readxl
 readxl copied to clipboard
readxl copied to clipboard
Blank cells are read as NA even when asked not to
read_excel is still treating empty cells as NA when "" is removed from the na argument:
path <- readxl_example("geometry.xlsx")
read_excel(path, range="B1:D6", col_names=c("B", "C", "D"), na=character(0))
# A tibble: 6 x 3
B C D
<chr> <chr> <chr>
1 NA NA NA
2 NA NA NA
3 B3 C3 D3
4 B4 C4 D4
5 B5 C5 D5
6 B6 C6 D6
This is the expected output:
# A tibble: 6 x 3
B C D
<chr> <chr> <chr>
1 "" "" ""
2 "" "" ""
3 B3 C3 D3
4 B4 C4 D4
5 B5 C5 D5
6 B6 C6 D6
Those cells really are empty, though. What data are you expecting to appear there?
Oh I see you say that you are expecting the empty string. That strikes me as un-R-like. If we have an element of a character vector whose value is unknown, I think NA is the expected value, not "".
I'd say this is the best way to get the result you want.
library(readxl)
library(tidyverse) # dplyr::mutate_all(), tidyr::replace_na()
path <- readxl_example("geometry.xlsx")
df <- read_excel(path, range="B1:D6", col_names=c("B", "C", "D"))
df %>%
mutate_all(~ replace_na(.x, ""))
#> # A tibble: 6 x 3
#> B C D
#> <chr> <chr> <chr>
#> 1 "" "" ""
#> 2 "" "" ""
#> 3 B3 C3 D3
#> 4 B4 C4 D4
#> 5 B5 C5 D5
#> 6 B6 C6 D6
Created on 2019-05-29 by the reprex package (v0.3.0.9000)
To make an analogy to other types of vectors in R, we wouldn't fill in a 0 for an unknown numeric value or FALSE for an unknown logical value or some arbitrary origin for a date time. This is exactly what NA is for. The na argument is more a way to explicitly state actual string values that are considered a sentinel for NA, e.g. "99" or "unknown".
The element of the vector isn't unknown though, it's known to be "".
Note that your proposed method won't always work, because if there are sentinel values it will replace those genuine NA's as well as fixing the false positives on the empty strings.
If I have a value like "apple" in a numeric column, I'll get an NA even if that's not a sentinel value, because there is no obvious conversion from "apple" to numeric. Similarly, there is no obvious conversion from "" to numeric so it makes sense for that to give NA too.
But there is an obvious interpretation of "" as text!
Note that the documentation says: "By default, readxl treats blank cells as missing data."
This suggest that we can override the default, but if I understand correctly readxl always treats blank cells as missing data, and that is the intended behaviour?
if I understand correctly readxl always treats blank cells as missing data, and that is the intended behaviour
Yes, I think that is a fair statement.
Here's a file with three different types of blank cell that {readxl} imports as NA.
Cell A3 is what I would call an empty string, achieved by entering an apostrophe and nothing else. I have seen spreadsheets produced by various non-Excel software create such empty strings where most users would expect a truly blank cell.
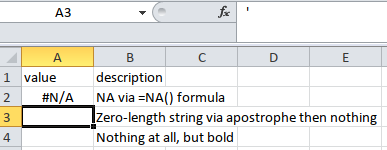
readxl::read_excel("temp.xlsx")
#> # A tibble: 3 x 2
#> value description
#> <lgl> <chr>
#> 1 NA NA via =NA() formula
#> 2 NA Zero-length string via apostrophe then nothing
#> 3 NA Nothing at all, but bold
{tidyxl} shows the difference between the cells. Cell A4 is labelled blank because it has no value at all, but exists because it has non-default formatting.
library(magrittr)
tidyxl::xlsx_cells("/home/nacnudus/temp/temp.xlsx") %>%
dplyr::filter(col == 1, row > 1) %>%
dplyr::select(address, is_blank, data_type, error, logical, numeric, date, character, formula) %>%
dplyr::glimpse()
#> Observations: 3
#> Variables: 9
#> $ address <chr> "A2", "A3", "A4"
#> $ is_blank <lgl> FALSE, FALSE, TRUE
#> $ data_type <chr> "error", "character", "blank"
#> $ error <chr> "#N/A", NA, NA
#> $ logical <lgl> NA, NA, NA
#> $ numeric <dbl> NA, NA, NA
#> $ date <dttm> NA, NA, NA
#> $ character <chr> NA, "", NA
#> $ formula <chr> "NA()", NA, NA
Inspecting the xml with {excelgesis} shows the empty string in the sharedStrings table.
<!-- xl/sharedStrings.xml -->
<sst xmlns="http://schemas.openxmlformats.org/spreadsheetml/2006/main" count="6" uniqueCount="6">
<si>
<t>NA via =NA() formula</t>
</si>
<si>
<t/> <!-- empty string -->
</si>
<si>
<t>Zero-length string via apostrophe then nothing</t>
</si>
<si>
<t>description</t>
</si>
<si>
<t>value</t>
</si>
<si>
<t>Nothing at all, but bold</t>
</si>
</sst>
@pitakakariki's suggested syntax na = character(0) comes from {readr}.
readr::read_csv("a,b\nfoo,bar\n,bar", na = character())
#> # A tibble: 2 x 2
#> a b
#> <chr> <chr>
#> 1 foo bar
#> 2 "" bar
As @nacnudus mentioned the way readr handles this is na defaults to c("", "NA") and if you remove the empty string "" they are passed through unchanged.
Cell A3 (with the apostrophe to explicitly indicate the value is the empty string) seems distinct from A4, as @nacnudus's XML suggests. The argument why A3 should import as "" is more clear to me than it is for A4.
This seems like an edge case where aligning readr and readxl isn't trivial, because of fundamental differences between xls(x) and csv. readxl can create a data frame that, due to a user-specified range, hits cells that don't even exist on disk. In a csv, every cell has to exist in some sense.
Going back to @pitakakariki's original example, consider that a user specifies a range that spans cells that don't actually exist on disk and cells like those created by @nacnudus. Should readxl fill nonexistent cells with "", just like empty-cells-that-exist-because-they-bear-a-format or cells that explicitly contain the apostrophe (like A3)?
<row r="3" spans="1:2" x14ac:dyDescent="0.25">
<c r="A3" s="1" t="s">
<v>1</v>
</c>
<c r="B3" t="s">
<v>2</v>
</c>
</row>
<row r="4" spans="1:2" x14ac:dyDescent="0.25">
<c r="A4" s="2"/>
<c r="B4" t="s">
<v>5</v>
</c>
</row>
To be more concrete, here's the XML for rows 3 and 4 for @nacnudus's example.
The cell A3 has type "s", which means contents are looked up from the shared string table. A3's contents are element 1 in the 0-indexed shared string table. So, really, element 2, which is the empty string, as we've seen.
Cell A4 has no contents and no cell type. It has style "2", which relates to its formatting.
Cell A5, had the user's range requested it, would not be represented in the XML at all.
I just experienced the confusion of this issue. I understand the complexity indicated above.
I think that a reasonable way to work through this would be to do the following:
- If
!("" %in% na), give a warning to the user along the lines of "Cells that are not explicitly an empty string as created by entering a single apostrophe in a cell in Microsoft Excel, the cell will be read in as NA due to the way the value is stored in the file." - Add documentation to the help page to that effect, too.
Similar issue is also with " " and trim_ws = F
writexl::write_xlsx(x = tibble::tibble(a = c(NA_character_, "", " ", " ", " .")), path = 'temp.xlsx')
readxl::read_xlsx(path = 'temp.xlsx', trim_ws = F)
a
1 NA
2 NA
3 NA
4 NA
5 " ."
if I understand correctly readxl always treats blank cells as missing data, and that is the intended behaviour
Yes, I think that is a fair statement.
This blurs default behaviour and default arguments. I'd expect changing an argument to change behaviour, but this does not happen here.
The way readr works fits with what I expected to happen using read_xlsx(). I see that it is more complicated than just treating an xlsx as a csv, but I'd start by asking what someone who has made the deliberate act to use an na = character(0) argument is expecting/intending.