server
 server copied to clipboard
server copied to clipboard
question about the priority in ratelimiter
Description
Priority serves as a weighting value to be used for prioritizing across all the instances of all the models. An instance with priority 2 will be given 1/2 the number of scheduling chances as an instance with priority 1.
The document of Rate Limiter Configuration: priority says that the rate limit priority config is control instance's priority across all models. But in the core code, i only found a priority_queue in the ModelContext, it look like that the rate limit priority only control the instance priority in the same model.
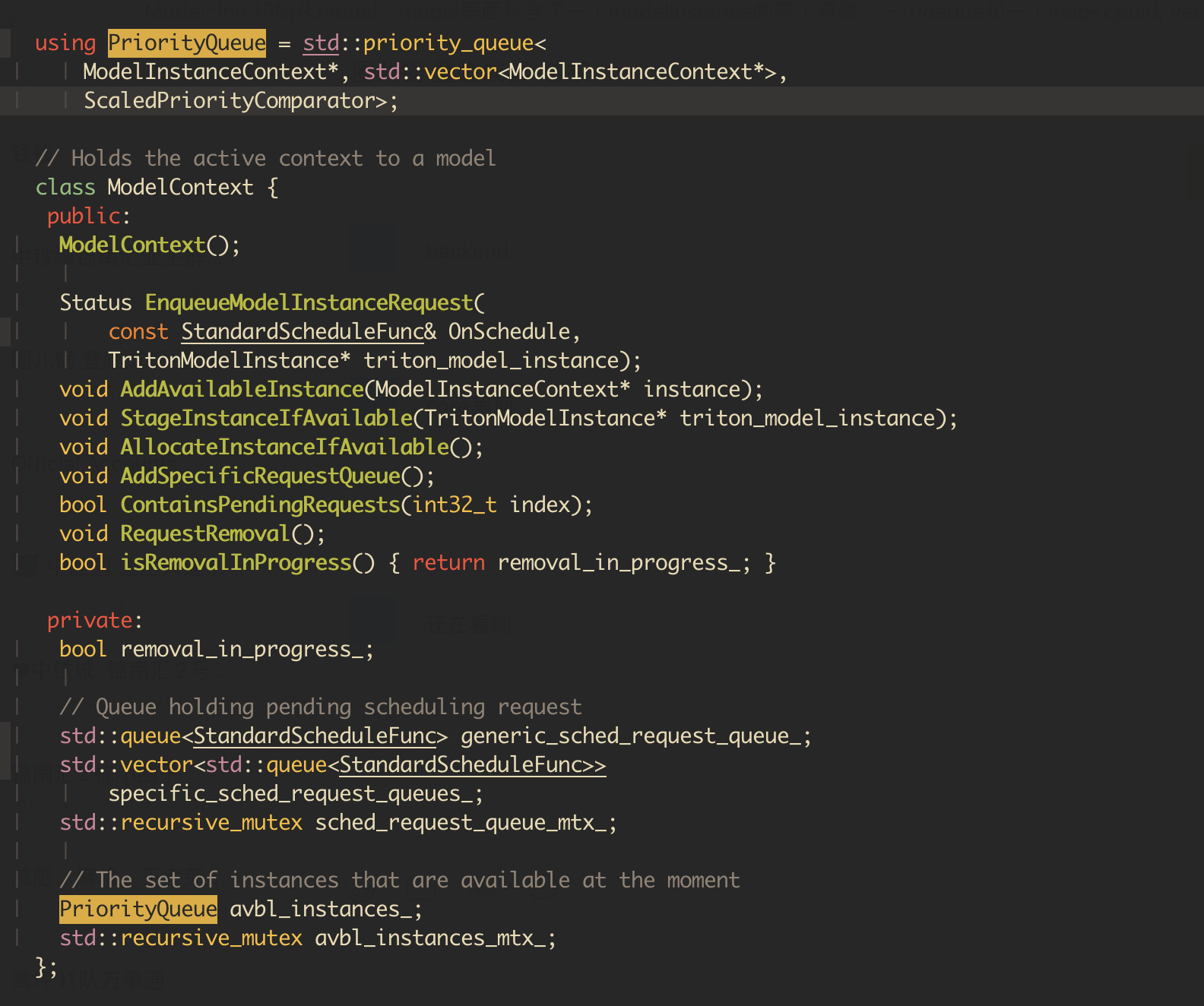
could some one give me some information about the implementation of the global priority control of model instance cross all models.
@sydnash avbl_instances_ are the instances that are available for the model. All model instances from different models goes through a global priority_queue called staged_instances_. This is how global priority is maintained across all models.
thanks, I got it. So the priority is relay on the resource that the limiter specified. One more question: let's assume we have to instance IA and IB, both arrived. IA has priority one, required resource A which is not available. IB has priority two, required resource B which is available. in this situation, IB still has to be execute after IA even IB and IA has no resource conflict and resource is available for IB. I guess it's a waste of resource B, may be we can execute IB first.
@sydnash
avbl_instances_are the instances that are available for the model. All model instances from different models goes through a global priority_queue called staged_instances_. This is how global priority is maintained across all models.
Sorry for missing your question.
in this situation, IB still has to be execute after IA even IB and IA has no resource conflict and resource is available for IB. I guess it's a waste of resource B, may be we can execute IB first.
I agree IB could be scheduled without waiting for IA in this case. This would require the logic to pass through all the staged instances in a loop keeping track of what resources higher priority model requests needs. If there are any requests that don't require these resources then we can schedule them. Instead of just trying to schedule the highest priority model instance. https://github.com/triton-inference-server/core/blob/main/src/rate_limiter.cc#L390-L396
These changes along with others might be useful to make the code more robust and handle these cases in a better way.
Thanks for sharing your suggestion!