您好,请问一下为什么训练的时候卡在这里了?

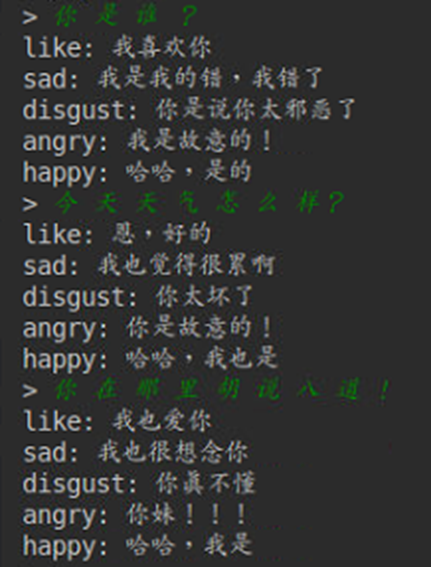 那请问一下,您给的数据集(http://coai.cs.tsinghua.edu.cn/hml/challenge2017/)post-response pair 总共有1,110,000个,而论文中的训练集有217,905个post 近4,000,000个response,造成生成的回复不准确的原因是因为数据集较小吗?还是因为训练得不够充分?
那请问一下,您给的数据集(http://coai.cs.tsinghua.edu.cn/hml/challenge2017/)post-response pair 总共有1,110,000个,而论文中的训练集有217,905个post 近4,000,000个response,造成生成的回复不准确的原因是因为数据集较小吗?还是因为训练得不够充分?
您好,在测试到perplexity只有80的情况下,use_emb + use_imemory 的实际效果感觉比use_emb + use_imemory + use_ememory 的效果好(ememory是用的大连理工的那个emotion词汇),想请问一下是怎么回事呢?
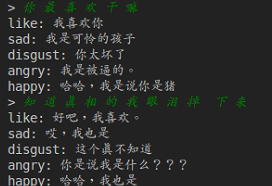
NLPCC2017 是过滤后的小数据集,其训练数据中每个 post 平均对应2-3种不同情绪的 response,所以对于未训练到的情绪种类的 response 其生成质量并不高。在比赛评测时,也只测试其中概率较高的几种情绪类别的 response。
对于不同模块组会的性能,可以通过调整模型训练参数进行调整,在 ESTC 的数据集上的实验结果是,加入 ememory 后会提升情绪表达的准确率,详情可以参考论文。
您好,在测试到perplexity只有80的情况下,use_emb + use_imemory 的实际效果感觉比use_emb + use_imemory + use_ememory 的效果好(ememory是用的大连理工的那个emotion词汇),想请问一下是怎么回事呢?
您好,想问一下您,词汇库从哪里下载呢?或者能不能分享一下?
CPU一直在占用,却一直没有反应,都跑了两天了依然是这样的,请问一下是什么原因呢?
您好,想问一下这个问题怎么解决的呢?我也遇到这样的问题
大连理工的情感词汇数据集:http://ir.dlut.edu.cn/news/detail/215 我大致改了一下代码,具体改了哪些不太记得,但是本issue第二条的那段代码是要改的
您好,想问一下这个问题怎么解决的呢?我也遇到这样的问题
大连理工的情感词汇数据集:http://ir.dlut.edu.cn/news/detail/215 我大致改了一下代码,具体改了哪些不太记得,但是本issue第二条的那段代码是要改的
哦哦,非常感谢您的回复,以及您分享的数据集,真的很感谢,我刚开始学习这块内容,感觉不太能改的了代码,如果方便的话,能不能看看您的代码呢
您好,想问一下这个问题怎么解决的呢?我也遇到这样的问题
大连理工的情感词汇数据集:http://ir.dlut.edu.cn/news/detail/215 我大致改了一下代码,具体改了哪些不太记得,但是本issue第二条的那段代码是要改的
我现在跑模型,倒也不是卡在那里了,只是速度特别慢,一个epoch要跑大半天,感觉数据量也没有很大啊,奇怪。
在请问一下,这里为什么要把x[0][0](应该是post)的值赋给response_vocab呢
你说的issue2是不是我直接交换一下x[0][0] 和y[0]那两段代码的位置就可以了
在请问一下,这里为什么要把x[0][0](应该是post)的值赋给response_vocab呢
请问这个地方是为什么会把post的值赋给response_vocab,是理解上的问题吗?
在请问一下,这里为什么要把x[0][0](应该是post)的值赋给response_vocab呢
请问这个地方是为什么会把post的值赋给response_vocab,是理解上的问题吗?
我觉着这块得改一下
这块代码看起来很奇怪,确实应该换一下比较合理:
create_vocabulary(response_vocab_path, [y[0] for x in train for y in x[1]], response_vocabulary_size, tokenizer)
create_vocabulary(post_vocab_path, [x[0][0] for x in train], post_vocabulary_size, tokenizer)
感谢指出这个bug,我会更新到代码中。
你好,我想请问一下vector.txt是代码自己生成的吗?在哪里啊?现在跑baseline.py这个文件报错。提示No such file or directory: 'vector.txt'
您好,想问一下这个问题怎么解决的呢?我也遇到这样的问题
大连理工的情感词汇数据集:http://ir.dlut.edu.cn/news/detail/215 我大致改了一下代码,具体改了哪些不太记得,但是本issue第二条的那段代码是要改的
我现在跑模型,倒也不是卡在那里了,只是速度特别慢,一个epoch要跑大半天,感觉数据量也没有很大啊,奇怪。
请问你有没有出现找不到vector.txt这个文件的错误啊?请问这个文件是怎么来的?
您好,想问一下这个问题怎么解决的呢?我也遇到这样的问题
大连理工的情感词汇数据集:http://ir.dlut.edu.cn/news/detail/215 我大致改了一下代码,具体改了哪些不太记得,但是本issue第二条的那段代码是要改的
我现在跑模型,倒也不是卡在那里了,只是速度特别慢,一个epoch要跑大半天,感觉数据量也没有很大啊,奇怪。
请问你有没有出现找不到vector.txt这个文件的错误啊?请问这个文件是怎么来的?
你在根目录下新建一个vector.txt 空文件就可以跑通了
您好,想问一下这个问题怎么解决的呢?我也遇到这样的问题
大连理工的情感词汇数据集:http://ir.dlut.edu.cn/news/detail/215 我大致改了一下代码,具体改了哪些不太记得,但是本issue第二条的那段代码是要改的
我现在跑模型,倒也不是卡在那里了,只是速度特别慢,一个epoch要跑大半天,感觉数据量也没有很大啊,奇怪。
请问你有没有出现找不到vector.txt这个文件的错误啊?请问这个文件是怎么来的?
你在根目录下新建一个vector.txt 空文件就可以跑通了
嗯嗯,好的,谢谢🙏,但是现在又报错说ValueError: Dimension 0 in both shapes must be equal, but are 40000 and 158 for 'Assign_1' (op: 'Assign') with input shapes: [40000,100], [158,100].
请问这是怎么回事呢?
您好,想问一下这个问题怎么解决的呢?我也遇到这样的问题
大连理工的情感词汇数据集:http://ir.dlut.edu.cn/news/detail/215 我大致改了一下代码,具体改了哪些不太记得,但是本issue第二条的那段代码是要改的
我现在跑模型,倒也不是卡在那里了,只是速度特别慢,一个epoch要跑大半天,感觉数据量也没有很大啊,奇怪。
请问你有没有出现找不到vector.txt这个文件的错误啊?请问这个文件是怎么来的?
你在根目录下新建一个vector.txt 空文件就可以跑通了
嗯嗯,好的,谢谢🙏,但是现在又报错说ValueError: Dimension 0 in both shapes must be equal, but are 40000 and 158 for 'Assign_1' (op: 'Assign') with input shapes: [40000,100], [158,100].
请问这是怎么回事呢?
因为实验设置里的vocab_size是40000,但是data里的语料规模小,post中只有158个词,shape就不一样了。
嗯嗯,非常感谢,那请问应该怎么处理呢?因为response也有这个问题,纠结了好久
如果只是想跑通代码的话 我觉得可以把vocabsize都改小一点吧 或者换那个大的数据集
嗯嗯,非常感谢,那请问应该怎么处理呢?因为response也有这个问题,纠结了好久
如果只是想跑通代码的话 我觉得可以把vocabsize都改小一点吧 或者换那个大的数据集
请问那个大的数据集是指STC数据集吗? 我现在只想先跑通一下代码,所以我先试着去改一下vocabsize。非常感谢你的帮助!请问能不能加个QQ方便讨论一下啊?我的QQ是346577353,强烈建议建个群方便讨论
您好,想问一下这个问题怎么解决的呢?我也遇到这样的问题
大连理工的情感词汇数据集:http://ir.dlut.edu.cn/news/detail/215 我大致改了一下代码,具体改了哪些不太记得,但是本issue第二条的那段代码是要改的
我现在跑模型,倒也不是卡在那里了,只是速度特别慢,一个epoch要跑大半天,感觉数据量也没有很大啊,奇怪。
你好,我现在也是遇到这个问题卡在这里不动了,请问你解决了吗?
CPU一直在占用,却一直没有反应,都跑了两天了依然是这样的,请问一下是什么原因呢?
您好,想问一下这个问题怎么解决的呢?我也遇到这样的问题
大连理工的情感词汇数据集:http://ir.dlut.edu.cn/news/detail/215 我大致改了一下代码,具体改了哪些不太记得,但是本issue第二条的那段代码是要改的
我现在跑模型,倒也不是卡在那里了,只是速度特别慢,一个epoch要跑大半天,感觉数据量也没有很大啊,奇怪。
你好,我现在也是遇到这个问题卡在这里不动了,请问你解决了吗?
他其实在跑,只是很慢,1000个checkpoint才会输出你的困惑度,你得等等吧
CPU一直在占用,却一直没有反应,都跑了两天了依然是这样的,请问一下是什么原因呢? 您好,想问一下这个问题怎么解决的呢?我也遇到这样的问题 大连理工的情感词汇数据集:http://ir.dlut.edu.cn/news/detail/215 我大致改了一下代码,具体改了哪些不太记得,但是本issue第二条的那段代码是要改的 我现在跑模型,倒也不是卡在那里了,只是速度特别慢,一个epoch要跑大半天,感觉数据量也没有很大啊,奇怪。 你好,我现在也是遇到这个问题卡在这里不动了,请问你解决了吗?
他其实在跑,只是很慢,1000个checkpoint才会输出你的困惑度,你得等等吧
嗯嗯,好的。那么那个Vector.txt文件还是空的啊,其实按理来说里面应该放的是词向量,就这么空着没有影响吗?
CPU一直在占用,却一直没有反应,都跑了两天了依然是这样的,请问一下是什么原因呢? 您好,想问一下这个问题怎么解决的呢?我也遇到这样的问题 大连理工的情感词汇数据集:http://ir.dlut.edu.cn/news/detail/215 我大致改了一下代码,具体改了哪些不太记得,但是本issue第二条的那段代码是要改的 我现在跑模型,倒也不是卡在那里了,只是速度特别慢,一个epoch要跑大半天,感觉数据量也没有很大啊,奇怪。 你好,我现在也是遇到这个问题卡在这里不动了,请问你解决了吗?
他其实在跑,只是很慢,1000个checkpoint才会输出你的困惑度,你得等等吧
嗯嗯,好的。那么那个Vector.txt文件还是空的啊,其实按理来说里面应该放的是词向量,就这么空着没有影响吗?
vector里面的值是随机生成,然后跟着模型参数一起训练的,无需手动添加。 你可以建个群吧 方便讨论
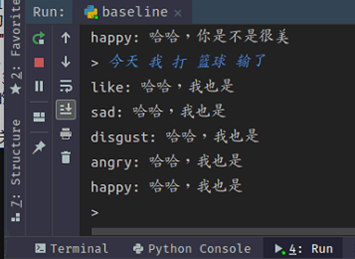
training的时候perplexity已经150左右,但是实际目前实际测试效果不大好,请问可能是哪里步骤出问题了呢?
你好,我在训练的时候也遇到的类似的问题,生成的句子都一样,请问你是怎么解决这个问题的,谢谢!