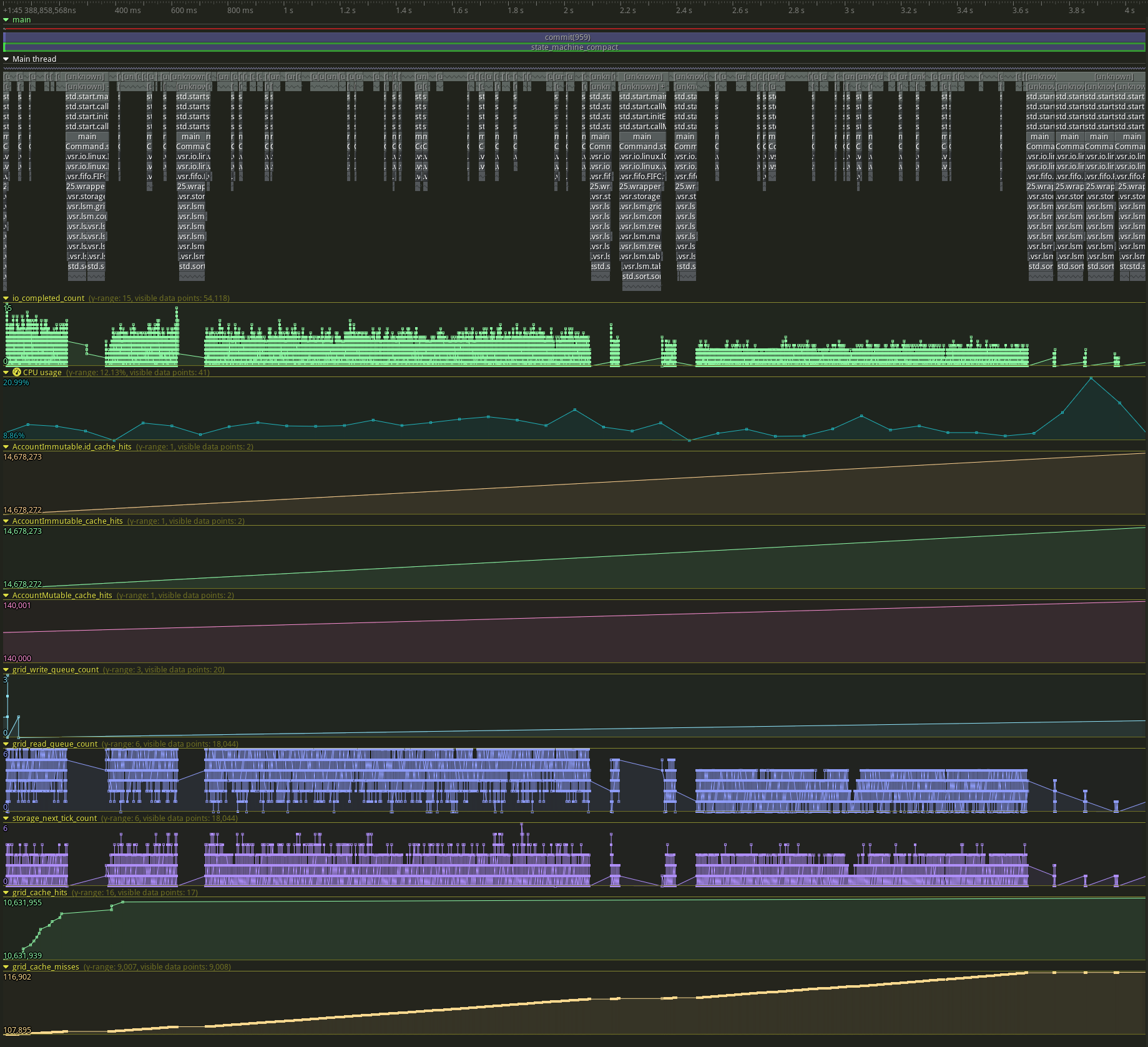
Compaction reads seem to entirely miss the grid cache.
Here's a sample trace zoomed in on a single compact. We see 17 hits and 9008 misses.
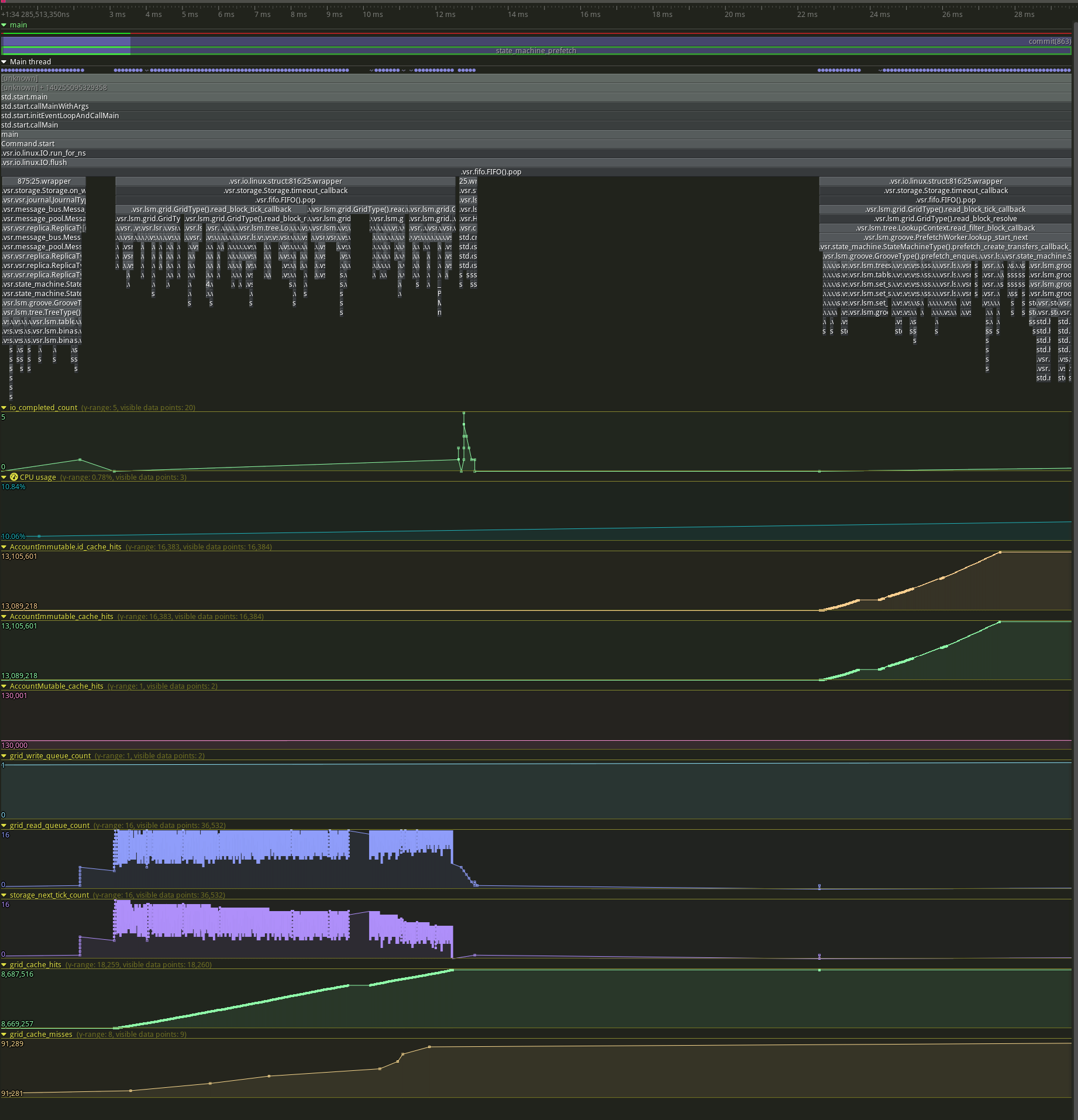
Compare to prefetching, with 18260 hits and 9 misses.
Possibly what we are seeing here is that account immutable gets hit constantly in this benchmark, which pushes all the transfer indexes out of cache. That's fine in itself, but it violates the assumption in https://github.com/tigerbeetledb/tigerbeetle/pull/244 that read bandwidth for compaction will usually be zero.
During compaction, we have to copy blocks from the grid cache into the compaction buffer to guard against reading an evicted block. If compaction is usually a cache miss anyway, perhaps it would make more sense to bypass the cache during compaction and then not have the extra copy.
We see 17 hits and 9008 misses.
This is exciting! It would explain the surprising performance.
Compare to prefetching, with 18260 hits and 9 misses.
This is great for prefetching, since, if I understand correctly, it shows either that our CLOCK N-th chance eviction policy is working efficiently, or else that we're not yet at the limits of the prefetch cache size there.
If compaction is usually a cache miss anyway, perhaps it would make more sense to bypass the cache during compaction and then not have the extra copy.
Let's first explore whether our grid cache sizes are simply tuned correctly. For example, a typical grid cache would be sized to be around 1 GiB for a “minimum viable deployment” i.e. something like a tiny VM in Digital Ocean.
But for something like an enterprise production deployment, and for our optimal benchmark, i.e. where we're going for high performance and 1M TPS, to find “the speed of light”... the best we could possibly do... then we would size the grid cache to be on the order of 16 GiB or 32 GiB, or whatever it takes (the lower the better of course).
Our grid cache takes the place of the kernel's page cache, so, on a beefy server, we should expect it to have access to most of the machine's RAM.
So we wouldn't artificially limit the size of the grid cache, if it means this reduces throughput. Rather, we'd tune to see how much grid cache we need to hit 1M TPS (and then, once we get there, we'd optimize to bring this cache size down, so that we stay at 1M TPS but with less and less cache).
As further motivation, coming at this from another angle, since an I/O is far more expensive than a cache miss, we shouldn't try to bypass the cache during compaction, to save the cache miss (but still pay the I/O). We should rather fix the cache subsystem in the first place so as to make sure that all compaction reads are coming from it.
CC'ing @sm2n also. Taking a thorough look at cache tunings is already something we were talking about last week, and something that @sm2n will be looking at in the next few days, to free you up for compaction pacing.
we shouldn't try to bypass the cache during compaction, to save the cache miss (but still pay the I/O)
The idea was not to save the cache miss, but to save the double copy in compaction that defends against cache eviction. Not necessary if the block wasn't cached anyway.
Also, in this workload the block is only ever accessed by compaction, so evicting some useful account block from the cache is wasteful.
Maybe another way to think about this: If a block was not in the cache, being touched by compaction does not indicate that it is likely to be read again in the future - in fact, it indicates that it will be garbage-collected soon. So if compaction doesn't find the block in the cache, maybe it shouldn't try to put it there.
The idea was not to save the cache miss, but to save the double copy in compaction that defends against cache eviction. Not necessary if the block wasn't cached anyway.
Thanks for the clarification. Agreed with you that this would be valuable.
Also, in this workload the block is only ever accessed by compaction, so evicting some useful account block from the cache is wasteful.
We should be able to tune CLOCK priority to be scan-resistant to compaction. i.e. We can insert compaction blocks at low-priority and let CLOCK figure out what's worth keeping, according to actual usage.
So if compaction doesn't find the block in the cache, maybe it shouldn't try to put it there.
This would be great to do too.
Something else I was thinking with the misses, is that they might just be negative lookups on the transfer path.
What is the size of the grid cache under test here @jamii ?
It should be sized to at least 16 GiB to match a realistic deployment as described above. This should be enough to keep the working set in memory w.r.t. accounts and hot indexes, and we shouldn't see misses. If it's not sized correctly, then we can expect evictions.
This is what I meant by "Let's first explore whether our grid cache sizes are simply tuned correctly.".
that they might just be negative lookups on the transfer path.
They happen during compaction, not during prefetch/commit, so they're definitely compaction misses. During prefetch it's almost all cache hits.
What is the size of the grid cache under test here @jamii ?
I think 128mb at the moment.
https://github.com/tigerbeetledb/tigerbeetle/issues/560 does seem to indicate that compactions are trashing the grid cache.
We can insert compaction blocks at low-priority and let CLOCK figure out what's worth keeping, according to actual usage.
I think the problem here is not just the low cache size, which we'll tweak soon, but that our usage is serial. Even with the small database above we do ~10k cache lookups/inserts during compaction, and then we do ~20k cache lookups/inserts during each of the next 64 prefetches. So even with blocks being inserted at low priority (currently all new inserts get count=1), every compaction insert is ticking down prefetch clocks and vice versa.
Serial compaction will change this, because compaction and prefetch will be interleaved. I have no guesses for what the new dynamic will be.
I reran with a 16gb grid cache (and verified the increased memory usage).
Here's the last big compaction.
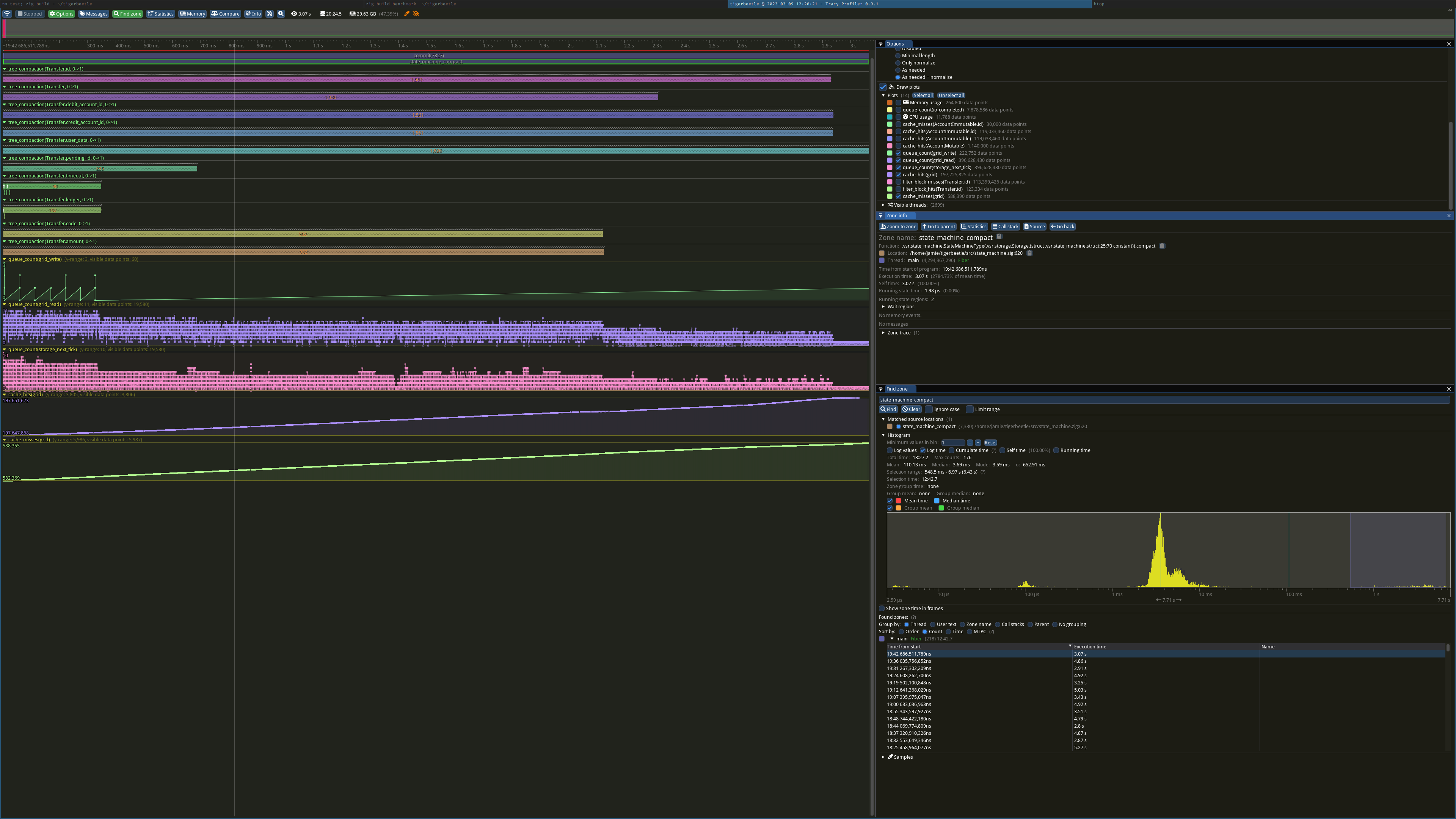
3s long. ~6k misses vs ~4k hits.
The database file is 62gb so only 25% of blocks can be cached in this benchmark. The transfer indexes don't have any deletes, so compaction rates will be the similar for each level (rather than most compactions happening at the top level which is then mostly cached). I think we have to expect that as the database gets larger, most of the compaction inputs will not be cached.
Bizarrely, increasing the cache size has no effect on throughput! I reran both without tracy just to make sure:
With 128mb cache, no tracy:
7327 batches in 1050.54 s
load offered = 1000000 tx/s
load accepted = 57113 tx/s
batch latency p00 = 15 ms
batch latency p10 = 36 ms
batch latency p20 = 37 ms
batch latency p30 = 37 ms
batch latency p40 = 37 ms
batch latency p50 = 42 ms
batch latency p60 = 43 ms
batch latency p70 = 52 ms
batch latency p80 = 67 ms
batch latency p90 = 108 ms
batch latency p100 = 8845 ms
With 16gb cache, no tracy:
7327 batches in 1014.11 s
load offered = 1000000 tx/s
load accepted = 59165 tx/s
batch latency p00 = 5 ms
batch latency p10 = 36 ms
batch latency p20 = 37 ms
batch latency p30 = 37 ms
batch latency p40 = 37 ms
batch latency p50 = 37 ms
batch latency p60 = 37 ms
batch latency p70 = 42 ms
batch latency p80 = 42 ms
batch latency p90 = 42 ms
batch latency p100 = 10316 ms
Is the extra read bandwidth just free? Are we not saturating the disk at all?