up to 8 input text (requests) with some delay and it's batched accordingly.
Client script: We know that server can batch up to 8 input text and send it for inference but since it's not working I'm trying with batch_size=2 to understand dynamic batching feature.
InferInput(name="TEXT", shape=(batch_size,), datatype="BYTES") where batch_size=2.
I think we have to set dims: [1] in config file, but unfortunately we are getting following error. InferenceServerException: [request id: <id_unknown>] unexpected shape for input 'TEXT' for model 'ensemble_model'. Expected [-1,1], got [2]
Is there a bug in Triton inference server or are we missing something?
Please help in clarifying queries below.
- What dims we have to set for Text which is of type String in config file?
- Can we use this inference script -
InferInput(name="TEXT", shape=(batch_size,), datatype="BYTES")to utilize dynamic batching feature (For ex: batch_size=2)?
FYI: I'm passing Input Text as string to tokenizer because we have to handle tokenization on server side then get the model predictions and post-process it and return response to client.
Thanks
Your first example worked because you included all your dimensions. Since there was no batching, your full dimensions were [1] and you sent one token along with dimensions of [1].
You cannot skip a dimension just because it is variable. Triton allows you to specify a variable dimension, but it relies on you specifying it in the input header. If you are converting the tensor from a numpy array, the easiest way would be to grab the .shape to get your full dimensions. Looking at the error message, you'd be fine if you send a shape of [2, 1], for example.
In short:
- Your initial dimensions are fine. A max_batch_size of 8 makes sense. The input dimensions can be 1 if you expect it to be one token each time, or -1 if you plan to send multiple tokens as part of one request (not one batch).
- I think you just need to change the shape to include the second dimension. Give that a try if you can. I can look into this a bit more soon if that doesn't fix your issue.
Sorry, that's not how it is working. I think we can hop on a call and resolve.
@dyastremsky Can I set up a google meet for 10-15 mins to walk you through the issue?
If you need more hands-on support, you'll need to go through NVIDIA AI Enterprise Support. Including the link below, from the README:
Need enterprise support? NVIDIA global support is available for Triton Inference Server with the [NVIDIA AI Enterprise software suite](https://www.nvidia.com/en-us/data-center/products/ai-enterprise/).
I'm not sure where the issue or misunderstanding is happening otherwise, but that string client test should be a good starting place to look to see how to pass in batched strings.
Unfortunately, the engineering team can only provide support directly through this forum. If you need more immediate or direct support, I recommend looking into our NVIDIA AI Enterprise software suite.
A few of the engineers on the team who are more familiar with the setting up STRING input types will be back next week and may be able to help you further then.
From what I understand, you will need another dimension just for batching. The error lists exactly what it is expecting. Have you tried:
name: "tokenizer"
max_batch_size: 8
backend: "python"
input [
{
name: "TEXT"
data_type: TYPE_STRING
dims: [-1,-1]
}
]
The first [-1] is for the batch dimension, the second [-1] is for the STRING size.
@dyastremsky @dzier Thanks for the details.
@dzier dims: [-1,-1] will not work when we set max_batch_size: 8 because Triton will batch the requests up to 8 and it can't go beyond that hence we need to vomit the first dimension which is dynamic in this case.
@dyastremsky
Here is the correct configuration in case of dynamic batching enabled.
name: "tokenizer" max_batch_size: 8 backend: "python" input [ { name: "TEXT" data_type: TYPE_STRING dims: [-1] } ]
I fixed the shape issue by reshaping the input string on client script itself. When I send the 4 requests through for loop, expecting triton to batch 4 requests and return single response but it's returning 4 responses.
Current behavior: output: [['Hello world']] output: [['Hello world']] output: [['Hello world']] output: [['Hello world']]
Expected behavior: output: [['Hello world'], ['Hello world'], ['Hello world'], ['Hello world']]
I think we have to get only one response, this is what my understanding by going through your previous comments in this chat, The dynamic batcher will batch the requests on the first dimension up to your max_batch_size (e.g. if it's 8... it'll wait up to the max delay and take care of batching them for you) and your model should be able to handle them, then it'll send the response(s) back. In this case, there would only be one response (representing your 2 batched requests).
Could you please clarify the dynamic batching behavior?
Thanks
Thanks for updating us and clarifying, Vinayak. Apologies, I mis-wrote. You are correct: each request will have its own response. The batcher is a scheduling mechanism. Each request is treated as its own entity and will have its own response.
The first -1 is represents a dynamic, non-specific size. This is required for dynamic batching, regardless of max batch size. For example, if you have dynamic batching enabled and max batch size to eight, and the server receives 10 requests. Then it will batch the first 8 requests into single inference request and queue them up to be scheduled. The remaining 2 requests will then be queued up as second inference request with a batch size of 2.
Your model will need to handle variable batches up to the max batch size. Once the first inference request is serviced, the server reply to the 8 individual requests, since they came up individually. That is why you are seeing 4 different outputs. Because there were 4 requests. However, based on your configuration, those requests should have been batched internally as a single request with a batch size of 4.
Does this make sense?
Thanks for the details. @dzier
Need one more clarification.
For example, if you have dynamic batching enabled and max batch size to eight, and the server receives 10 requests. Then it will batch the first 8 requests into single inference request and queue them up to be scheduled. The remaining 2 requests will then be queued up as second inference request with a batch size of 2.
As per your example, server will batch the first 8 requests into single inference request which means model is predicting all of those 8 requests at once (prediction in parallel) then return 8 individual model predictions?
That's correct. Your model is responsible for handling the batch in parallel, but if it is able to do so (typically the case), then the predictions happen in parallel.
Closing issue due to lack of activity. Please re-open the issue if you would like to follow up with this.