Thomas Kipf
Thomas Kipf
Have a look here at my previous works: https://scholar.google.com/citations?user=83HL5FwAAAAJ Aside from global gated pooling (in the recent MolGAN paper) and some form of self-attentive pooling (in the NRI paper), we...
Thanks for your questions. For graph-level classification you essentially have two options: * "hacky" version: you add a global node to the graph that is connected to all other nodes...
Hi, thanks for the catch. For the `featureless` mode, you have to set the input dimension of the first layer (only the first layer supports `featureless`) to be the number...
It might be a good idea to turn the regression problem into a classification problem by bucketing the real-valued targets into several classes. This typically (empirically) works quite well in...
That sounds interesting. What would 'r' be in this case?
This is not quite correct, you can build a block-diagonal sparse matrix representing multiple graph instances at once. You further need to introduce a sparse gathering matrix that pools representations...
The following figure should hopefully clarify the idea: 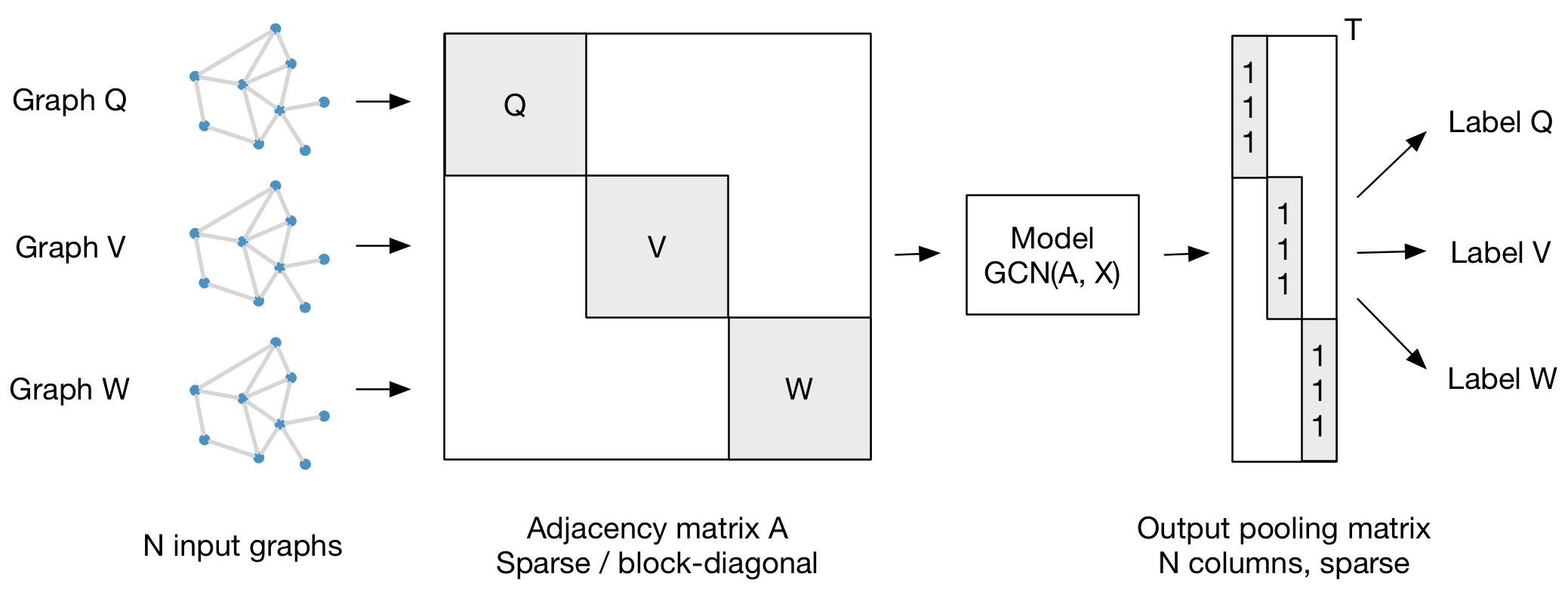
This is correct, but I would recommend training the model using smaller mini-batches of, say, 32 or 64 graphs each. Make sure the pooling matrix is also sparse and that...
I used this model quite some time ago for graph-level classification of the datasets provided in this paper: https://arxiv.org/abs/1605.05273 and got comparable (sometimes worse, sometimes better) results compared to their...
In order to go from node-level representation to a graph-level representation you will indeed have to perform some kind of order-invariant pooling operation. Any popular pooling strategy typically works fine,...