alpaca-lora
 alpaca-lora copied to clipboard
alpaca-lora copied to clipboard
Why add the following code snippet since it would bring some errors?
Why add the following code snippet in this commit since it would bring some errors? https://github.com/tloen/alpaca-lora/blob/main/finetune.py#L256-L261
old_state_dict = model.state_dict
model.state_dict = (
lambda self, *_, **__: get_peft_model_state_dict(
self, old_state_dict()
)
).__get__(model, type(model))
Error 1: Maximum recursion depth exceeded #37 Error 2: model.save_pretrained() produced a corrupted adapter_model.bin (only 443 B) with alpaca-lora 286
That code is a binding script that basically just says "Any time you try to get the model's state dict, get the peft_model's state dict instead".
I presume it's there due to some issue with the trainer not loading peft properly.
Ran into same issue in most recent train run, adapter_model.bin was only 443 B. Commenting out that section of code fixed the issue during training for me.
I dove the git history but it was not clear to me why it was added but removing it seems to fix finetune.py
@tloen Hi Eric J. Do you have any considerations or motivations to add the above code snippets?
It's interesting, my alpaca run produced a 36mb file, and had really good results. Then, when I merged it and tried to finetune my own custom dataset, the model refused to improve, and my adapter_model.bin was in the bytes.
Maybe the peft update broke this, too? I'll try to verify whether this is still necessary or not.
It's interesting, my alpaca run produced a 36mb file, and had really good results. Then, when I merged it and tried to finetune my own custom dataset, the model refused to improve, and my adapter_model.bin was in the bytes.
Maybe the peft update broke this, too? I'll try to verify whether this is still necessary or not.
+1. The performance is also poor when fine-tuning llama-7b with lora on alpaca_data.json.
I think it is also the problem of the peft update.
My results are the same as https://github.com/tloen/alpaca-lora/issues/326.
FYI I ran it on 8v100-32G and installed packages via :
pip uninstall peft -y
pip install git+https://github.com/huggingface/peft.git@e536616888d51b453ed354a6f1e243fecb02ea08
pip uninstall transformers -y
pip install git+https://github.com/huggingface/transformers.git@fe1f5a639d93c9272856c670cff3b0e1a10d5b2b
Update the training loss. I fine-tuned llama-7b with lora on alpaca_data.json three time. The training losses are shown as follows.
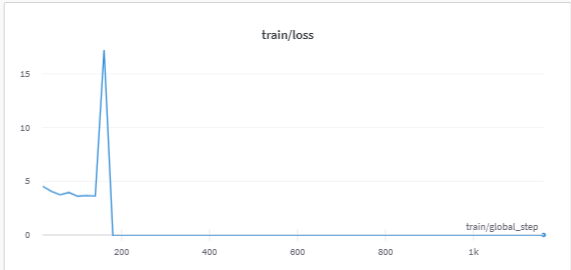
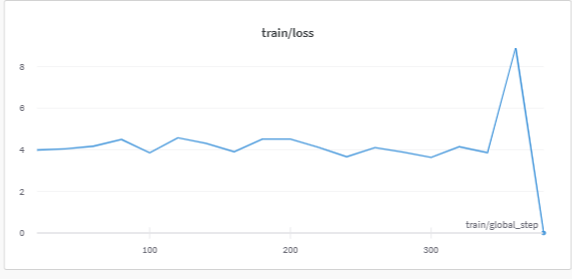
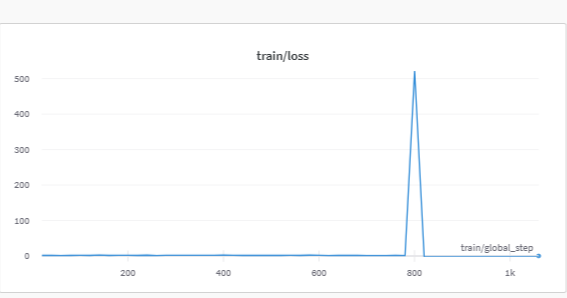
Trying to remove the script causes CUDA crashes on my end during training
Trying to remove the script causes CUDA crashes on my end during training
Do you mean comment/remove the following code?
old_state_dict = model.state_dict
model.state_dict = (
lambda self, *_, **__: get_peft_model_state_dict(
self, old_state_dict()
)
).__get__(model, type(model))
I am running some programs with commenting them.
Thanks!
I also saw some issues (https://github.com/tloen/alpaca-lora/issues/288, https://github.com/tloen/alpaca-lora/issues/170) discussing GPU type would affect the training process.
The root cause may be the peft update instead of GPU type. I think it is worth verifying.
Yes, it's a binding script.
Trying to remove the script causes CUDA crashes on my end during training
Do you mean comment/remove the following code?
old_state_dict = model.state_dict model.state_dict = ( lambda self, *_, **__: get_peft_model_state_dict( self, old_state_dict() ) ).__get__(model, type(model))I am running some programs with commenting them.
Hi, I comment them and model.save_pretrained() successfully saved adapter_model.bin. But, in each eval, the code saved the complete model (including the frozen part, e.g.,~6.58G). Before commenting, the code only saved LoRA part.
FYI:
peft == 0.3.0.dev0
transformers == 4.28.0.dev0
Thanks for your sharing! I think one quick solution is to install peft and transformer of the specified version. For example,
pip install git+https://github.com/huggingface/peft.git@xxxxxxx
pip install git+https://github.com/huggingface/transformers.git@xxxx
We can try multi-combinations of different packages versions.
Trying to remove the script causes CUDA crashes on my end during training
Do you mean comment/remove the following code?
old_state_dict = model.state_dict model.state_dict = ( lambda self, *_, **__: get_peft_model_state_dict( self, old_state_dict() ) ).__get__(model, type(model))I am running some programs with commenting them.
Hi, I comment them and model.save_pretrained() successfully saved adapter_model.bin. But, in each eval, the code saved the complete model (including the frozen part, e.g.,~6.58G). Before commenting, the code only saved LoRA part.
FYI:
peft == 0.3.0.dev0 transformers == 4.28.0.dev0
Installing old versions is not a permanent fix, especially with how new PEFT is. We're gonna want the new features
I commented the following code and fine-tuned llama-7b with lora on alpaca_data.json in 8V100. The training loss still became 0 at the iteration 560.
Is it a problem with multi-card running programs? Is it incorrect to run the program with torchrun?
finetune.py
...
# old_state_dict = model.state_dict
# model.state_dict = (
# lambda self, *_, **__: get_peft_model_state_dict(
# self, old_state_dict()
# )
# ).__get__(model, type(model))
# if torch.__version__ >= "2" and sys.platform != "win32":
# model = torch.compile(model)
....
Training script
WORLD_SIZE=${number_card} torchrun --nproc_per_node=${number_card} --master_port=13214 finetune.py \
--base_model='decapoda-research/llama-7b-hf' \
--num_epochs=10 \
--data_path ${data_filename} \
--cutoff_len=512 \
--output_dir=${output_dir} \
--lora_target_modules='[q_proj,k_proj,v_proj,o_proj]' \
--lora_r=16 \
--micro_batch_size=8 \
--wandb_project "Alpaca-Lora" 2>&1 |tee ${output_dir}/finetune.log
# --wandb_project "Alpaca-Lora-SE"
}
Training loss
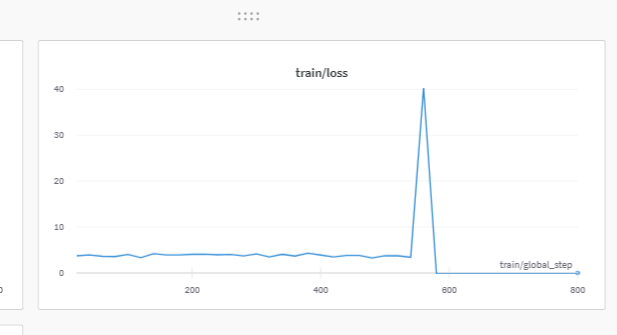
有趣的是,我的 alpaca run 产生了一个 36mb 的文件,并且取得了非常好的结果。然后,当我合并它并尝试微调我自己的自定义数据集时,模型拒绝改进,我的 adapter_model.bin 是字节。 也许 peft 更新也打破了这个?我会尝试验证这是否仍然有必要。
+1。在使用 lora on 微调 llama-7b 时,性能也很差
alpaca_data.json。 我认为这也是peft更新的问题。我的结果与#326相同。
仅供参考, 我在 8v100-32G 上运行它并通过以下方式安装软件包:
pip uninstall peft -y pip install git+https://github.com/huggingface/peft.git@e536616888d51b453ed354a6f1e243fecb02ea08 pip uninstall transformers -y pip install git+https://github.com/huggingface/transformers.git@fe1f5a639d93c9272856c670cff3b0e1a10d5b2b
It's interesting, my alpaca run produced a 36mb file, and had really good results. Then, when I merged it and tried to finetune my own custom dataset, the model refused to improve, and my adapter_model.bin was in the bytes. Maybe the peft update broke this, too? I'll try to verify whether this is still necessary or not.
+1. The performance is also poor when fine-tuning llama-7b with lora on
alpaca_data.json. I think it is also the problem of the peft update.My results are the same as #326.
FYI I ran it on 8v100-32G and installed packages via :
pip uninstall peft -y pip install git+https://github.com/huggingface/peft.git@e536616888d51b453ed354a6f1e243fecb02ea08 pip uninstall transformers -y pip install git+https://github.com/huggingface/transformers.git@fe1f5a639d93c9272856c670cff3b0e1a10d5b2b
@s1530129650 Hello, I have the same problem. Which versions of peft and transformers be used to solove the problem?
@s1530129650 Hello, I have the same problem. Which versions of peft and transformers be used to solove the problem?
Now I don't know sth
Trying to remove the script causes CUDA crashes on my end during training
Do you mean comment/remove the following code?
old_state_dict = model.state_dict model.state_dict = ( lambda self, *_, **__: get_peft_model_state_dict( self, old_state_dict() ) ).__get__(model, type(model))I am running some programs with commenting them.
Hi, I comment them and model.save_pretrained() successfully saved adapter_model.bin. But, in each eval, the code saved the complete model (including the frozen part, e.g.,~6.58G). Before commenting, the code only saved LoRA part.
FYI:
peft == 0.3.0.dev0 transformers == 4.28.0.dev0
I meet the same problem.
Hello, the correct way to save the intermediate checkpoints for PEFT when using Trainer would be to use Callbacks. An example is shown here: https://github.com/huggingface/peft/blob/main/examples/int8_training/peft_bnb_whisper_large_v2_training.ipynb
from transformers import Seq2SeqTrainer, TrainerCallback, TrainingArguments, TrainerState, TrainerControl
from transformers.trainer_utils import PREFIX_CHECKPOINT_DIR
class SavePeftModelCallback(TrainerCallback):
def on_save(
self,
args: TrainingArguments,
state: TrainerState,
control: TrainerControl,
**kwargs,
):
checkpoint_folder = os.path.join(args.output_dir, f"{PREFIX_CHECKPOINT_DIR}-{state.global_step}")
peft_model_path = os.path.join(checkpoint_folder, "adapter_model")
kwargs["model"].save_pretrained(peft_model_path)
pytorch_model_path = os.path.join(checkpoint_folder, "pytorch_model.bin")
if os.path.exists(pytorch_model_path):
os.remove(pytorch_model_path)
return control
trainer = Seq2SeqTrainer(
args=training_args,
model=model,
train_dataset=common_voice["train"],
eval_dataset=common_voice["test"],
data_collator=data_collator,
# compute_metrics=compute_metrics,
tokenizer=processor.feature_extractor,
callbacks=[SavePeftModelCallback],
)
model.config.use_cache = False # silence the warnings. Please re-enable for inference!
This should solve the below issue:
Hi, I comment them and model.save_pretrained() successfully saved adapter_model.bin. But, in each eval, the code saved the complete model (including the frozen part, e.g.,~6.58G). Before commenting, the code only saved LoRA part.
Hello, the correct way to save the intermediate checkpoints for PEFT when using Trainer would be to use Callbacks. An example is shown here: https://github.com/huggingface/peft/blob/main/examples/int8_training/peft_bnb_whisper_large_v2_training.ipynb
from transformers import Seq2SeqTrainer, TrainerCallback, TrainingArguments, TrainerState, TrainerControl from transformers.trainer_utils import PREFIX_CHECKPOINT_DIR class SavePeftModelCallback(TrainerCallback): def on_save( self, args: TrainingArguments, state: TrainerState, control: TrainerControl, **kwargs, ): checkpoint_folder = os.path.join(args.output_dir, f"{PREFIX_CHECKPOINT_DIR}-{state.global_step}") peft_model_path = os.path.join(checkpoint_folder, "adapter_model") kwargs["model"].save_pretrained(peft_model_path) pytorch_model_path = os.path.join(checkpoint_folder, "pytorch_model.bin") if os.path.exists(pytorch_model_path): os.remove(pytorch_model_path) return control trainer = Seq2SeqTrainer( args=training_args, model=model, train_dataset=common_voice["train"], eval_dataset=common_voice["test"], data_collator=data_collator, # compute_metrics=compute_metrics, tokenizer=processor.feature_extractor, callbacks=[SavePeftModelCallback], ) model.config.use_cache = False # silence the warnings. Please re-enable for inference!This should solve the below issue:
Hi, I comment them and model.save_pretrained() successfully saved adapter_model.bin. But, in each eval, the code saved the complete model (including the frozen part, e.g.,~6.58G). Before commenting, the code only saved LoRA part.
Elegant solution!
Comment the
old_state_dict = model.state_dict
model.state_dict = (
lambda self, *_, **__: get_peft_model_state_dict(
self, old_state_dict()
)
).__get__(model, type(model))
and use the Callback to save the PEFT params.