kurilab
## 論文概要 ポートレート画像のリライティングを行う。他の手法と違い形状や反射成分を推定する明示的な逆レンダリングステップを持たない。これはそのような方法はその推定モデルによって表現可能な結果に必然的に制限されるため。シーンの表現に物理的制約を課さず性能を向上させる。 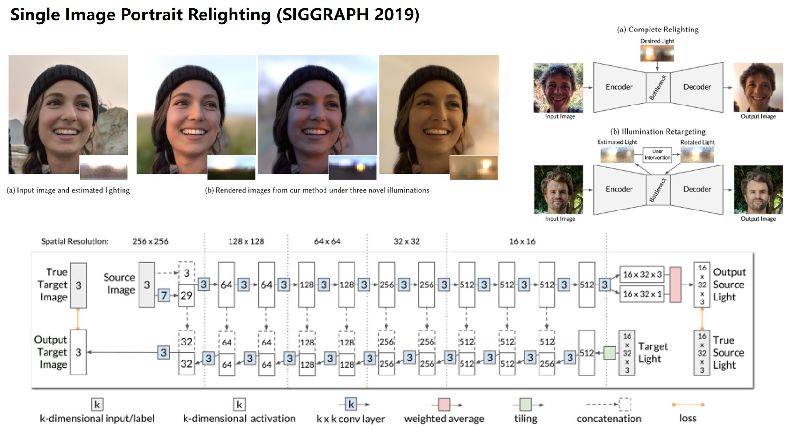 https://arxiv.org/abs/1905.00824 ## Code 未確認。
## 論文概要 リアルタイムで映像のポートレートのリライティングを行う。マルチタスクと敵対的学習戦略を組み合わせた構造と照明分離をすることで動的照明に対しロバスト性を担保している。またライトステージを使い603288枚のOLAT画像からなるデータセットを取得し公開。  https://zhanglongwen.com/projects/nvpr/ ## Code https://github.com/ZoneLikeWonderland/Neural-Video-Portrait-Relighting-in-Real-time-via-Consistency-Modeling ## Dataset https://zhanglongwen.com/projects/nvpr/dataset.html
## 論文概要 顔だけでない上半身ポートレート画像のリライティングを行う。LightMapと呼ばれる新しい画素単位の照明表現を導入しSOTA。アルベド推定において肌のアルベド色は強いPriorを持つためほぼ失敗しないが、衣服のアルベド推定は不正確になることがあるのがLimitation。  https://augmentedperception.github.io/total_relighting/ ## Code 未確認。
## 論文概要 1枚の顔画像のリライティングを行う。複数のチャンネルを個別に明示的にモデル化することにより特に鏡面反射と影を含む難しい照明に対してロバストになる。また高品質な3D顔とレンダリングチャネルからなる大規模なポートレートデータセットを提示。 またターゲットとなる照明を忠実にリライティング対象のポートレートに組み込むためのモジュール(Lighting-guided Feature Modulation)を提案。 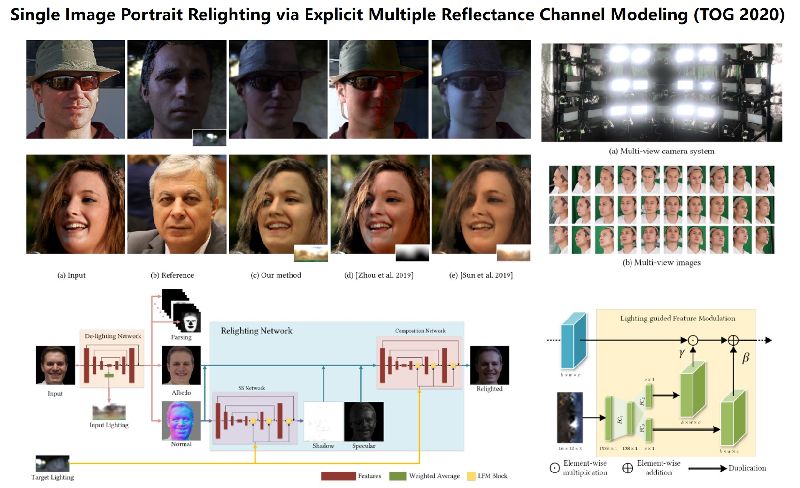 https://dl.acm.org/doi/abs/10.1145/3414685.3417824 ## Code 未確認 ## Dataset https://sireer.github.io/projects/FLM_project/
## 論文概要 1枚の画像から照明マップを推定する。既存研究で行われているように直接回帰をするのではなく、照明マップを球面光分布、光強度、環境光に分解しそれぞれへのパラメータ回帰タスクとして定義。また球面光分布間の距離をより正確に導出するための新しい球面移動損失を提案。  https://arxiv.org/abs/2012.11116 ## Code 未確認。
## 論文概要 顔のリライティングを行う。単なるEnd2Endの画像変換ではなく、まずアルベドと法線に分解を行い、入力した照明からShadingを計算し、拡散反射成分を得た後に、差分としての鏡面反射を残差成分として表現して、残差学習させるのがポイント。  https://openaccess.thecvf.com/content_CVPR_2020/html/Nestmeyer_Learning_Physics-Guided_Face_Relighting_Under_Directional_Light_CVPR_2020_paper.html ## 感想 シンプルなアイデアで余計な処理をしていない。
## 論文概要 十分に優れた合成データの生成シミュレータがあれば、実データを1枚も使わずに「合成データのみの学習」でSOTAと同程度の結果が得られると主張。特に難しい顔のレンダリングにおいて学習データを大量に合成・学習し、顔解析・ランドマーク推定において実証。 ドメインギャップを抑えた合成シミュレータを開発するには多くの専門知識と投資が必要だが、一度実装してしまえばそれ以降は最小限の努力で様々な学習データを生成可能。再ラベリングも容易。またHWのプロトタイプが存在しないカメラもシミュレートしてアルゴリズムを開発でき、更にHW設計にFBも可能。  https://openaccess.thecvf.com/content/ICCV2021/html/Wood_Fake_It_Till_You_Make_It_Face_Analysis_in_the_ICCV_2021_paper.html ## Dataset https://github.com/microsoft/FaceSynthetics
## 論文概要 マルチタスク学習(MTL)は一般的に全てのタスクのGTが得られる事が前提だが、1つのデータセットに全てのGTがないのが普通である。そこでそのような不完全なデータセットに対してもMTLを適用するための戦略を提示。具体的にはラベルがないタスクに対しては敵対的学習を用いる。  https://openaccess.thecvf.com/content/WACV2022/html/Wang_Semi-Supervised_Multi-Task_Learning_for_Semantics_and_Depth_WACV_2022_paper.html ## Code 未確認。
## 論文概要 セマセグタスクの新しいアプローチ。まず入力画像(WxH)の対象画素と同じクラスの画素と違うクラスの画素のバイナリマップ(WxHxWxH)を推定し、真値でロス取って監視させながらセマセグマップを学習する。Context Priorと呼ぶ。 従来では難しかったクラス内とクラス間のコンテキスト依存性を選択的に捉えることができるようになるので、ロバストな特徴表現を実現できる。当然性能はSOTA。CVPR2020採択。 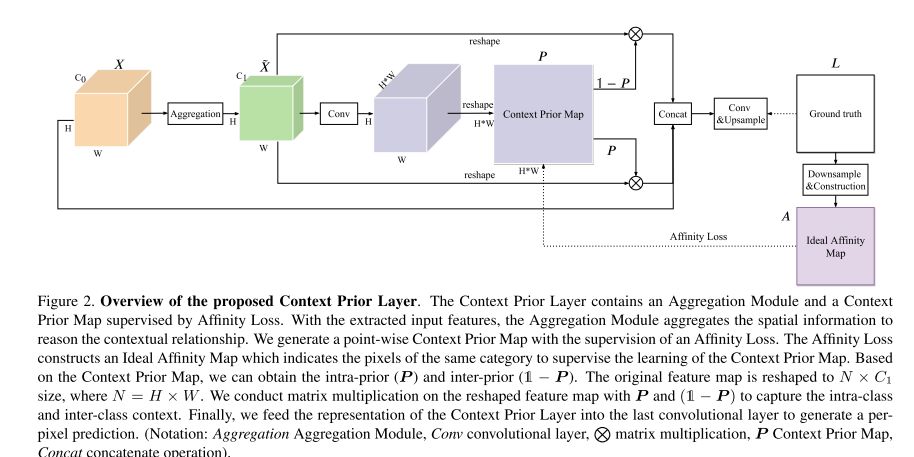 https://arxiv.org/abs/2004.01547 ## 感想 色々な応用ができそうで超面白い。
## 論文概要 透明物体のセグメンテーションは難しく、特に写真に印刷された透明物体と実際の透明物体を区別することは難しい。そこで偏光センサを用いて得られたマルチモーダル偏光情報をNNで学習させることで高精度な透明物体セグメンテーションを実現。シーン条件にロバスト。CVPR2020。 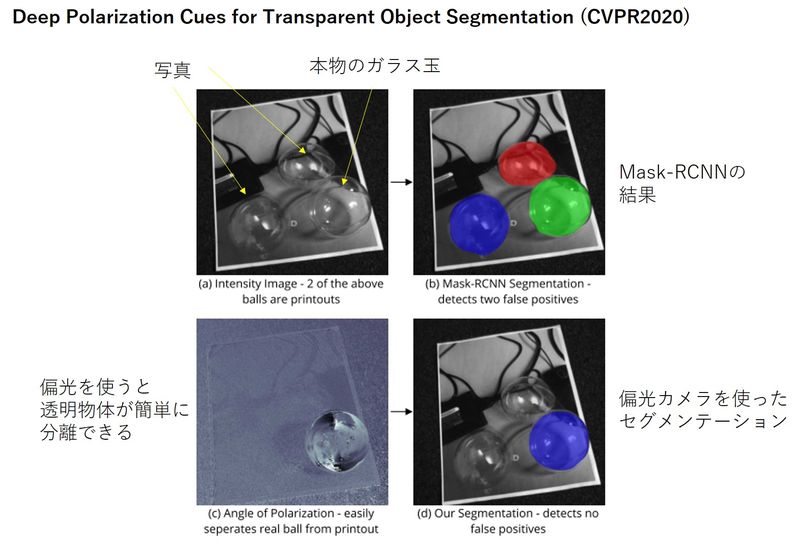 https://openaccess.thecvf.com/content_CVPR_2020/html/Kalra_Deep_Polarization_Cues_for_Transparent_Object_Segmentation_CVPR_2020_paper.html ## 感想 まず偏光が透明物体認識の課題に有効であるとローレベルで示してから、NNとの組み合わせを提案する流れ。