alpaca-lora
 alpaca-lora copied to clipboard
alpaca-lora copied to clipboard
GPU training requiring at least 9G of vram?
I've tried single and multi GPU training on multiple gtx 1070s with 8G of vram. Only gets to a certain point and then crashes due to memory. Even with optimized flags.
I've tried a k80 with 12G of vram. I managed to get it at 9G and change. The problem is training for that takes 400 hours.
What settings should I used for 5 GTX 1070s with 8G of vram each? I have the vram total of 40, but apparently there's some hidden overhead that requires at least 9. Even with a batch size of 2 and a micro batch of 1.
You can use this command directly:
WORLD_SIZE=1 CUDA_VISIBLE_DEVICES=0,1,2,3,4 python finetune.py
The DDP will help to balance the VRAM of your GPUs.
If you train from checkpoint, add map_location='cuda:0' to the adapters_weights:
adapters_weights = torch.load(checkpoint_name,map_location='cuda:0')
And you can also group GPU 0-1 and GPU 2-4 in DDP for 2 Model Parallel.
Oh just world size 1? Not 5 for 5 GPUs?
WORLD SIZE=5 means the model will copy to all you GPUs.
Still not enough ram, but progress. I'm trying to change the batch_size instead of using the defaults, but I get errors like
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [12,0,0], thread: [97,0,0] Assertion idx_dim >= 0 && idx_dim < index_size && "index out of bounds" failed.
What is a proper batch/microbatch here that can use the least amount of memory possible? trying 5 and 1 and similar cause this error
Still not enough ram, but progress. I'm trying to change the batch_size instead of using the defaults, but I get errors like
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [12,0,0], thread: [97,0,0] Assertionidx_dim >= 0 && idx_dim < index_size && "index out of bounds"failed.What is a proper batch/microbatch here that can use the least amount of memory possible? trying 5 and 1 and similar cause this error
What is your progress? 7B only cost 8.7VRAM, the log seems like when index tensor gathering from GPUs occurred a OOM. You can try batch 64, micro 2. but 128 is fine for 5 GPUs
The progress got to the point where it loaded the model but then gave me an out of memory error visibly with cuda. This is a new one that started to appear when playing with the flags. I am thinking it may be the fact that im tweaking this and that a fraction is occuring somewhere, relating to https://stackoverflow.com/a/58259144 so im trying 4 gpus instead of 5
Though it's trange because I still get an error. And, it also appears that I get this error no matter what now...maybe a new model was pulled from the last time I restarted it.
===================================BUG REPORT===================================
Welcome to bitsandbytes. For bug reports, please run
python -m bitsandbytes
and submit this information together with your error trace to: https://github.com/TimDettmers/bitsandbytes/issues
================================================================================
bin /usr/local/lib/python3.10/dist-packages/bitsandbytes/libbitsandbytes_cuda118_nocublaslt.so
CUDA_SETUP: WARNING! libcudart.so not found in any environmental path. Searching in backup paths...
CUDA SETUP: CUDA runtime path found: /usr/local/cuda/lib64/libcudart.so
CUDA SETUP: Highest compute capability among GPUs detected: 6.1
CUDA SETUP: Detected CUDA version 118
CUDA SETUP: Loading binary /usr/local/lib/python3.10/dist-packages/bitsandbytes/libbitsandbytes_cuda118_nocublaslt.so...
Training Alpaca-LoRA model with params:
base_model: decapoda-research/llama-7b-hf
data_path: yahma/alpaca-cleaned
output_dir: /mnt/nfs/lora-alpaca
batch_size: 64
micro_batch_size: 16
num_epochs: 3
learning_rate: 0.0001
cutoff_len: 512
val_set_size: 2000
lora_r: 8
lora_alpha: 16
lora_dropout: 0.05
lora_target_modules: ['q_proj', 'v_proj']
train_on_inputs: True
add_eos_token: False
group_by_length: True
wandb_project:
wandb_run_name:
wandb_watch:
wandb_log_model:
resume_from_checkpoint: False
prompt template: alpaca
Loading checkpoint shards: 100%|██████████| 33/33 [00:30<00:00, 1.08it/s]
The tokenizer class you load from this checkpoint is not the same type as the class this function is called from. It may result in unexpected tokenization.
The tokenizer class you load from this checkpoint is 'LLaMATokenizer'.
The class this function is called from is 'LlamaTokenizer'.
Found cached dataset json (/root/.cache/huggingface/datasets/yahma___json/yahma--alpaca-cleaned-5d24553f76c14acc/0.0.0/fe5dd6ea2639a6df622901539cb550cf8797e5a6b2dd7af1cf934bed8e233e6e)
100%|██████████| 1/1 [00:00<00:00, 27.58it/s]
Loading cached split indices for dataset at /root/.cache/huggingface/datasets/yahma___json/yahma--alpaca-cleaned-5d24553f76c14acc/0.0.0/fe5dd6ea2639a6df622901539cb550cf8797e5a6b2dd7af1cf934bed8e233e6e/cache-45a7f72cdaee9ff3.arrow and /root/.cache/huggingface/datasets/yahma___json/yahma--alpaca-cleaned-5d24553f76c14acc/0.0.0/fe5dd6ea2639a6df622901539cb550cf8797e5a6b2dd7af1cf934bed8e233e6e/cache-c14794386159bdb7.arrow
trainable params: 4194304 || all params: 6742609920 || trainable%: 0.06220594176090199
0%| | 0/2331 [00:00<?, ?it/s]../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [0,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [1,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [2,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [3,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [4,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [5,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [6,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [7,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [8,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [9,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [10,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [11,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [12,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [13,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [14,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [15,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [16,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [17,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [18,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [19,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [20,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [21,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [22,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [23,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [24,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [25,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [26,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [27,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [28,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [29,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [30,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [31,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [32,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [33,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [34,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [35,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [36,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [37,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [38,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [39,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [40,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [41,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [42,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [43,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [44,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [45,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [46,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [47,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [48,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [49,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [50,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [51,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [52,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [53,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [54,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [55,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [56,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [57,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [58,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [59,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [60,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [61,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [62,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [63,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
Traceback (most recent call last):
File "/workspace/finetune.py", line 283, in <module>
fire.Fire(train)
File "/usr/local/lib/python3.10/dist-packages/fire/core.py", line 141, in Fire
component_trace = _Fire(component, args, parsed_flag_args, context, name)
File "/usr/local/lib/python3.10/dist-packages/fire/core.py", line 475, in _Fire
component, remaining_args = _CallAndUpdateTrace(
File "/usr/local/lib/python3.10/dist-packages/fire/core.py", line 691, in _CallAndUpdateTrace
component = fn(*varargs, **kwargs)
File "/workspace/finetune.py", line 273, in train
trainer.train(resume_from_checkpoint=resume_from_checkpoint)
File "/usr/local/lib/python3.10/dist-packages/transformers/trainer.py", line 1662, in train
return inner_training_loop(
File "/usr/local/lib/python3.10/dist-packages/transformers/trainer.py", line 1929, in _inner_training_loop
tr_loss_step = self.training_step(model, inputs)
File "/usr/local/lib/python3.10/dist-packages/transformers/trainer.py", line 2699, in training_step
loss = self.compute_loss(model, inputs)
File "/usr/local/lib/python3.10/dist-packages/transformers/trainer.py", line 2731, in compute_loss
outputs = model(**inputs)
File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/usr/local/lib/python3.10/dist-packages/peft/peft_model.py", line 663, in forward
return self.base_model(
File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/usr/local/lib/python3.10/dist-packages/accelerate/hooks.py", line 165, in new_forward
output = old_forward(*args, **kwargs)
File "/usr/local/lib/python3.10/dist-packages/transformers/models/llama/modeling_llama.py", line 687, in forward
outputs = self.model(
File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/usr/local/lib/python3.10/dist-packages/transformers/models/llama/modeling_llama.py", line 569, in forward
layer_outputs = torch.utils.checkpoint.checkpoint(
File "/usr/local/lib/python3.10/dist-packages/torch/utils/checkpoint.py", line 282, in checkpoint
return CheckpointFunction.apply(function, preserve, *args)
File "/usr/local/lib/python3.10/dist-packages/torch/autograd/function.py", line 506, in apply
return super().apply(*args, **kwargs) # type: ignore[misc]
File "/usr/local/lib/python3.10/dist-packages/torch/utils/checkpoint.py", line 111, in forward
outputs = run_function(*args)
File "/usr/local/lib/python3.10/dist-packages/transformers/models/llama/modeling_llama.py", line 565, in custom_forward
return module(*inputs, output_attentions, None)
File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/usr/local/lib/python3.10/dist-packages/accelerate/hooks.py", line 165, in new_forward
output = old_forward(*args, **kwargs)
File "/usr/local/lib/python3.10/dist-packages/transformers/models/llama/modeling_llama.py", line 292, in forward
hidden_states, self_attn_weights, present_key_value = self.self_attn(
File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/usr/local/lib/python3.10/dist-packages/accelerate/hooks.py", line 165, in new_forward
output = old_forward(*args, **kwargs)
File "/usr/local/lib/python3.10/dist-packages/transformers/models/llama/modeling_llama.py", line 204, in forward
query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)
File "/usr/local/lib/python3.10/dist-packages/transformers/models/llama/modeling_llama.py", line 136, in apply_rotary_pos_emb
cos = torch.gather(cos.repeat(gather_indices.shape[0], 1, 1, 1), 2, gather_indices)
RuntimeError: CUDA error: device-side assert triggered
Compile with `TORCH_USE_CUDA_DSA` to enable device-side assertions.
0%| | 0/2331 [00:07<?, ?it/s]
7B only cost 8.7VRAM
That might be related. I mean these gtx 1070s are 8G of vram
what's your PyTorch version?
I'm using the one in the container. My last build was about a month ago? I remade the docker image just a few minutes ago. Still the same result.
https://github.com/tloen/alpaca-lora/blob/main/Dockerfile#L16
Here are my args:
args:
- "finetune.py"
- "--base_model"
- "decapoda-research/llama-7b-hf"
- "--data_path"
- "yahma/alpaca-cleaned"
- "--output_dir"
- "/mnt/nfs/lora-alpaca"
- "--batch_size"
- "64"
- "--micro_batch_size"
- "2"
- "--num_epochs"
- "3"
- "--learning_rate"
- "1e-4"
- "--cutoff_len"
- "512"
- "--val_set_size"
- "2000"
- "--lora_r"
- "8"
- "--lora_alpha"
- "16"
- "--lora_dropout"
- "0.05"
- "--lora_target_modules"
- "[q_proj,v_proj]"
- "--train_on_inputs"
- "--group_by_length"
env:
- name: WORLD_SIZE
value: "1"
- name: CUDA_VISIBLE_DEVICES
value: "0,1,2,3,4"
- name: CUDA_LAUNCH_BLOCKING
value: "1"
I mean, it starts off fine:
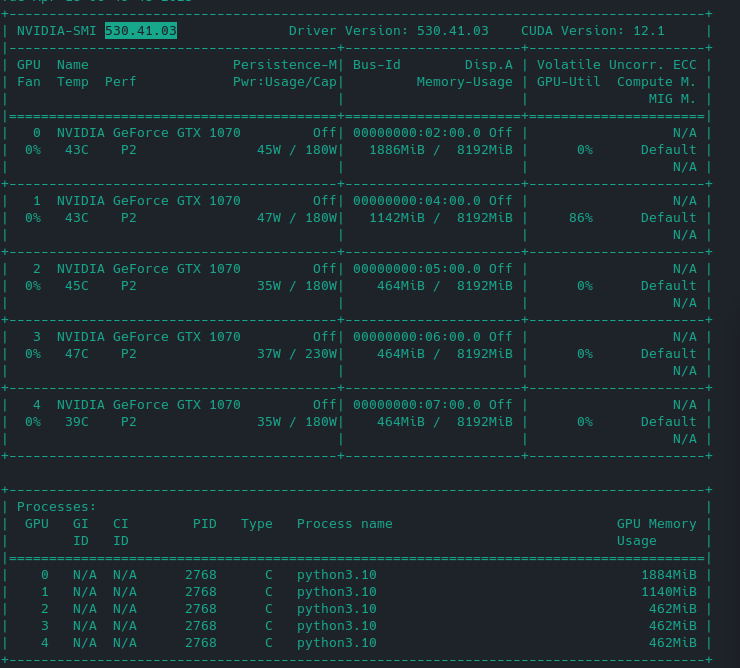 but then it hovers around here:
but then it hovers around here:
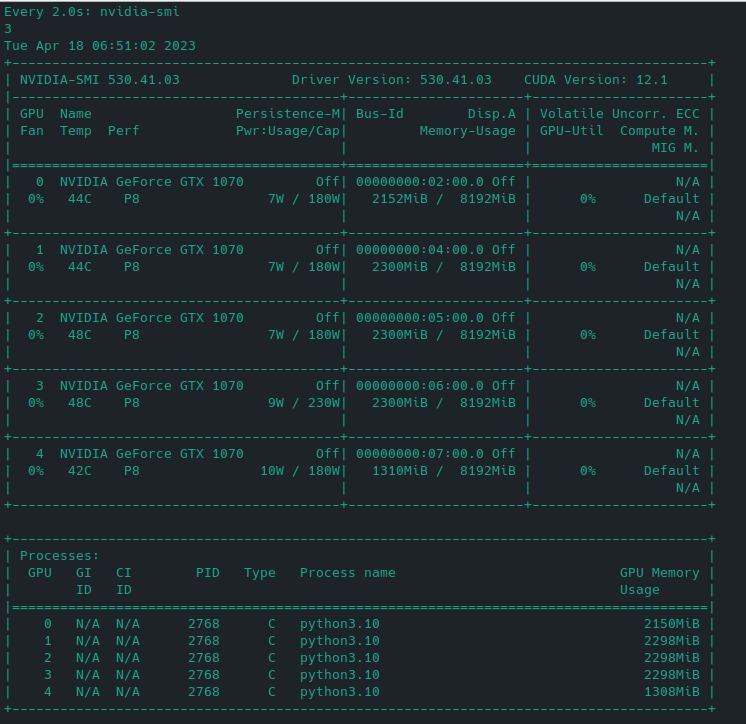 And crashes.
And crashes.
I even removed all args now. I had it past this point before which is what confuses me. I just removed all args. I wiped the directories too so there was no cache.
/usr/local/lib/python3.10/dist-packages/bitsandbytes/cuda_setup/main.py:145: UserWarning: WARNING: The following directories listed in your path were found to be non-existent: {PosixPath('/usr/local/nvidia/lib64'), PosixPath('/usr/local/nvidia/lib')}
warn(msg)
/usr/local/lib/python3.10/dist-packages/bitsandbytes/cuda_setup/main.py:145: UserWarning: /usr/local/nvidia/lib:/usr/local/nvidia/lib64 did not contain ['libcudart.so', 'libcudart.so.11.0', 'libcudart.so.12.0'] as expected! Searching further paths...
warn(msg)
/usr/local/lib/python3.10/dist-packages/bitsandbytes/cuda_setup/main.py:145: UserWarning: WARNING: The following directories listed in your path were found to be non-existent: {PosixPath('udp'), PosixPath('//10.111.138.143'), PosixPath('80')}
warn(msg)
/usr/local/lib/python3.10/dist-packages/bitsandbytes/cuda_setup/main.py:145: UserWarning: WARNING: The following directories listed in your path were found to be non-existent: {PosixPath('//10.96.0.1'), PosixPath('443'), PosixPath('tcp')}
warn(msg)
/usr/local/lib/python3.10/dist-packages/bitsandbytes/cuda_setup/main.py:145: UserWarning: WARNING: The following directories listed in your path were found to be non-existent: {PosixPath('//10.105.236.112'), PosixPath('8081'), PosixPath('tcp')}
warn(msg)
/usr/local/lib/python3.10/dist-packages/bitsandbytes/cuda_setup/main.py:145: UserWarning: WARNING: The following directories listed in your path were found to be non-existent: {PosixPath('80'), PosixPath('//10.96.135.77'), PosixPath('tcp')}
warn(msg)
/usr/local/lib/python3.10/dist-packages/bitsandbytes/cuda_setup/main.py:145: UserWarning: WARNING: The following directories listed in your path were found to be non-existent: {PosixPath('80'), PosixPath('//10.99.96.152'), PosixPath('tcp')}
warn(msg)
/usr/local/lib/python3.10/dist-packages/bitsandbytes/cuda_setup/main.py:145: UserWarning: WARNING: The following directories listed in your path were found to be non-existent: {PosixPath('//10.99.169.243'), PosixPath('tcp'), PosixPath('7860')}
warn(msg)
/usr/local/lib/python3.10/dist-packages/bitsandbytes/cuda_setup/main.py:145: UserWarning: WARNING: The following directories listed in your path were found to be non-existent: {PosixPath('//10.110.80.207'), PosixPath('80'), PosixPath('tcp')}
warn(msg)
/usr/local/lib/python3.10/dist-packages/bitsandbytes/cuda_setup/main.py:145: UserWarning: WARNING: The following directories listed in your path were found to be non-existent: {PosixPath('//10.104.44.120'), PosixPath('80'), PosixPath('tcp')}
warn(msg)
/usr/local/lib/python3.10/dist-packages/bitsandbytes/cuda_setup/main.py:145: UserWarning: WARNING: The following directories listed in your path were found to be non-existent: {PosixPath('80'), PosixPath('//10.100.76.193'), PosixPath('tcp')}
warn(msg)
/usr/local/lib/python3.10/dist-packages/bitsandbytes/cuda_setup/main.py:145: UserWarning: WARNING: The following directories listed in your path were found to be non-existent: {PosixPath('tcp'), PosixPath('80'), PosixPath('//10.111.193.69')}
warn(msg)
/usr/local/lib/python3.10/dist-packages/bitsandbytes/cuda_setup/main.py:145: UserWarning: WARNING: The following directories listed in your path were found to be non-existent: {PosixPath('80'), PosixPath('//10.96.239.151'), PosixPath('tcp')}
warn(msg)
/usr/local/lib/python3.10/dist-packages/bitsandbytes/cuda_setup/main.py:145: UserWarning: WARNING: The following directories listed in your path were found to be non-existent: {PosixPath('//10.99.169.243'), PosixPath('5000'), PosixPath('tcp')}
warn(msg)
/usr/local/lib/python3.10/dist-packages/bitsandbytes/cuda_setup/main.py:145: UserWarning: WARNING: The following directories listed in your path were found to be non-existent: {PosixPath('udp'), PosixPath('//10.111.138.143'), PosixPath('443')}
warn(msg)
/usr/local/lib/python3.10/dist-packages/bitsandbytes/cuda_setup/main.py:145: UserWarning: WARNING: The following directories listed in your path were found to be non-existent: {PosixPath('//10.103.84.25'), PosixPath('80'), PosixPath('tcp')}
warn(msg)
/usr/local/lib/python3.10/dist-packages/bitsandbytes/cuda_setup/main.py:145: UserWarning: Found duplicate ['libcudart.so', 'libcudart.so.11.0', 'libcudart.so.12.0'] files: {PosixPath('/usr/local/cuda/lib64/libcudart.so.11.0'), PosixPath('/usr/local/cuda/lib64/libcudart.so')}.. We'll flip a coin and try one of these, in order to fail forward.
Either way, this might cause trouble in the future:
If you get `CUDA error: invalid device function` errors, the above might be the cause and the solution is to make sure only one ['libcudart.so', 'libcudart.so.11.0', 'libcudart.so.12.0'] in the paths that we search based on your env.
warn(msg)
/usr/local/lib/python3.10/dist-packages/bitsandbytes/cuda_setup/main.py:145: UserWarning: WARNING: Compute capability < 7.5 detected! Only slow 8-bit matmul is supported for your GPU!
warn(msg)
===================================BUG REPORT===================================
Welcome to bitsandbytes. For bug reports, please run
python -m bitsandbytes
and submit this information together with your error trace to: https://github.com/TimDettmers/bitsandbytes/issues
================================================================================
bin /usr/local/lib/python3.10/dist-packages/bitsandbytes/libbitsandbytes_cuda118_nocublaslt.so
CUDA_SETUP: WARNING! libcudart.so not found in any environmental path. Searching in backup paths...
CUDA SETUP: CUDA runtime path found: /usr/local/cuda/lib64/libcudart.so.11.0
CUDA SETUP: Highest compute capability among GPUs detected: 6.1
CUDA SETUP: Detected CUDA version 118
CUDA SETUP: Loading binary /usr/local/lib/python3.10/dist-packages/bitsandbytes/libbitsandbytes_cuda118_nocublaslt.so...
Training Alpaca-LoRA model with params:
base_model: decapoda-research/llama-7b-hf
data_path: yahma/alpaca-cleaned
output_dir: /mnt/nfs/lora-alpaca
batch_size: 128
micro_batch_size: 4
num_epochs: 3
learning_rate: 0.0003
cutoff_len: 256
val_set_size: 2000
lora_r: 8
lora_alpha: 16
lora_dropout: 0.05
lora_target_modules: ['q_proj', 'v_proj']
train_on_inputs: True
add_eos_token: False
group_by_length: False
wandb_project:
wandb_run_name:
wandb_watch:
wandb_log_model:
resume_from_checkpoint: False
prompt template: alpaca
Loading checkpoint shards: 100%|██████████| 33/33 [00:23<00:00, 1.41it/s]
The tokenizer class you load from this checkpoint is not the same type as the class this function is called from. It may result in unexpected tokenization.
The tokenizer class you load from this checkpoint is 'LLaMATokenizer'.
The class this function is called from is 'LlamaTokenizer'.
Found cached dataset json (/root/.cache/huggingface/datasets/yahma___json/yahma--alpaca-cleaned-5d24553f76c14acc/0.0.0/fe5dd6ea2639a6df622901539cb550cf8797e5a6b2dd7af1cf934bed8e233e6e)
100%|██████████| 1/1 [00:00<00:00, 170.02it/s]
Loading cached split indices for dataset at /root/.cache/huggingface/datasets/yahma___json/yahma--alpaca-cleaned-5d24553f76c14acc/0.0.0/fe5dd6ea2639a6df622901539cb550cf8797e5a6b2dd7af1cf934bed8e233e6e/cache-45a7f72cdaee9ff3.arrow and /root/.cache/huggingface/datasets/yahma___json/yahma--alpaca-cleaned-5d24553f76c14acc/0.0.0/fe5dd6ea2639a6df622901539cb550cf8797e5a6b2dd7af1cf934bed8e233e6e/cache-c14794386159bdb7.arrow
trainable params: 4194304 || all params: 6742609920 || trainable%: 0.06220594176090199
0%| | 0/1164 [00:00<?, ?it/s]../aten/src/ATen/native/cuda/Loss.cu:241: nll_loss_forward_reduce_cuda_kernel_2d: block: [0,0,0], thread: [0,0,0] Assertion `t >= 0 && t < n_classes` failed.
../aten/src/ATen/native/cuda/Loss.cu:241: nll_loss_forward_reduce_cuda_kernel_2d: block: [0,0,0], thread: [1,0,0] Assertion `t >= 0 && t < n_classes` failed.
../aten/src/ATen/native/cuda/Loss.cu:241: nll_loss_forward_reduce_cuda_kernel_2d: block: [0,0,0], thread: [2,0,0] Assertion `t >= 0 && t < n_classes` failed.
../aten/src/ATen/native/cuda/Loss.cu:241: nll_loss_forward_reduce_cuda_kernel_2d: block: [0,0,0], thread: [3,0,0] Assertion `t >= 0 && t < n_classes` failed.
../aten/src/ATen/native/cuda/Loss.cu:241: nll_loss_forward_reduce_cuda_kernel_2d: block: [0,0,0], thread: [4,0,0] Assertion `t >= 0 && t < n_classes` failed.
../aten/src/ATen/native/cuda/Loss.cu:241: nll_loss_forward_reduce_cuda_kernel_2d: block: [0,0,0], thread: [5,0,0] Assertion `t >= 0 && t < n_classes` failed.
../aten/src/ATen/native/cuda/Loss.cu:241: nll_loss_forward_reduce_cuda_kernel_2d: block: [0,0,0], thread: [6,0,0] Assertion `t >= 0 && t < n_classes` failed.
../aten/src/ATen/native/cuda/Loss.cu:241: nll_loss_forward_reduce_cuda_kernel_2d: block: [0,0,0], thread: [7,0,0] Assertion `t >= 0 && t < n_classes` failed.
../aten/src/ATen/native/cuda/Loss.cu:241: nll_loss_forward_reduce_cuda_kernel_2d: block: [0,0,0], thread: [8,0,0] Assertion `t >= 0 && t < n_classes` failed.
../aten/src/ATen/native/cuda/Loss.cu:241: nll_loss_forward_reduce_cuda_kernel_2d: block: [0,0,0], thread: [9,0,0] Assertion `t >= 0 && t < n_classes` failed.
../aten/src/ATen/native/cuda/Loss.cu:241: nll_loss_forward_reduce_cuda_kernel_2d: block: [0,0,0], thread: [10,0,0] Assertion `t >= 0 && t < n_classes` failed.
../aten/src/ATen/native/cuda/Loss.cu:241: nll_loss_forward_reduce_cuda_kernel_2d: block: [0,0,0], thread: [11,0,0] Assertion `t >= 0 && t < n_classes` failed.
../aten/src/ATen/native/cuda/Loss.cu:241: nll_loss_forward_reduce_cuda_kernel_2d: block: [0,0,0], thread: [12,0,0] Assertion `t >= 0 && t < n_classes` failed.
../aten/src/ATen/native/cuda/Loss.cu:241: nll_loss_forward_reduce_cuda_kernel_2d: block: [0,0,0], thread: [13,0,0] Assertion `t >= 0 && t < n_classes` failed.
../aten/src/ATen/native/cuda/Loss.cu:241: nll_loss_forward_reduce_cuda_kernel_2d: block: [0,0,0], thread: [14,0,0] Assertion `t >= 0 && t < n_classes` failed.
../aten/src/ATen/native/cuda/Loss.cu:241: nll_loss_forward_reduce_cuda_kernel_2d: block: [0,0,0], thread: [15,0,0] Assertion `t >= 0 && t < n_classes` failed.
../aten/src/ATen/native/cuda/Loss.cu:241: nll_loss_forward_reduce_cuda_kernel_2d: block: [0,0,0], thread: [16,0,0] Assertion `t >= 0 && t < n_classes` failed.
../aten/src/ATen/native/cuda/Loss.cu:241: nll_loss_forward_reduce_cuda_kernel_2d: block: [0,0,0], thread: [17,0,0] Assertion `t >= 0 && t < n_classes` failed.
../aten/src/ATen/native/cuda/Loss.cu:241: nll_loss_forward_reduce_cuda_kernel_2d: block: [0,0,0], thread: [18,0,0] Assertion `t >= 0 && t < n_classes` failed.
../aten/src/ATen/native/cuda/Loss.cu:241: nll_loss_forward_reduce_cuda_kernel_2d: block: [0,0,0], thread: [19,0,0] Assertion `t >= 0 && t < n_classes` failed.
../aten/src/ATen/native/cuda/Loss.cu:241: nll_loss_forward_reduce_cuda_kernel_2d: block: [0,0,0], thread: [20,0,0] Assertion `t >= 0 && t < n_classes` failed.
../aten/src/ATen/native/cuda/Loss.cu:241: nll_loss_forward_reduce_cuda_kernel_2d: block: [0,0,0], thread: [21,0,0] Assertion `t >= 0 && t < n_classes` failed.
../aten/src/ATen/native/cuda/Loss.cu:241: nll_loss_forward_reduce_cuda_kernel_2d: block: [0,0,0], thread: [22,0,0] Assertion `t >= 0 && t < n_classes` failed.
../aten/src/ATen/native/cuda/Loss.cu:241: nll_loss_forward_reduce_cuda_kernel_2d: block: [0,0,0], thread: [23,0,0] Assertion `t >= 0 && t < n_classes` failed.
../aten/src/ATen/native/cuda/Loss.cu:241: nll_loss_forward_reduce_cuda_kernel_2d: block: [0,0,0], thread: [24,0,0] Assertion `t >= 0 && t < n_classes` failed.
../aten/src/ATen/native/cuda/Loss.cu:241: nll_loss_forward_reduce_cuda_kernel_2d: block: [0,0,0], thread: [25,0,0] Assertion `t >= 0 && t < n_classes` failed.
../aten/src/ATen/native/cuda/Loss.cu:241: nll_loss_forward_reduce_cuda_kernel_2d: block: [0,0,0], thread: [26,0,0] Assertion `t >= 0 && t < n_classes` failed.
../aten/src/ATen/native/cuda/Loss.cu:241: nll_loss_forward_reduce_cuda_kernel_2d: block: [0,0,0], thread: [27,0,0] Assertion `t >= 0 && t < n_classes` failed.
../aten/src/ATen/native/cuda/Loss.cu:241: nll_loss_forward_reduce_cuda_kernel_2d: block: [0,0,0], thread: [28,0,0] Assertion `t >= 0 && t < n_classes` failed.
../aten/src/ATen/native/cuda/Loss.cu:241: nll_loss_forward_reduce_cuda_kernel_2d: block: [0,0,0], thread: [29,0,0] Assertion `t >= 0 && t < n_classes` failed.
../aten/src/ATen/native/cuda/Loss.cu:241: nll_loss_forward_reduce_cuda_kernel_2d: block: [0,0,0], thread: [30,0,0] Assertion `t >= 0 && t < n_classes` failed.
../aten/src/ATen/native/cuda/Loss.cu:241: nll_loss_forward_reduce_cuda_kernel_2d: block: [0,0,0], thread: [31,0,0] Assertion `t >= 0 && t < n_classes` failed.
Traceback (most recent call last):
File "/workspace/finetune.py", line 283, in <module>
fire.Fire(train)
File "/usr/local/lib/python3.10/dist-packages/fire/core.py", line 141, in Fire
component_trace = _Fire(component, args, parsed_flag_args, context, name)
File "/usr/local/lib/python3.10/dist-packages/fire/core.py", line 475, in _Fire
component, remaining_args = _CallAndUpdateTrace(
File "/usr/local/lib/python3.10/dist-packages/fire/core.py", line 691, in _CallAndUpdateTrace
component = fn(*varargs, **kwargs)
File "/workspace/finetune.py", line 273, in train
trainer.train(resume_from_checkpoint=resume_from_checkpoint)
File "/usr/local/lib/python3.10/dist-packages/transformers/trainer.py", line 1662, in train
return inner_training_loop(
File "/usr/local/lib/python3.10/dist-packages/transformers/trainer.py", line 1929, in _inner_training_loop
tr_loss_step = self.training_step(model, inputs)
File "/usr/local/lib/python3.10/dist-packages/transformers/trainer.py", line 2699, in training_step
loss = self.compute_loss(model, inputs)
File "/usr/local/lib/python3.10/dist-packages/transformers/trainer.py", line 2731, in compute_loss
outputs = model(**inputs)
File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/usr/local/lib/python3.10/dist-packages/peft/peft_model.py", line 663, in forward
return self.base_model(
File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/usr/local/lib/python3.10/dist-packages/accelerate/hooks.py", line 165, in new_forward
output = old_forward(*args, **kwargs)
File "/usr/local/lib/python3.10/dist-packages/transformers/models/llama/modeling_llama.py", line 713, in forward
loss = loss_fct(shift_logits, shift_labels)
File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/loss.py", line 1174, in forward
return F.cross_entropy(input, target, weight=self.weight,
File "/usr/local/lib/python3.10/dist-packages/torch/nn/functional.py", line 3049, in cross_entropy
return torch._C._nn.cross_entropy_loss(input, target, weight, _Reduction.get_enum(reduction), ignore_index, label_smoothing)
RuntimeError: CUDA error: device-side assert triggered
Compile with `TORCH_USE_CUDA_DSA` to enable device-side assertions.
0%| | 0/1164 [00:09<?, ?it/s]
I commented out all the args too, so it was just this
- "finetune.py"
- "--base_model"
- "decapoda-research/llama-7b-hf"
- "--data_path"
- "yahma/alpaca-cleaned"
- "--output_dir"
- "/mnt/nfs/lora-alpaca"
apiVersion: batch/v1
kind: Job
metadata:
name: finetune-job
spec:
template:
metadata:
name: finetune-job
spec:
containers:
- name: finetune-container
image: my.local.registry/library/alpaca-lora:latest
imagePullPolicy: Always
args:
- "finetune.py"
- "--base_model"
- "decapoda-research/llama-7b-hf"
- "--data_path"
- "yahma/alpaca-cleaned"
- "--output_dir"
- "/mnt/nfs/lora-alpaca"
# - "--batch_size"
# - "64"
# - "--micro_batch_size"
# - "2"
# - "--num_epochs"
# - "3"
# - "--learning_rate"
# - "1e-4"
# - "--cutoff_len"
# - "512"
# - "--val_set_size"
# - "2000"
# - "--lora_r"
# - "8"
# - "--lora_alpha"
# - "16"
# - "--lora_dropout"
# - "0.05"
# - "--lora_target_modules"
# - "[q_proj,v_proj]"
# - "--train_on_inputs"
# - "--group_by_length"
env:
- name: WORLD_SIZE
value: "1"
- name: CUDA_VISIBLE_DEVICES
value: "0,1,2,3,4"
- name: CUDA_LAUNCH_BLOCKING
value: "1"
resources:
limits:
nvidia.com/gpu: 5
# memory: 30Gi
requests:
cpu: 500m
memory: 10Gi
volumeMounts:
- name: nfs-volume
mountPath: "/mnt/nfs"
- name: huggingface-cache
mountPath: "/root/.cache"
volumes:
- name: nfs-volume
nfs:
server: 192.168.6.10
path: /nfs
- name: huggingface-cache
hostPath:
path: /mnt/anaconda/.cache
type: DirectoryOrCreate
restartPolicy: Never
backoffLimit: 1
---
For reference, I made this k8s job to test. I was having incredible amounts of trouble running this locally without a container.
```yaml apiVersion: batch/v1 kind: Job metadata: name: finetune-job spec: template: metadata: name: finetune-job spec: containers: - name: finetune-container image: my.local.registry/library/alpaca-lora:latest imagePullPolicy: Always args: - "finetune.py" - "--base_model" - "decapoda-research/llama-7b-hf" - "--data_path" - "yahma/alpaca-cleaned" - "--output_dir" - "/mnt/nfs/lora-alpaca" # - "--batch_size" # - "64" # - "--micro_batch_size" # - "2" # - "--num_epochs" # - "3" # - "--learning_rate" # - "1e-4" # - "--cutoff_len" # - "512" # - "--val_set_size" # - "2000" # - "--lora_r" # - "8" # - "--lora_alpha" # - "16" # - "--lora_dropout" # - "0.05" # - "--lora_target_modules" # - "[q_proj,v_proj]" # - "--train_on_inputs" # - "--group_by_length" env: - name: WORLD_SIZE value: "1" - name: CUDA_VISIBLE_DEVICES value: "0,1,2,3,4" - name: CUDA_LAUNCH_BLOCKING value: "1" resources: limits: nvidia.com/gpu: 5 # memory: 30Gi requests: cpu: 500m memory: 10Gi volumeMounts: - name: nfs-volume mountPath: "/mnt/nfs" - name: huggingface-cache mountPath: "/root/.cache" volumes: - name: nfs-volume nfs: server: 192.168.6.10 path: /nfs - name: huggingface-cache hostPath: path: /mnt/anaconda/.cache type: DirectoryOrCreate restartPolicy: Never backoffLimit: 1 ---For reference, I made this k8s job to test. I was having incredible amounts of trouble running this locally without a container.
I've never seen this before, that's rare issue, I googled "TORCH_USE_CUDA_DSA" and there are only 2 pages info.
You can get cheap GPU with a lot of Vram cloud providers such as runpod (larger GPUs) and vast.ai (smaller and cheaper, especially unverified, i run one a5000 now that costs just 0.1 usd per hour right now in order to solve this problem).
I got the same problem with 4X A100, solving right now.
You can try to use (of course change the vallues for your GPUs, they say that max mem is lower than 8GB for a few mb in the article bellow) :
from accelerate import infer_auto_device_map
device_map = infer_auto_device_map(my_model, max_memory={0: "10GiB", 1: "10GiB", "cpu": "30GiB"})
reference: https://huggingface.co/docs/accelerate/usage_guides/big_modeling
And I put this inside of fine-tune.py somewhere? Or a separate file? Or something else?
In the finetune.py, just before loading of the main model where device_map is defined (normal model not lora)
But I am training on A4000 now (just 1 so i do not need this), and I still get out of memory error when it tries to do something with weight, with dataset of 3000 lines. This happens almost at the end of the training, after around 45 minutes.
This has happened 2 times already, I am doing another run just in case.
I did not change anything in the code, except for the dataset values, but form is the same.
Yes it can't work even with single 16 GB with all default settings. It crashed 3 times. But it worked well with a 24 GB card, which is fine for me.
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 44.00 MiB (GPU 0; 15.73 GiB total capacity; 14.20 GiB already allocated; 8.00 MiB free; 14.77 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
I just don't understand. Inference even on larger models works fine but not training.
Inference is a way cheaper than training. I think you need to train it on newer GPUs with higher CUDA and driver version to be able to use all params as they are - e.g. I dunno, if paralelism things have implemented support on 1070 cards. The k80 doesn't have much memory bandwidth, cores and tflops, so 400hrs is expected time.
===================================BUG REPORT=================================== Welcome to bitsandbytes. For bug reports, please run python -m bitsandbytes and submit this information together with your error trace to: https://github.com/TimDettmers/bitsandbytes/issues ================================================================================ bin /usr/local/lib/python3.10/dist-packages/bitsandbytes/libbitsandbytes_cuda118_nocublaslt.so CUDA_SETUP: WARNING! libcudart.so not found in any environmental path. Searching in backup paths... CUDA SETUP: CUDA runtime path found: /usr/local/cuda/lib64/libcudart.so CUDA SETUP: Highest compute capability among GPUs detected: 6.1 CUDA SETUP: Detected CUDA version 118 CUDA SETUP: Loading binary /usr/local/lib/python3.10/dist-packages/bitsandbytes/libbitsandbytes_cuda118_nocublaslt.so... Training Alpaca-LoRA model with params: base_model: decapoda-research/llama-7b-hf data_path: yahma/alpaca-cleaned output_dir: /mnt/nfs/lora-alpaca batch_size: 64 micro_batch_size: 16 num_epochs: 3 learning_rate: 0.0001 cutoff_len: 512 val_set_size: 2000 lora_r: 8 lora_alpha: 16 lora_dropout: 0.05 lora_target_modules: ['q_proj', 'v_proj'] train_on_inputs: True add_eos_token: False group_by_length: True wandb_project: wandb_run_name: wandb_watch: wandb_log_model: resume_from_checkpoint: False prompt template: alpaca Loading checkpoint shards: 100%|██████████| 33/33 [00:30<00:00, 1.08it/s] The tokenizer class you load from this checkpoint is not the same type as the class this function is called from. It may result in unexpected tokenization. The tokenizer class you load from this checkpoint is 'LLaMATokenizer'. The class this function is called from is 'LlamaTokenizer'. Found cached dataset json (/root/.cache/huggingface/datasets/yahma___json/yahma--alpaca-cleaned-5d24553f76c14acc/0.0.0/fe5dd6ea2639a6df622901539cb550cf8797e5a6b2dd7af1cf934bed8e233e6e) 100%|██████████| 1/1 [00:00<00:00, 27.58it/s] Loading cached split indices for dataset at /root/.cache/huggingface/datasets/yahma___json/yahma--alpaca-cleaned-5d24553f76c14acc/0.0.0/fe5dd6ea2639a6df622901539cb550cf8797e5a6b2dd7af1cf934bed8e233e6e/cache-45a7f72cdaee9ff3.arrow and /root/.cache/huggingface/datasets/yahma___json/yahma--alpaca-cleaned-5d24553f76c14acc/0.0.0/fe5dd6ea2639a6df622901539cb550cf8797e5a6b2dd7af1cf934bed8e233e6e/cache-c14794386159bdb7.arrow trainable params: 4194304 || all params: 6742609920 || trainable%: 0.06220594176090199 0%| | 0/2331 [00:00<?, ?it/s]../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [0,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [1,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [2,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [3,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [4,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [5,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [6,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [7,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [8,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [9,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [10,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [11,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [12,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [13,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [14,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [15,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [16,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [17,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [18,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [19,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [20,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [21,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [22,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [23,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [24,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [25,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [26,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [27,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [28,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [29,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [30,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [31,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [32,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [33,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [34,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [35,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [36,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [37,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [38,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [39,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [40,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [41,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [42,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [43,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [44,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [45,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [46,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [47,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [48,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [49,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [50,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [51,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [52,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [53,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [54,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [55,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [56,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [57,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [58,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [59,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [60,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [61,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [62,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. ../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [70,0,0], thread: [63,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed. Traceback (most recent call last): File "/workspace/finetune.py", line 283, in <module> fire.Fire(train) File "/usr/local/lib/python3.10/dist-packages/fire/core.py", line 141, in Fire component_trace = _Fire(component, args, parsed_flag_args, context, name) File "/usr/local/lib/python3.10/dist-packages/fire/core.py", line 475, in _Fire component, remaining_args = _CallAndUpdateTrace( File "/usr/local/lib/python3.10/dist-packages/fire/core.py", line 691, in _CallAndUpdateTrace component = fn(*varargs, **kwargs) File "/workspace/finetune.py", line 273, in train trainer.train(resume_from_checkpoint=resume_from_checkpoint) File "/usr/local/lib/python3.10/dist-packages/transformers/trainer.py", line 1662, in train return inner_training_loop( File "/usr/local/lib/python3.10/dist-packages/transformers/trainer.py", line 1929, in _inner_training_loop tr_loss_step = self.training_step(model, inputs) File "/usr/local/lib/python3.10/dist-packages/transformers/trainer.py", line 2699, in training_step loss = self.compute_loss(model, inputs) File "/usr/local/lib/python3.10/dist-packages/transformers/trainer.py", line 2731, in compute_loss outputs = model(**inputs) File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 1501, in _call_impl return forward_call(*args, **kwargs) File "/usr/local/lib/python3.10/dist-packages/peft/peft_model.py", line 663, in forward return self.base_model( File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 1501, in _call_impl return forward_call(*args, **kwargs) File "/usr/local/lib/python3.10/dist-packages/accelerate/hooks.py", line 165, in new_forward output = old_forward(*args, **kwargs) File "/usr/local/lib/python3.10/dist-packages/transformers/models/llama/modeling_llama.py", line 687, in forward outputs = self.model( File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 1501, in _call_impl return forward_call(*args, **kwargs) File "/usr/local/lib/python3.10/dist-packages/transformers/models/llama/modeling_llama.py", line 569, in forward layer_outputs = torch.utils.checkpoint.checkpoint( File "/usr/local/lib/python3.10/dist-packages/torch/utils/checkpoint.py", line 282, in checkpoint return CheckpointFunction.apply(function, preserve, *args) File "/usr/local/lib/python3.10/dist-packages/torch/autograd/function.py", line 506, in apply return super().apply(*args, **kwargs) # type: ignore[misc] File "/usr/local/lib/python3.10/dist-packages/torch/utils/checkpoint.py", line 111, in forward outputs = run_function(*args) File "/usr/local/lib/python3.10/dist-packages/transformers/models/llama/modeling_llama.py", line 565, in custom_forward return module(*inputs, output_attentions, None) File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 1501, in _call_impl return forward_call(*args, **kwargs) File "/usr/local/lib/python3.10/dist-packages/accelerate/hooks.py", line 165, in new_forward output = old_forward(*args, **kwargs) File "/usr/local/lib/python3.10/dist-packages/transformers/models/llama/modeling_llama.py", line 292, in forward hidden_states, self_attn_weights, present_key_value = self.self_attn( File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 1501, in _call_impl return forward_call(*args, **kwargs) File "/usr/local/lib/python3.10/dist-packages/accelerate/hooks.py", line 165, in new_forward output = old_forward(*args, **kwargs) File "/usr/local/lib/python3.10/dist-packages/transformers/models/llama/modeling_llama.py", line 204, in forward query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids) File "/usr/local/lib/python3.10/dist-packages/transformers/models/llama/modeling_llama.py", line 136, in apply_rotary_pos_emb cos = torch.gather(cos.repeat(gather_indices.shape[0], 1, 1, 1), 2, gather_indices) RuntimeError: CUDA error: device-side assert triggered Compile with `TORCH_USE_CUDA_DSA` to enable device-side assertions. 0%| | 0/2331 [00:07<?, ?it/s]
How to solve it? I encountered the same problem. But I don't have this problem with 2 A100s on other servers, but this problem occurs with 8 A100s.