iotdb
 iotdb copied to clipboard
iotdb copied to clipboard
This repository is ReadOnly now. please go to https://github.com/apache/incubator-iotdb

kvindex的查询语法确认: 原先的kvindex(f_index_pr实现的)的查询语法为: select kvindex(queryPath, patternPath, pattern starttime, pattern endtime, epsilon (,alpha, beta)) from queryPath WhereClause 之后和向东学长讨论的查询语法有: 1. select ... from query path where kvmatch(pattern path, ...) and ... 2. select...
创建timeseries s0时,首先会向MManager中添加s0  然后会向对应的fileNode中添加s0  但是如果这个fileNode不存在的话会新创建一个fileNode  新建fileNode的时候将要构建fileSchema  而构建fileSchema的时候需要查询MManager  **注意,这个时候的MManager中已经有s0了,所以新构建的fileSchema中也会有s0 之后再向fileNode中添加s0时,实际上已经重复了**  
问题分支:master 复现方法: - 启动IoTDB server及client - 创建存储组 root.g0 - 创建时间序列 root.g0.d0.s0,类型编码任意 - 关闭IoTDB server及client - 重新启动IoTDB server及client - 删除时间序列 root.g0.d0.s0 重启前 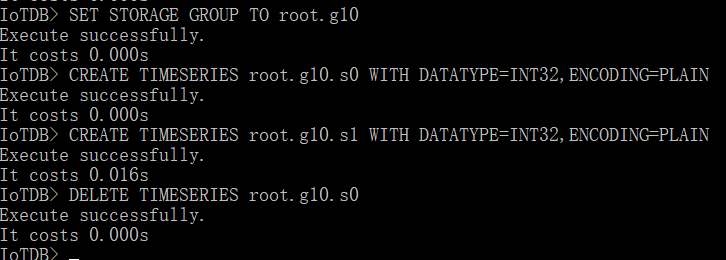 重启后 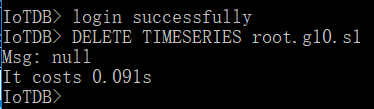
We use the different code style, which leads to a lot of diffs in prs. Unifying the code style is better. We can reference to [google-java-format](https://github.com/google/google-java-format) and [checkstyle](https://github.com/checkstyle/checkstyle)
在某些场景下,例如磁盘写满导致某个文件处于部分写入的状态,文件格式被破坏,这时系统重启会失败。 因此需要加入一个系统自检工具(模块),来使得系统重启失败后能尽可能回复到可用状态。 基本需求: 对于系统启动所需的每一个文件(数据文件,元数据文件,写前日志文件等),检查其格式是否正确。向用户报告这些格式不正确的文件,由用户选择是否清除这些文件。 进阶需求: 检测到不正确的文件时,尝试对文件进行修复,恢复到其上一个可用状态。
我们现在使用的是Pull式查询引擎,即Iterator式的查询引擎。 许多论文中指出,这种查询引擎存在一些问题,最典型的是调用链过长导致指令局部性差,具体可以参考下图: 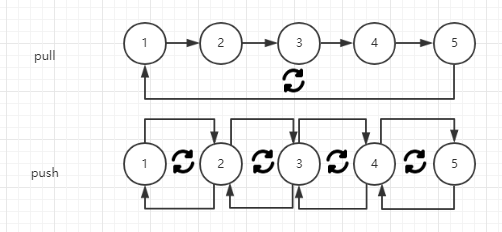 图中每一个圆代表一种数据访问器(Iterator),每个左边的圆是右边的圆的子类。 在Pull式(上)中,每次取数据(即调用Iterator的next())都要经过这样的一个调用链,这个过程会涉及较多的函数(代码)。通常来说,这些函数存在内存的不同位置,因此每次函数调用都会导致指令内存缺失,从而造成性能损失。另一个方面,调用栈的构建本身也是一个性能开销比较大的操作,在复杂代码中,指望编译器进行也是不现实的。 而在Push式(下)中,取数据的过程则有所不同,预取在其中有着很重要的地位。以上图为例,访问器1在被创建时会递归地创建访问器2作为其底层的访问器,而访问器2会递归创建访问器3,以此类推,直到创建最底层的访问器5(假定其直接访问文件)。访问器5在被创建时,先从文件中读出若干个数据点到自身的buffer中,在buffer满时,再把buffer中的每一个点发给访问器4,访问器同样先把数据存到自己的buffer中,等到buffer满了以后再向上发送。 实际取数的时候,如果访问器1的buffer没有耗尽,则直接从中取数,否则再经过上述预取过程即可。 在这种模式中,函数调用主要发生在一个访问器内部和两个访问器之间,不会形成由多个访问器组成的长调用链。这就使得指令cache发生缺失的可能降低,从而提高系统性能。另一个方面,由于数据存在buffer之中,而buffer往往是连续分配的,所以在连续取点的时候,也能获得更好的数据局部性。
如 "insert into root.vehicle.d0(timestamp,s1) values(1000,55555)" "UPDATE root.vehicle SET d0.s1 = 0 WHERE time > 90" select s1 from root.vehicle.d0 where s1 < 100; 将不能够得到timestamp = 1000的那条记录 ps 单点值更新可以通过插入实现,后插入的值会覆盖先插入的值
aggregate does not support avg function. 
当前版本下(0.7.0), 系统导入了1个storage group, 7G数据, 6万个左右时序(300个设备)。 然后执行了删除命令 `DELETE TIMESERIES root.ln.windfarm_hIzWi_001.*`, `DELETE TIMESERIES root.ln.windfarm_hIzWi_002.*`. 然后重新导入上述数据,又重新执行上述删除。 之后执行任何query都提示内部错误。  系统重启后再做查询,仍然提示内部错误。