fastapi
 fastapi copied to clipboard
fastapi copied to clipboard
[QUESTION] Validation in the FastAPI response handler is a lot heavier than expected
First check
- [x] I used the GitHub search to find a similar issue and didn't find it.
- [x] I searched the FastAPI documentation, with the integrated search.
- [x] I already searched in Google "How to X in FastAPI" and didn't find any information.
Description
So I have built a Tortoise ORM to Pydantic adaptor, and it's about stable, so I started profiling and found some interesting.
Pydantic will validate the data I fetch from the DB, which seems redundant as the DB content is already validated. So we are doing double validation. Further profiling I found that the majority of time is spent by FastAPI preparing the data for serialisation, and then validating it, and then actually serialising (This specific step is what https://github.com/tiangolo/fastapi/issues/1224#issuecomment-617243856 refers to)
So I am doing essentially triple validation...
I then saw that there is the orjson integration, I tried that... and it made no difference that I could tell. (I'll get to this later)
I did a few experiments (none of them properly tested, but just to get an idea) with a simple benchmark: (The database was populated with 200 junk user profiles generated by hypothesis, response is 45694 bytes)
Key:
R1 → Using FastAPI to serialise a List[User] model automatically (where User is a Pydantic model)
R2 → Using FastAPI to serialise a List[User] model automatically, but disabled the validation step in serialize_response
R3 → Manually serialised the data using an ORJSONResponse
R4 → Using FastAPI to serialise a List[User] model automatically, bypassed the jsonable_encoder as I'm serialising with orjson
R5 → Using FastAPI to serialise a List[User] model automatically, bypassed both validation and jsonable_encoder
C1 → Use provided pydantic from_orm
C2 → Custom constructor that doesn't validate
My results are:
R1 + C1 → 42req/s
R1 + C2 → 43req/s (Seems the 3 FastAPI steps overpower the validation overhead of from_orm)
R2 + C1 → 56req/s (Disabling the validation IN FastAPI has a much bigger impact?)
R2 + C2 → 63req/s (So, no extra validation)
R3 + C1 → 75req/s
R3 + C2 → 160req/s
R4 + C1 → 53req/s (This orjson-specific optimization gave us a 26% speedup here!)
R4 + C2 → 64req/s (This orjson-specific optimization gave us a 48% speedup here!)
R5 + C1 → 74req/s (So, almost as fast as bypassing the FastAPI response handler)
R5 + C2 → 147req/s
Was somewhat surprised by these results. Seems that Disabling all validation AND skipping the FastAPI response handler gave me a nearly 4x improvement!!
Outcomes:
- Doing an optimal build from ORM to Pydantic doesn't help much by itself, but with an optimal response handler, it can fly!
- We should really consider as https://github.com/tiangolo/fastapi/issues/1224#issuecomment-617243856 proposed if using orjson, as it gives a big improvement by itself!
- Validation in the FastAPI response handler is a lot heavier than expected
Questions: How advisable/possible is it to have a way to disable validation in the FastAPI response handler? Is it dangerous to do so? Should it be conditionally bypassed? e.g. we specify a way to mark it as safe?
I'm just trying to get rid of some bottlenecks, and to understand the system.
Nice, thanks for confirming my suspicions and getting some actual performance measurements on that issue. Out of curiosity, do you benchmark requests per second sequentially or in parallel? Given how encoding is part of the critical path on the event loop, jsonable_encoder and the json renderer are expected to have the worst performance impact when attempting to handle multiple requests in parallel, since they both block the event loop for whatever amount of time they end up running (since they are CPU-bound).
I tested with a concurrency of 10, but making it single concurrency hardly affected the results, as it was using a sqlite db as a backend (which is also single concurrency).
The benchmarks was just to find bottlenecks, and not to be representative of "real-world" use cases.
I think we should see if the default responder is orjson, and then skip jsonable_encoder. And do a full regression test with that config to find out if this is a valid use-case?
@grigi
- Do you have numbers when using multiple workers?
- Can you try it with postgres (may not help if you don't use something like asynvpg)
I don' think there's anything fastapi can do about the speed of pydantic validation, by design that's how pydantic is setup to work so you can't populate invalid properties on its objects, there's no guarantee your database.
I do agree however there are a good number of dependencies that could probably be improved with either faster or async aware alternatives, the less we block the better this will be, but also realizing there will always be blocking somewhere.
I expect it will scale nearly linearly, the DB is only 1.5% of the execution time...
Also, i'm very aware of how the event loop is susceptible to long-running sync code. This is an exercise in identifying bottlenecks, and then discussing the outcomes (as I'm not that familiar with fastapi internals at this stage)
Here is a annotated flamegraph of the unmodified stack:

-
When one builds a Pydantic object from an existing class-instance/dict, Pydantic will always validate, unless you completely bypass validation using
construct. But when doing that, recursive models are not built properly, so ideally one would want to use the validation when building. Also bypassing validation in Pydantic comes with BIG warnings.In the flamegraph (used vmprof) the exact same C function that does the Pydantic validation was run again part of
serialise_response. This is not ideal as when building a Pydantic model off existing data, it already validates in the same way.Possibly it is needed for the case where one returns a dict, but then the standard validation will happen in any case?
-
Using a faster JSON serialiser is going to speed up the 2.8% portion of the runtine (hence my comment that using orjson does very little in this case), but orjson & Rapidjson could do much of what the
jsonable_encoderis doing, and can possibly be skipped. That is now a 39.4% (36.6% + 2.8%) eligible runtime to speed up. Which is significant.
My comments was that ALWAYS forcing validation seems redundant to me, but I don't know all the use-cases. So am seeking advice on how to do this right in the future? Should the serialise_response be automatically selective when it does validation? Skip it altogether? Require manual notice that it's not required?
To Victor (your message disappeared here?)
I manually removed the validation code in FastAPI for this test purposes... It does seem that we might want to consider forcing validation off on a per-route option?
I can do some PR's for this, time is limited though. I am thinking of 2 different PR's:
- Skip
jsonable_encoderif the Response has aresponse_model_skip_jsonable_encoderset. (Possibly we want to allow this to be manually set by the route?) - Skip validation if when you specify a
response_model_skip_validationoption when setting up the route.
I like this last suggestion @grigi.
Though I'm fairly certain jsonable_encoder is called whether you have a response_model set or not, so it would probably make sense to just call it skip_jsonable_encoder.
Clarification: I mean that jsonable_encoder is called for any endpoint where you are not explicitly returning a response. It is not called if you explicitly return a Reponse.
@grigi thanks for the responde! Soon after I posted I answered my own question in my head and deleted my comments 😬.
About the flamegraph, did you use vprof / py-spy to generate it? Just out of curiosity!
@victoraugustolls vmprof + a local vmprof-server. I find vmprof is one of the easiest profilers to use. py-spy has slightly higher resolution, but requires more setup and the result isn't as easily browsable as vmprof. So I tend to use vmprof for high-level profiling, and py-spy for more focused profiling (if the perf criteria has not been met)
@acnebs Those two suggested PR's are for different things. Ideally both will have to happen.
1→jsonable_encoder bypass if your JSON encoder is capable (like orjson)
2 → Skip validation when not needed? (I would prefer an automatic way, but don't know how to make it automatic)
Right now if you use explicit response model, it works nice and fast, but the implicit response model is what is used in all the examples (and it reads nicer). The difference in performance wasn't explained properly, nor the case why we are forcing validation on a strict data structure?
I suppose This should have been 2 different tickets describing two different bottlenecks.
Skip validation when not needed? (I would prefer an automatic way, but don't know how to make it automatic)
I do find output validation to be useful in production to ensure that the API format contracts are always respected (which can be difficult to prove otherwise, your data source may end up throwing a null value in a place you didn't expect), so I don't know about disabling it automatically, but I would agree that being able to disable it for routes that return very large payloads would be useful performance-wise.
As for skipping jsonable_encoder, I'm 100% with you that it should be skippable if the framework user knows the json response renderer can handle any configuration of datatypes returned by the given route.
I had an attempt at #1434 But it seems that by skipping jsonable_encoder I need to know if I use the prepared, or validated response object.
What I mean by that is that the prepared object is in serialised form, and validated is in deserialised Pydantic object.
The original response object can be either, and if it is already a Pydantic object it's already fixed up, but a raw datastructure is not. So we can only safely skip if the original response object is already a Pydantic object, else we run the risk of emitting the non-fixed data.
So I think it can only be skipped if we turn validation off for that response.
For my use-case I'm not using pydantic at all where I want this. I want to be able to return a normal python dict and for that to be dumped by orjson without using jsonable_encoder.
Oh, you mean you didn't specify a response_model?
Yes, that case doesn't even have validation.
Good point, I'll ensure that happens as well :+1:
@acnebs Oh dear. My example tried to serialise Decimal and orjson doesn't support that? So it's missing one of my more common datatypes.
So we can't make this automatic.
So regardless, I should only allow skipping jsonable_encoder if the dev manually specified that one knows what one is doing. e.g. skip_validation=True is specified.
Seems we can't specify a JSON override for unsupported types like in stdlib's. Would love to be able to do something like this: https://github.com/django/django/blob/master/django/core/serializers/json.py#L77
Possibly python-rapidjson would be a good compromise: https://python-rapidjson.readthedocs.io/en/latest/dumps.html
We can use a default() hook to handle unsupported cases, and it supports a fair amount of extra stuff natively (uuid, decimal, datetime)
We can do that with orjson.
import decimal
import orjson
def default(obj):
if isinstance(obj, decimal.Decimal):
return str(obj)
raise TypeError
orjson.dumps(decimal.Decimal("0.0842389659712649442845"), default=default)
> b'"0.0842389659712649442845"'
Could (should?) then expand this default function to achieve parsing parity with jsonable_encoder when using this automatic orjson behaviour.
How did I miss that in the docs? It works, and will be part of #1434
Although it loses accuracy on Decimal (I had to let it return as a float to make it work the same as the jsonable_encoder)
Now that FastAPI has its own ORJSONResponse class, it might be interesting to define the default() callback in that response directly in order to avoid surprises like Decimal not being supported.
Yup, I did this in the linked PR: https://github.com/tiangolo/fastapi/pull/1434/files#diff-f5a428b2dd894bf2a31f0e8020faa3e8R19-R31
I feel like this was mentioned at some point in another issue, but another solution that would work for my use case is being able to specify a parameter in a response class that says I want to skip jsonable_encoder. Something like
class UnsafeORJSONResponse(Response):
skip_jsonable_encoder = True
...
And then in my endpoints decorators I can just specify response_class = UnsafeORJSONResponse. Or I can specify that as the response_class for the entire app / APIRouter.
Based on discussions here and other issues I've decided to skip FastAPI's response handler along with its validation and serialization.
- The response validation is just a performance hit since our application code already uses pydantic models which are validated, we work on models, not on dicts.
- The serialization with
jsonable_encoderwas created before Pydantic's own.json()utility was released (source: https://github.com/tiangolo/fastapi/issues/1107#issuecomment-612963659), andjsonable_encoderseems to have worse performance. We would much rather use Pydantic's.json()utility which also have support for custom json encoders and alternative json libraries such as ujson or orjson.
So we use a custom Pydantic BaseModel to leverage orjson and custom encoders:
import orjson
from pydantic import BaseModel as PydanticBaseModel
from bson import ObjectId
def orjson_dumps(v, *, default):
# orjson.dumps returns bytes, to match standard json.dumps we need to decode
return orjson.dumps(v, default=default, option=orjson.OPT_NON_STR_KEYS).decode()
class BaseModel(PydanticBaseModel):
class Config:
json_load = orjson.loads
json_dumps = orjson_dumps
json_encoders = {ObjectId: lambda x: str(x)}
And we use a custom FastAPI response class to give us flexibility of returning either the Pydantic model itself or an already seralized model (if we want more control over alias, include, exclude etc.). Returning a response class also make the data flow more explicit, easier to understand for outside eyes/new developers.
from typing import Any
from fastapi.response import JSONResponse
from pydantic import BaseModel
class PydanticJSONResponse(JSONResponse):
def render(self, content: Any) -> bytes:
if content is None:
return b""
if isinstance(content, bytes):
return content
if isinstance(content, BaseModel):
return content.json(by_alias=True).encode(self.charset)
return content.encode(self.charset)
Just wanted to share my approach, thanks for reading.
Full example:
from typing import Any, List, Optional
import orjson
from fastapi import FastAPI, status
from fastapi.response import JSONResponse
from pydantic import BaseModel as PydanticBaseModel
from bson import ObjectId
def orjson_dumps(v, *, default):
# orjson.dumps returns bytes, to match standard json.dumps we need to decode
return orjson.dumps(v, default=default, option=orjson.OPT_NON_STR_KEYS).decode()
class BaseModel(PydanticBaseModel):
class Config:
json_load = orjson.loads
json_dumps = orjson_dumps
json_encoders = {ObjectId: lambda x: str(x)}
class Item(BaseModel):
name: str
description: Optional[str] = None
price: float
tax: Optional[float] = None
tags: List[str] = []
class PydanticJSONResponse(JSONResponse):
def render(self, content: Any) -> bytes:
if content is None:
return b""
if isinstance(content, bytes):
return content
if isinstance(content, BaseModel):
reutrn content.json(by_alias=True).encode(self.charset)
return content.encode(self.charset)
app = FastAPI()
@app.post("/items/", status_code=status.HTTP_200_OK, response_model=Item)
async def create_item():
item = Item(name="Foo", price=50.2)
return PydanticJSONResponse(content=item)
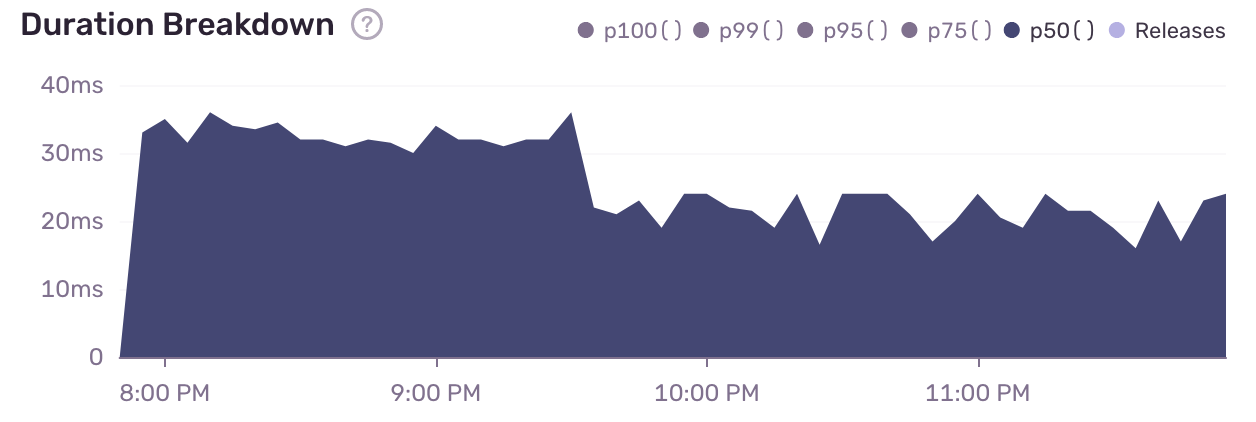
We tested the following monkey patch which has yielded noticeable improvements without having to change any of our endpoints. It reduced the latency (@50%) of one of our most used endpoints from ~30ms to ~20ms. However, it'd be great if stuff like this would be standard in FastAPI so that everyone could benefit from this. @tiangolo is there any chance something like this could make it to FastAPI, there seems to be enough people interested that are willing to contribute code.
class PydanticJSONResponse(fastapi.responses.JSONResponse):
"""FastAPI response that encodes Pydantic models."""
def render(self, content: Any) -> bytes:
if isinstance(content, BaseModel):
# For further performance improvements we could change the encoder,
# to use orjson.
return content.json(
by_alias=True,
ensure_ascii=False,
allow_nan=False,
indent=None,
separators=(",", ":"),
).encode(self.charset)
return super().render(content)
_original_serialized_response = fastapi.routing.serialize_response
async def _optimized_serialize_response(
*, field: ModelField | None = None, response_content: Any, **kwargs: Any
) -> Any:
# HACK: not sure what's the proper way to test if the response is of the
# same expected type. Unfortunately the pydantic type is defined in
# pydantic.main and I have no idea what the relationship between the two
# types is. We are using the name here, but I have no idea what happens when
# you have two models with the same name.
if isinstance(response_content, BaseModel) and (
field is None or field.type_.__name__ == type(response_content).__name__
):
return response_content
return await _original_serialized_response(
field=field, response_content=response_content, **kwargs
)
def patch_fastapi() -> None:
"""
Patch Fastapi to make it faster.
It changes the default response class and the serializer to avoid reencoding
and revalidating pydantic models.
See https://github.com/tiangolo/fastapi/issues/1359 and
https://github.com/tiangolo/fastapi/pull/1434.
"""
fastapi.routing.serialize_response = _optimized_serialize_response
fastapi.FastAPI.__init__.__kwdefaults__[
"default_response_class"
] = PydanticJSONResponse
Jumping on this bandwagon -- I'm returning large nested models in my application, so it appears the validation is adding 300-500ms per request. @sk- I might try your workaround but would ideally prefer this to be solved in a first-class manner
edit: Note - returning Model.dict() instead of Model alone dropped 500ms off my request time, but it destroys the openapi docs
If you don't want to monkeypatch, you could also probably subclass JSONResponse and just use MyJSONResponse(obj)
Unfortunately, if you want to use UUIDs as keys, you'll then need to monkeypatch json :(
import json
from json import JSONEncoder
from fastapi.responses import JSONResponse
class MyJSONEncoder(JSONEncoder):
def default(self, obj):
if isinstance(obj, UUID):
return str(obj)
if isinstance(obj, datetime):
return obj.strftime('%Y-%m-%dT%H:%M:%SZ')
else:
return super().default(obj)
class MyJSONResponse(JSONResponse):
def render(self, content: Any) -> bytes:
if isinstance(content, BaseModel):
c = content.dict()
else:
c = content
return json.dumps(
c,
ensure_ascii=False,
cls=CSJSONEncoder,
allow_nan=False,
indent=None,
separators=(",", ":"),
).encode("utf-8")
If you use
orjson, it supports natively serializing UUIDs to strings.
Good call, I'll sub it in :)
@curtiscook: Echoing what @acnebs is saying, use orjson. You don't even need to globally monkeypatch the application, just make a custom response class and set it on your more complex routes.
You will need to create your own response class, though, since orjson will refuse non-string keys by default, and you said you wanted UUID keys:
import orjson
from fastapi.responses import JSONResponse
class ORJSONCustomResponse(JSONResponse):
media_type = "application/json"
def render(self, content: Any) -> bytes:
# See: https://github.com/ijl/orjson#option
# OPT_NON_STR_KEYS allows dict keys to be ints, uuids, datetimes, enums, etc.
# OPT_UTC_Z serializes UTC datetimes with a "Z" at the end instead of "+00:00"
return orjson.dumps(content, option=orjson.OPT_NON_STR_KEYS | orjson.OPT_UTC_Z)
@router.get('/foo', response_model=FooModel, response_class=ORJSONCustomResponse)
def get_foo():
my_model = FooModel()
return ORJSONCustomResponse(my_model)
EDIT: Also, I've yet to try this, but since dataclasses now are fully supported by pydantic (and SQLAlchemy) and orjson claims to be able to serialize these 50x faster than other libraries, you may want to convert your Pydantic models to Pydantic dataclasses and leave it up to orjson to serialize these instead of letting jsonable_encoder handle the models directly or the dicts from Model.dict().
Monkey patching json doesn't feel good so I'll substitute orjson in when I get a chance and let people know how it goes. It's still a bummer that it will break the openapi docs. Curious to get @tiangolo 's thoughts on this thread. At the very least we could add findings from this issue to documentation since there's a non monkeypatch way to bypass validation (albeit with minor drawbacks)
EDIT: Also, I've yet to try this, but since dataclasses now are fully supported by pydantic (and SQLAlchemy) and orjson claims to be able to serialize these 50x faster than other libraries, you may want to convert your Pydantic models to Pydantic dataclasses and leave it up to orjson to serialize these instead of letting
jsonable_encoderhandle the models directly or the dicts fromModel.dict().
Personally, I'm not quite ready to give up on pydantic. I think the largest issue here is revalidating already validated models during the response step?
Monkey patching json doesn't feel good so I'll substitute orjson in when I get a chance and let people know how it goes. It's still a bummer that it will break the openapi docs. Curious to get @tiangolo 's thoughts on this thread. At the very least we could add findings from this issue to documentation since there's a non monkeypatch way to bypass validation (albeit with minor drawbacks)
Setting response_class and returning an instance of that class from your function directly (forgot to mention that part, will edit my previous comment) shouldn't break the OpenAPI documentation, although it does means the model won't be revalidated prior to sending, which you'll want to take into account.
Personally, I'm not quite ready to give up on pydantic. I think the largest issue here is revalidating already validated models during the response step?
It's not really giving up on pydantic, just a new way of defining pydantic models in a way that integrates more cleanly with other Python libraries. Losing on model revalidation is definitely a bummer. What I personally do to not lose out on that is to return my model to let FastAPI and Pydantic revalidate during development, and then before sending to production I just swap the return my_model for return ORJSONCustomResponse(my_model).
If you want both the fast JSON encoding and the output revalidation, you can use something like Stoplight's Prism proxy, which can be configured to validate the response against the spec for all incoming requests, without blocking FastAPI's event loop while doing so.