UpscalerJS
 UpscalerJS copied to clipboard
UpscalerJS copied to clipboard
ESRGAN-SLIM?
I see that you have a new default model, esrgan-slim. I didn't see any issues explaining what's different about this new model from the previous esrgan-legacy default. I assume it is "better", but can you give me a bit more detail about what's different?
I also see that only the pixel-upsampler and esrgan-legacy/div2k models have 2x and 3x versions. Last time I checked, the results from div2k weren't nearly as good as the esrgan-legacy/gans. I have not tested with the new pixel-upsampler models, but ideally, I'd love to have the new esrgan-slim at 2x, and 3x in addition to the existing 4x. I'm guessing those don't exist now, but I will be getting a new NVIDIA 4xxx as soon as they are released, and, if the training time is less than a few days, I'd be willing to do the training for the 2x and 3x models. If you can point me at a repo that explains the training process, that would help enormously. IIRC, you had it in the docs before, but I cannot find it now.
You are quite correct that documentation is lacking - I'd been hoping to beef up documentation on the models soon, but I haven't yet.
I'll answer your questions first and then provide more context on why I changed things around and what's still to come.
I see that you have a new default model, esrgan-slim. I didn't see any issues explaining what's different about this new model from the previous esrgan-legacy default. I assume it is "better", but can you give me a bit more detail about what's different?
esrgan-slim is the same GANS model as before. It used to live here. It's meant to be a placeholder for a faster model to come, which I'll write about below.
I have not tested with the new pixel-upsampler models
I wouldn't bother with these, they're a simple bilinear resizing. They're purely for automated testing purposes (e.g., I run integration tests against the CDNs), they should perform pretty much identically to resizing in your browser.
I also see that only the pixel-upsampler and esrgan-legacy/div2k models have 2x and 3x versions
The 4x version should still be available in esrgan-legacy, you should be able to import it with:
import X4 from '@upscalerjs/esrgan-legacy/div2k/4x';
Does this work, or is it throwing an error?
Last time I checked, the results from div2k weren't nearly as good as the esrgan-legacy/gans
I agree with you, the div2k models seem clearly inferior to gans.
More context on what's changed and why:
With the addition of Node support, I wanted to revisit the way models are loaded. Previously all models lived in a separate repo (this one) and were loaded over http at runtime. In a browser I think that makes sense, as it reduces the bundle size that you download from NPM while not forcing users to have to set up and integrate a local file server to consume the models over http.
In a Node environment, that's certainly not ideal behavior. The server might not even be able to query the internet, and even if it can you don't want your code making unexpected fetch calls!
With the latest code, models are installed alongside UpscalerJS and imported like so:
import gans from '@upscalerjs/esrgan-legacy/gans`
import Upscaler from 'upscaler';
const upscaler = new Upscaler({
model: gans,
});
This allows the upscaler to load the configuration (primarily the scale of the model, but potentially other things like the number of channels) from the locally installed model, and then, depending on whether it's Node or the browser, load the model directly from the local filesystem or from a CDN. (If someone wanted to serve the model from some local filesystem, they could still do that by overriding the path argument of model.
I'd still like to provide folks who only download upscaler a workable experience. @upscalerjs/esrgan-slim is meant to be a small and fast default model that gets installed alongside upscaler to provide a "batteries-included" experience if no model is provided. Right now I've made it the GANS model, which is not small, but is like you pointed out clearly the best model on offer.
I'm also working on a revamp of the documentation site, and as part of that I'd like to provide a place to view all the available models and experiment with them directly in browser, along with seeing automated metrics.
Alongside the above effort, I've been working on training new versions of ESRGAN for the browser. I'm hoping to launch a variety of flavors, but I haven't documented the training anywhere so I'll do that here.
In the spring I started doing some experiments on different parameters of ESRGAN. This is all in Python, I have yet to convert any of the models to JS. The Python code I use to train ESRGAN is here.
Here's what I'm hoping to offer:
- small -
RDNmodel, with parametersC1-D2-G4-G064 - medium -
RDNmodel, with parametersC1-D10-G64-G064 - large -
RRDNmodel, with parametersC4-D3-G32-G064-T10
The large model would have the highest performance (although not the highest absolute performance; e.g., I believe there was an architecture that performed inference slightly more accurately but at the cost of double the inference time). The small model would be the fastest, with a noticeable drop in inference performance, but still usable. And medium would be a blend of the two.
All three sizes would come with three scales, 2x, 3x, and 4x.
All three would additionally be one of four types:
- original
- "compressed" - the low resolution training images going in are pre-compressed. The Python author noted this as a technique they used to handle lossy images.
- "sharpened" - the high resolution training images coming out are pre-sharpened. The paper authors mention that during their experiments, this anecdotally produced better looking images (even though the PSNR scores were lower).
- both "compressed" and "sharpened"
Finally, I ran some experiments training on different datasets, specifically, div2k (general), FFHQ (faces), and wikiart (art). For FFHQ, I got noticeably better results when upscaling faces vs. div2k, whereas div2k performs better on more general images. wikiart did not perform well, I think because the images in the dataset are not large enough. These results seem unintuitive to me - I would expect a general purpose model trained across all data to perform the best - but that's not what I saw.
I will be getting a new NVIDIA 4xxx as soon as they are released, and, if the training time is less than a few days, I'd be willing to do the training for the 2x and 3x models. If you can point me at a repo that explains the training process, that would help enormously. IIRC, you had it in the docs before, but I cannot find it now.
I would very much welcome some training help. I'll work on getting my training code cleaned up and shared.
Things that I think would be interesting to experiment with:
- 8x models
- Models other than ESRGAN. This caught my eye. There's also been a request (#444) for a deblurring model which I think would be a great addition.
Also, if it does turn out that the FFHQ model performs noticeably better on faces than Div2k - a result I still find suspicious - then that would imply that models could be tuned for specific datasets, which would open up a whole set of possibilities for bespoke models trained for art, satellite images, animals, you name it. Again, I find it suspicious that specific-dataset-trained models outperform general models, since it wouldn't really make sense and especially as I haven't seen anything in the literature to support this, but it's certainly an area that we could continue exploring!
Finally, I'll just drop the notes I took during training below, apologies for the lack of formatting. If you're looking to run your own experiments these might help.
Here are some measurements I took for the models weights that are included in the original repo:
psnr-small
Value Time per 100 pixels in ms: 2.5898 PSNR mean: 31.4062 PSNR median: 30.8595 SSIM mean: 0.9290 SSIM median: 0.9287
psnr-large
Value Time per 100 pixels in ms: 14.1555 PSNR mean: 30.5545 PSNR median: 30.0172 SSIM mean: 0.9140 SSIM median: 0.9155
gans
Value Time per 100 pixels in ms: 5.0803 PSNR mean: 25.2562 PSNR median: 24.7465 SSIM mean: 0.7387 SSIM median: 0.7331 I started off by tweaking the
Cparameter. I trained for 150 epochs each:C=3
Value Time per 100 pixels in ms: 2.3081 PSNR mean: 30.2440 PSNR median: 29.8179 SSIM mean: 0.9135 SSIM median: 0.9161 C=6
Value Time per 100 pixels in ms: 6.9514 PSNR mean: 30.0233 PSNR median: 29.5405 SSIM mean: 0.9111 SSIM median : 0.9134 C=4
Value Time per 100 pixels in ms: 3.5268 PSNR mean: 30.3780 PSNR median: 29.9262 SSIM mean: 0.9150 SSIM median: 0.9170 C=1
Value Time per 100 pixels in ms: 0.7099 PSNR mean: 30.1430 PSNR median: 29.5861 SSIM mean: 0.9103 SSIM median: 0.9120 From the paper, here's what each parameter means:
RDN
- D - number of Residual Dense Blocks (RDB)
- C - number of convolutional layers stacked inside a RDB
- G - number of feature maps of each convolutional layers inside the RDBs
- G0 - number of feature maps for convolutions outside of RDBs and of each RBD output
RRDN
- T - number of Residual in Residual Dense Blocks (RRDB)
- D - number of Residual Dense Blocks (RDB) insider each RRDB
- C - number of convolutional layers stacked inside a RDB
- G - number of feature maps of each convolutional layers inside the RDBs
- G0 - number of feature maps for convolutions outside of RDBs and of each RBD output
Here are my notes from tweaking some of the other parameters:
It appears that a lower
G-4- tends to lead to higher scores than aGof 64. And the model goes faster.Evaluating the latest low
Gs.For comparison:
High
C,D, andG:{"C": "4", "D": "10", "G": "64", "G0": "64", "T": "0.0", "x": "2"} Total duration in ms: 5744.2710 Time per 100 pixels in ms: 5.6096 PSNR mean: 29.4634 PSNR median: 28.8411 SSIM mean: 0.8861 SSIM median: 0.8963
Low
CandD, highG:{"C": "1", "D": "2", "G": "64", "G0": "64", "T": "0.0", "x": "2"} Total duration in ms: 1459.5660 Time per 100 pixels in ms: 1.4254 PSNR mean: 27.6392 PSNR median: 26.7421 SSIM mean: 0.8749 SSIM median: 0.8821
Gs:{"C": "1", "D": "10", "G": "4", "G0": "64", "T": "0", "x": "2"} ../volumes/checkpoints/weights/rdn-C1-D10-G4-G064-T0-x2-patchsize128-compress50-sharpen1/2022-03-19_1604/rdn-C1-D10-G4-G064-T0-x2-patchsize128-compress50-sharpen1_epoch150.hdf5 Total duration in ms: 1293.6280 Time per 100 pixels in ms: 1.2633 PSNR mean: 28.0661 PSNR median: 27.7760 SSIM mean: 0.8770 SSIM median: 0.8865 - --- - {"C": "4", "D": "10", "G": "4", "G0": "64", "T": "0", "x": "2"} ../volumes/checkpoints/weights/rdn-C4-D10-G4-G064-T0-x2-patchsize128-compress50-sharpen1/2022-03-20_0413/rdn-C4-D10-G4-G064-T0-x2-patchsize128-compress50-sharpen1_epoch149.hdf5 Total duration in ms: 2714.5970 Time per 100 pixels in ms: 2.6510 PSNR mean: 29.2811 PSNR median: 28.7826 SSIM mean: 0.8810 SSIM median: 0.8919 - --- - {"C": "1", "D": "2", "G": "4", "G0": "64", "T": "0", "x": "2"} ../volumes/checkpoints/weights/rdn-C1-D2-G4-G064-T0-x2-patchsize128-compress50-sharpen1/2022-03-20_2026/rdn-C1-D2-G4-G064-T0-x2-patchsize128-compress50-sharpen1_epoch150.hdf5 Total duration in ms: 732.4980 Time per 100 pixels in ms: 0.7153 PSNR mean: 28.5072 PSNR median: 28.2037 SSIM mean: 0.8720 SSIM median: 0.8836
So lower
Gactually leads to higher scores. Unintuitive! And significantly fasterSo I think the takeaway is that `G0` should always be `64`.
It seems like layers tend to have a big cost in inference time without a ton of benefit in score improvement. Meanwhile, the maps (
GandG0) have a big impact on performance.Weirdly, the biggest model is not the best performing!
So
rdn-C1-D2-G4-G04-T0-epoch-148is the fastest performing, though at a pretty big drop in accuracy.
rdn-C1-D2-G4-G064-T0-epoch-150is also pretty fast and is also pretty performant.
rdn-C1-D10-G64-G064-T0.0-epoch-149performs the best, and is reasonably fast.
I trained the model on the original Div2k dataset (which already has LR images pre-generated) along with anotehr version that I downsampled myself. They perform very similarly, although the original does perform slightly better.
Below,
wikiartis listed twice, but the better performing one is actually div2k preprocessed.

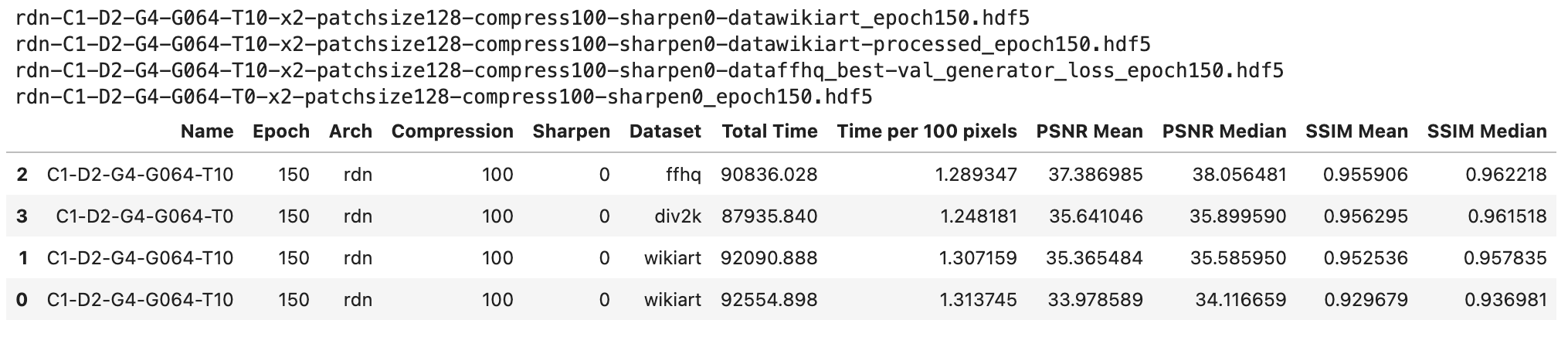
Weirdly, the model trained on FFHQ performs best on FFHQ, and second on other tasks. The models trained on Div2k perform best on Div2k, and second at everything else. The model trained on Wikiart performs worst on everything.
Also, the impact of bigger RRDN models is dubious, as shown by the charts below. That said, perhaps RRDNs with more epochs can perform significantly better.
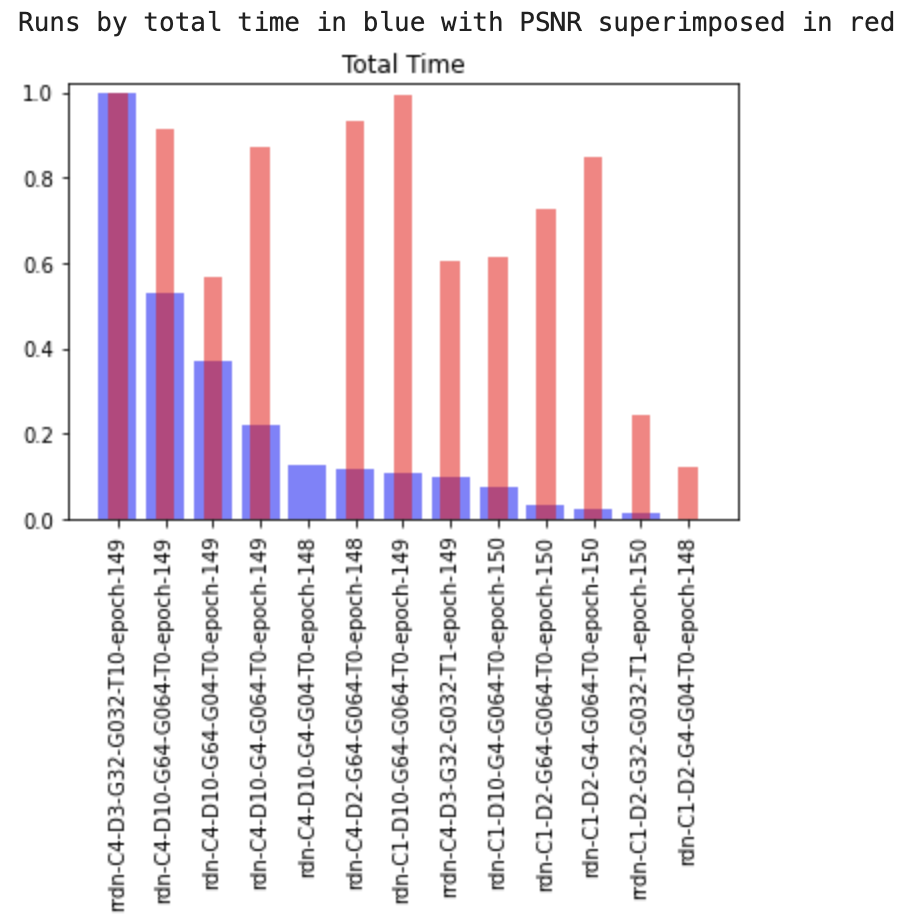
(in this second one, PSNR is not from 0-1, but actually from like 20-30) Also I think the chart labels here are wrong, I think PSNR is blue and total time is red
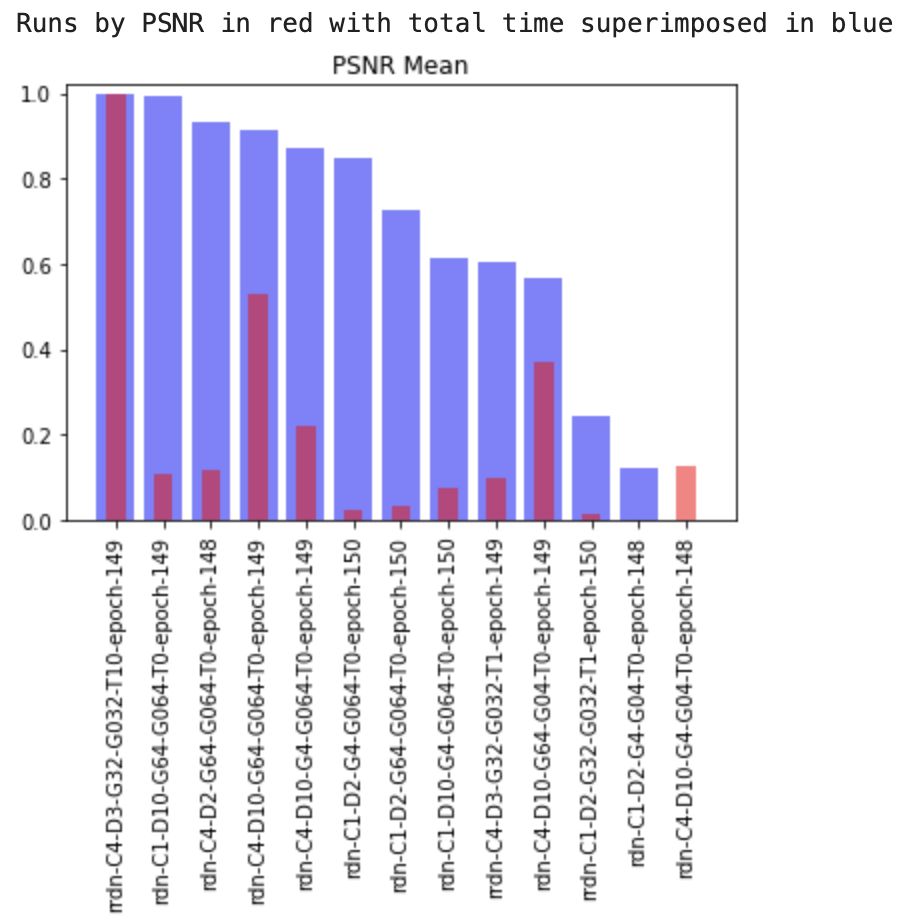

What's interesting is that the non-compressed images perform the best. This seems counterintuitive given idealo's write up.
Also, the sharpening of 2 performs almost as well as no sharpening, and beats in the other categories that are not PSNR Mean. I wonder if adding sharpening "fakes" the image closer to a real image. I'm trying with sharpening of 1.


Fantastic response!
I'll let you know as soon as I get my new NVIDIA 4xxxx machine. Hopefully very soon after release of the new GPU.
Deblurring is just one of several fascinating operations that I'm also working on. I haven't found a repo with a model that can (on first pass at least) be converted to TFJS. I need to retest with the latest converters.
FWIW, even though the model can take any input resolution, I've noticed it does MUCH better with inputs that are close to the size of the training set, which makes sense. I'd like to make sure we find a training set with higher resolution images so it works well even if the sources are larger.
The 4x version should still be available... Oh, I knew 4x was there too. I just didn't realize that you planned to train 2x and 3x networks for ESRGAN. I saw all the work done in the code and the new model modules to make it all work with more than just 4x, and assumed folks had been using div2k or the pixel models for 2x and 3x.
FWIW, even though the model can take any input resolution, I've noticed it does MUCH better with inputs that are close to the size of the training set, which makes sense. I'd like to make sure we find a training set with higher resolution images so it works well even if the sources are larger.
This is surprising to me! Is this true with and without explicit patch sizes enabled? I would have assumed that the model would be agnostic to the size of the input. I seem to recall the literature discussing the impact of patch size specifically on training speed, not necessarily on inference performance (assuming you make up for reduced patch sizes with additional epochs of training).
The patch size used to train the model is here:
lr_train_patch_size = 40
...
hr_train_patch_size = lr_train_patch_size * scale
In my training I've had to set the max hr_train_patch_size to 128 to keep it within memory. You could try setting it to a higher patch size to see if there's a difference in output. I'd be curious whether a 256 or even higher would have a noticeable effect on outputs.
It isn't the patch size, it is the overall source image size. The patch size does not affect the output at all, in my experience (aside from saving memory). The model was trained on images that are relatively small, so that's the pixel resolution it wants for recognizing and generating output image features. It works on all sizes, but it works best when your input image is ~300x300.
On Thu, Sep 1, 2022 at 3:51 AM Kevin Scott @.***> wrote:
FWIW, even though the model can take any input resolution, I've noticed it does MUCH better with inputs that are close to the size of the training set, which makes sense. I'd like to make sure we find a training set with higher resolution images so it works well even if the sources are larger.
This is surprising to me! Is this true with and without explicit patch sizes enabled? I would have assumed that the model would be agnostic to the size of the input. I seem to recall the literature discussing the impact of patch size specifically on training speed, not necessarily on inference performance (assuming you make up for reduced patch sizes with additional epochs of training).
The patch size used to train the model is here https://github.com/idealo/image-super-resolution#training:
lr_train_patch_size = 40 ... hr_train_patch_size = lr_train_patch_size * scale
In my training I've had to set the max hr_train_patch_size to 128 to keep it within memory. You could try setting it to a higher patch size to see if there's a difference in output. I'd be curious whether a 256 or even higher would have a noticeable effect on outputs.
— Reply to this email directly, view it on GitHub https://github.com/thekevinscott/UpscalerJS/issues/447#issuecomment-1234102616, or unsubscribe https://github.com/notifications/unsubscribe-auth/AAEQE2NXDRRIYWJSGDBIERTV4CDDXANCNFSM57BQR3CA . You are receiving this because you authored the thread.Message ID: @.***>
I've uploaded new models here:
https://drive.google.com/drive/folders/1pp29WO1_uLJTa549W7j6xNpcC_0o93WO?usp=sharing
It's a dump of each model's training artifacts for a variety of scales and architectures, converted to TFJS models. You can either place the folder in the models directory of this repo, or manually grab whichever model files you want to play with.
I haven't committed them to the repo because all together they're over 4GB+. My intent is to do some testing to find the best balance of performance to speed and then commit a subset of models that fit a combination of performance vs speed.
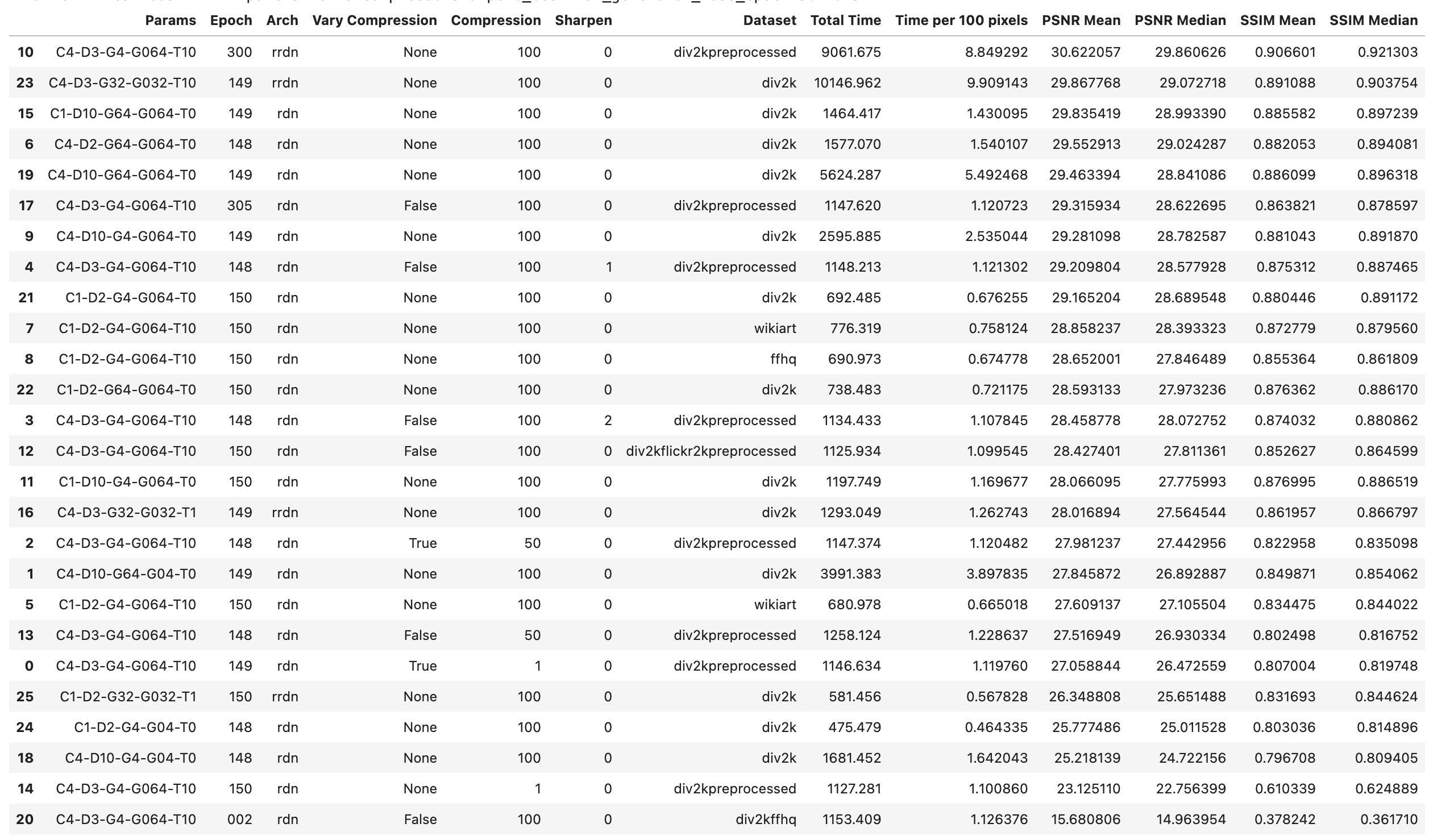
Here are my performance measurements so far. I'm still working on setting up scripts that will measure speed:
| Package | Model | Scale | div2k-PSNR | div2k-SSIM | ffhq-PSNR | ffhq-SSIM |
|---|---|---|---|---|---|---|
| experiments | ./models/esrgan/largeX2BestValLossEpoch500 | 2 | 30.231973 | 0.86166374 | 41.078031 | 0.96095711 |
| experiments | ./models/esrgan/largeX2BestValLossEpoch476 | 2 | 30.228303 | 0.86169017 | 40.755578 | 0.96092241 |
| experiments | ./models/esrgan/largeX2BestValGeneratorPSNRYEpoch475 | 2 | 30.225948 | 0.86165749 | 41.066837 | 0.96110866 |
| experiments | ./models/esrgan/largeX2BestValGeneratorPSNRYEpoch485 | 2 | 30.209881 | 0.86163503 | 40.620483 | 0.96117752 |
| experiments | ./models/esrgan/largeX2BestValLossEpoch488 | 2 | 30.207763 | 0.86182368 | 40.915569 | 0.9613556 |
| experiments | ./models/esrgan/largeX2Epoch490 | 2 | 30.199955 | 0.8612789 | 40.858748 | 0.96099028 |
| experiments | ./models/esrgan/largeX2BestValGeneratorPSNRYEpoch483 | 2 | 30.198536 | 0.86138273 | 40.704129 | 0.96105105 |
| experiments | ./models/esrgan/largeX2BestValLossEpoch484 | 2 | 30.195165 | 0.86133453 | 40.901108 | 0.96106507 |
| experiments | ./models/esrgan/largeX2BestValGeneratorPSNRYEpoch453 | 2 | 30.194976 | 0.86146187 | 40.911397 | 0.9610715 |
| experiments | ./models/esrgan/largeX2Epoch482 | 2 | 30.194665 | 0.86093159 | 40.881144 | 0.96083759 |
| experiments | ./models/esrgan/largeX2BestValGeneratorLossEpoch447 | 2 | 30.182124 | 0.86126997 | 40.815434 | 0.96107793 |
| experiments | ./models/esrgan/largeX2Epoch491 | 2 | 30.181466 | 0.86077891 | 40.933193 | 0.96091541 |
| experiments | ./models/esrgan/largeX2Epoch497 | 2 | 30.175495 | 0.86116293 | 40.850528 | 0.96064876 |
| experiments | ./models/esrgan/largeX2Epoch496 | 2 | 30.172467 | 0.86123384 | 40.665919 | 0.96095433 |
| experiments | ./models/esrgan/largeX2Epoch487 | 2 | 30.164575 | 0.86059396 | 40.801164 | 0.96100987 |
| experiments | ./models/esrgan/largeX2Epoch493 | 2 | 30.160175 | 0.8608323 | 40.546351 | 0.96049932 |
| experiments | ./models/esrgan/largeX2BestValGeneratorPSNRYEpoch452 | 2 | 30.150315 | 0.8609913 | 40.748871 | 0.96113239 |
| experiments | ./models/esrgan/largeX2Epoch500 | 2 | 30.148978 | 0.86091096 | 40.730526 | 0.96072692 |
| experiments | ./models/esrgan/largeX2Epoch494 | 2 | 30.148177 | 0.86036285 | 40.727491 | 0.96060072 |
| esrgan-legacy | ./psnr-small | 2 | 30.086053 | 0.86841338 | 38.740697 | 0.94346016 |
| experiments | ./models/esrgan/largeX2Epoch499 | 2 | 30.056475 | 0.86027043 | 39.874234 | 0.96061829 |
| experiments | ./models/esrgan/mediumX2BestValGeneratorPSNRYEpoch478 | 2 | 29.747288 | 0.84957776 | 39.920768 | 0.95362173 |
| experiments | ./models/esrgan/mediumX2BestValLossEpoch499 | 2 | 29.746234 | 0.85017281 | 39.877642 | 0.95403534 |
| experiments | ./models/esrgan/mediumX2BestValGeneratorLossEpoch500 | 2 | 29.727601 | 0.8490157 | 39.974597 | 0.95386464 |
| experiments | ./models/esrgan/mediumX2Epoch496 | 2 | 29.719942 | 0.84985091 | 39.757669 | 0.95363183 |
| experiments | ./models/esrgan/mediumX2Epoch485 | 2 | 29.714745 | 0.84899979 | 39.944033 | 0.95378354 |
| experiments | ./models/esrgan/mediumX2Epoch488 | 2 | 29.71219 | 0.84903628 | 39.829235 | 0.95333119 |
| experiments | ./models/esrgan/mediumX2BestValGeneratorLossEpoch479 | 2 | 29.707078 | 0.84886451 | 39.893426 | 0.95349942 |
| experiments | ./models/esrgan/mediumX2BestValLossEpoch493 | 2 | 29.692696 | 0.84951397 | 39.535573 | 0.95400645 |
| experiments | ./models/esrgan/mediumX2Epoch482 | 2 | 29.682337 | 0.84861232 | 39.809284 | 0.95329152 |
| experiments | ./models/esrgan/mediumX2Epoch491 | 2 | 29.681521 | 0.84922716 | 39.723463 | 0.9541151 |
| experiments | ./models/esrgan/smallX2BestValLossEpoch494 | 2 | 29.329399 | 0.8433662 | 38.459313 | 0.94859546 |
| experiments | ./models/esrgan/smallX2Epoch491 | 2 | 29.32848 | 0.8433601 | 38.448959 | 0.94847484 |
| experiments | ./models/esrgan/smallX2BestValGeneratorPSNRYEpoch483 | 2 | 29.321914 | 0.84294501 | 38.48293 | 0.94857111 |
| experiments | ./models/esrgan/smallX2BestValGeneratorLossEpoch499 | 2 | 29.316509 | 0.84338115 | 38.411085 | 0.94900884 |
| experiments | ./models/esrgan/smallX2BestValGeneratorLossEpoch500 | 2 | 29.316172 | 0.84315012 | 38.449311 | 0.94913112 |
| experiments | ./models/esrgan/smallX2Epoch486 | 2 | 29.299434 | 0.84244475 | 38.49901 | 0.948426 |
| experiments | ./models/esrgan/smallX2Epoch497 | 2 | 29.291474 | 0.84268758 | 38.280472 | 0.94858618 |
| experiments | ./models/esrgan/smallX2BestValGeneratorPSNRYEpoch488 | 2 | 29.289172 | 0.84285561 | 38.358158 | 0.94887576 |
| experiments | ./models/esrgan/smallX2Epoch481 | 2 | 29.288401 | 0.84241617 | 38.2361 | 0.94775514 |
| experiments | ./models/esrgan/largeX2BestValGeneratorLossEpoch144 | 2 | 29.27155 | 0.84651189 | 38.48917 | 0.94990327 |
| experiments | ./models/esrgan/largeX2BestValLossEpoch125 | 2 | 29.240104 | 0.84256588 | 38.42608101 | 0.945688342 |
| experiments | ./models/esrgan/smallX2Epoch478 | 2 | 29.186754 | 0.84215613 | 37.823449 | 0.9481251 |
| experiments | ./models/esrgan/largeX2BestValLossEpoch118 | 2 | 29.136786 | 0.84244801 | 37.787544 | 0.94570022 |
| experiments | ./models/esrgan/largeX2BestValGeneratorPSNRYEpoch117 | 2 | 29.130285 | 0.84360373 | 36.576953 | 0.94439399 |
| experiments | ./models/esrgan/largeX2BestValLossEpoch108 | 2 | 29.114004 | 0.84022983 | 37.675649 | 0.94420246 |
| experiments | ./models/esrgan/largeX2BestValGeneratorPSNRYEpoch115 | 2 | 29.050153 | 0.8392995 | 37.820271 | 0.94392661 |
| experiments | ./models/esrgan/largeX2BestValLossEpoch110 | 2 | 29.01316 | 0.84014484 | 36.607466 | 0.94369212 |
| experiments | ./models/esrgan/largeX2BestValGeneratorLossEpoch109 | 2 | 28.973534 | 0.83935015 | 37.781943 | 0.94368613 |
| experiments | ./models/esrgan/largeX2BestValGeneratorPSNRYEpoch116 | 2 | 28.949734 | 0.84049108 | 36.827089 | 0.94234112 |
| experiments | ./models/esrgan/largeX2BestValLossEpoch103 | 2 | 28.912322 | 0.83979972 | 36.468039 | 0.94263805 |
| experiments | ./models/esrgan/largeX2Epoch113 | 2 | 28.766887 | 0.84046537 | 34.678129 | 0.94273357 |
| experiments | ./models/esrgan/largeX2Epoch106 | 2 | 28.734594 | 0.83821363 | 34.431993 | 0.94116773 |
| experiments | ./models/esrgan/largeX2Epoch131 | 2 | 28.592802 | 0.8437225 | 33.958521 | 0.94655065 |
| experiments | ./models/esrgan/largeX2Epoch134 | 2 | 28.580048 | 0.84463256 | --- | --- |
| experiments | ./models/esrgan/largeX2Epoch101 | 2 | 28.164215 | 0.83728719 | 34.270922 | 0.93943042 |
| experiments | ./models/esrgan/largeX2Epoch086 | 2 | 27.955465 | 0.82730093 | 32.887924 | 0.92534744 |
| experiments | ./models/esrgan/largeX3BestValLossEpoch483 | 3 | 27.930101 | 0.76997314 | 37.195875 | 0.92217836 |
| experiments | ./models/esrgan/largeX3Epoch486 | 3 | 27.923314 | 0.76993252 | 37.148674 | 0.92205608 |
| experiments | ./models/esrgan/largeX3Epoch492 | 3 | 27.923297 | 0.76950046 | 37.154917 | 0.92207845 |
| experiments | ./models/esrgan/largeX3Epoch498 | 3 | 27.917191 | 0.76937055 | 37.261687 | 0.92200296 |
| experiments | ./models/esrgan/largeX3BestValGeneratorLossEpoch487 | 3 | 27.91141 | 0.76968047 | 37.037256 | 0.92229158 |
| experiments | ./models/esrgan/largeX3BestValGeneratorPSNRYEpoch477 | 3 | 27.909515 | 0.76919871 | 37.259154 | 0.922306 |
| experiments | ./models/esrgan/largeX3BestValGeneratorLossEpoch467 | 3 | 27.89616 | 0.76888922 | 37.145588 | 0.92177542 |
| experiments | ./models/esrgan/largeX3BestValGeneratorPSNRYEpoch489 | 3 | 27.881491 | 0.76958529 | 36.986895 | 0.92196656 |
| experiments | ./models/esrgan/largeX3Epoch495 | 3 | 27.841755 | 0.76899711 | 36.092648 | 0.92140626 |
| experiments | ./models/esrgan/largeX3Epoch480 | 3 | 27.785917 | 0.76847234 | 36.757051 | 0.92175204 |
| experiments | ./models/esrgan/mediumX3Epoch495 | 3 | 27.225753 | 0.74189719 | 36.165203 | 0.89044268 |
| experiments | ./models/esrgan/mediumX3BestValLossEpoch488 | 3 | 27.215493 | 0.74092191 | 36.141801 | 0.89024014 |
| experiments | ./models/esrgan/mediumX3BestValGeneratorPSNRYEpoch492 | 3 | 27.209672 | 0.74133133 | 36.175873 | 0.89054778 |
| experiments | ./models/esrgan/mediumX3BestValGeneratorPSNRYEpoch480 | 3 | 27.206913 | 0.74076081 | 36.091292 | 0.88985828 |
| experiments | ./models/esrgan/mediumX3Epoch483 | 3 | 27.200619 | 0.74000698 | 36.093033 | 0.88919697 |
| experiments | ./models/esrgan/mediumX3Epoch498 | 3 | 27.190878 | 0.74104545 | 36.04977 | 0.88929815 |
| experiments | ./models/esrgan/mediumX3BestValGeneratorLossEpoch500 | 3 | 27.181063 | 0.74032609 | 35.828395 | 0.88848587 |
| experiments | ./models/esrgan/mediumX3Epoch478 | 3 | 27.175365 | 0.73964297 | 36.027929 | 0.89020177 |
| experiments | ./models/esrgan/mediumX3BestValGeneratorLossEpoch490 | 3 | 27.164338 | 0.73954862 | 35.989053 | 0.88828852 |
| experiments | ./models/esrgan/mediumX3Epoch486 | 3 | 27.15114 | 0.73950855 | 35.884519 | 0.88812131 |
| experiments | ./models/esrgan/largeX3RrdnC4D3G32G064T10X3Patchsize129Compress50Sharpen0Datadiv2kVaryCTrueBestValLossEpoch204 | 3 | 27.106496 | 0.73293484 | 36.52427 | 0.90964139 |
| esrgan-legacy | ./div2k/2x | 2 | 27.094269 | 0.81064853 | 30.064827 | 0.83942758 |
| experiments | ./models/esrgan/largeX3RrdnC4D3G32G064T10X3Patchsize129Compress50Sharpen0Datadiv2kVaryCTrueBestValGeneratorLossEpoch203 | 3 | 27.048304 | 0.731169 | 36.377719 | 0.90867343 |
| experiments | ./models/esrgan/largeX3RrdnC4D3G32G064T10X3Patchsize129Compress50Sharpen0Datadiv2kVaryCTrueEpoch199 | 3 | 26.992399 | 0.73196258 | 35.793207 | 0.909843 |
| experiments | ./models/esrgan/largeX3RrdnC4D3G32G064T10X3Patchsize129Compress50Sharpen0Datadiv2kVaryCTrueEpoch195 | 3 | 26.97323 | 0.7340286 | 34.76776 | 0.91233764 |
| experiments | ./models/esrgan/largeX3RrdnC4D3G32G064T10X3Patchsize129Compress50Sharpen0Datadiv2kVaryCTrueEpoch183 | 3 | 26.961258 | 0.72839426 | 36.103623 | 0.90695503 |
| experiments | ./models/esrgan/smallX3BestValGeneratorLossEpoch490 | 3 | 26.956705 | 0.73318226 | 35.216788 | 0.88123119 |
| experiments | ./models/esrgan/largeX3RrdnC4D3G32G064T10X3Patchsize129Compress50Sharpen0Datadiv2kVaryCTrueEpoch202 | 3 | 26.950905 | 0.7318801 | 35.636683 | 0.9090585 |
| experiments | ./models/esrgan/smallX3BestValGeneratorLossEpoch485 | 3 | 26.947149 | 0.73219714 | 35.271728 | 0.88110456 |
| experiments | ./models/esrgan/smallX3Epoch482 | 3 | 26.944849 | 0.73315113 | 35.106677 | 0.88088022 |
| experiments | ./models/esrgan/smallX3BestValGeneratorPSNRYEpoch499 | 3 | 26.944139 | 0.73296818 | 35.225245 | 0.881055 |
| experiments | ./models/esrgan/smallX3Epoch488 | 3 | 26.943427 | 0.73287438 | 35.225376 | 0.88130213 |
| experiments | ./models/esrgan/smallX3Epoch497 | 3 | 26.942371 | 0.73292966 | 35.207652 | 0.88139095 |
| experiments | ./models/esrgan/largeX3RrdnC4D3G32G064T10X3Patchsize129Compress50Sharpen0Datadiv2kVaryCTrueBestValGeneratorLossEpoch192 | 3 | 26.93693 | 0.73228909 | 35.71228 | 0.90793748 |
| experiments | ./models/esrgan/smallX3Epoch494 | 3 | 26.928907 | 0.73339229 | 35.136489 | 0.8821625 |
| experiments | ./models/esrgan/smallX3BestValGeneratorLossEpoch489 | 3 | 26.928312 | 0.73224235 | 35.196332 | 0.88104686 |
| experiments | ./models/esrgan/smallX3BestValGeneratorPSNRYEpoch491 | 3 | 26.924073 | 0.73290476 | 35.029316 | 0.88131867 |
| experiments | ./models/esrgan/smallX3Epoch477 | 3 | 26.918198 | 0.732795 | 35.035524 | 0.88107192 |
| experiments | ./models/esrgan/largeX3RrdnC4D3G32G064T10X3Patchsize129Compress50Sharpen0Datadiv2kVaryCTrueBestValGeneratorPSNRYEpoch196 | 3 | 26.807945 | 0.73277899 | 35.301891 | 0.90904872 |
| experiments | ./models/esrgan/mediumX3RdnC1D10G64G064T10X3Patchsize129Compress50Sharpen0Datadiv2kVaryCTrueBestValGeneratorLossEpoch499 | 3 | 26.768701 | 0.72033017 | 34.995539 | 0.87221942 |
| experiments | ./models/esrgan/mediumX3RdnC1D10G64G064T10X3Patchsize129Compress50Sharpen0Datadiv2kVaryCTrueBestValLossEpoch488 | 3 | 26.75373 | 0.71963853 | 35.034866 | 0.87102964 |
| experiments | ./models/esrgan/mediumX3RdnC1D10G64G064T10X3Patchsize129Compress50Sharpen0Datadiv2kVaryCTrueBestValGeneratorLossEpoch498 | 3 | 26.748537 | 0.71915809 | 34.929976 | 0.8723258 |
| experiments | ./models/esrgan/mediumX3RdnC1D10G64G064T10X3Patchsize129Compress50Sharpen0Datadiv2kVaryCTrueEpoch480 | 3 | 26.742117 | 0.71866565 | 35.016386 | 0.87161909 |
| experiments | ./models/esrgan/largeX3RrdnC4D3G32G064T10X3Patchsize129Compress50Sharpen0Datadiv2kVaryCTrueEpoch186 | 3 | 26.733094 | 0.72892455 | 34.513119 | 0.91010811 |
| experiments | ./models/esrgan/smallX3RdnC1D2G4G064T10X3Patchsize129Compress50Sharpen0Datadiv2kVaryCTrueEpoch489 | 3 | 26.72651 | 0.72011914 | 34.844689 | 0.86754737 |
| experiments | ./models/esrgan/smallX3RdnC1D2G4G064T10X3Patchsize129Compress50Sharpen0Datadiv2kVaryCTrueBestValGeneratorPSNRYEpoch478 | 3 | 26.720652 | 0.72056828 | 34.642479 | 0.86689062 |
| experiments | ./models/esrgan/smallX3RdnC1D2G4G064T10X3Patchsize129Compress50Sharpen0Datadiv2kVaryCTrueBestValGeneratorLossEpoch480 | 3 | 26.716462 | 0.7200029 | 34.803042 | 0.86773579 |
| experiments | ./models/esrgan/smallX3RdnC1D2G4G064T10X3Patchsize129Compress50Sharpen0Datadiv2kVaryCTrueBestValGeneratorLossEpoch482 | 3 | 26.713729 | 0.71982235 | 34.783559 | 0.86744662 |
| experiments | ./models/esrgan/mediumX3RdnC1D10G64G064T10X3Patchsize129Compress50Sharpen0Datadiv2kVaryCTrueBestValLossEpoch497 | 3 | 26.71282 | 0.71903044 | 34.905436 | 0.87183573 |
| experiments | ./models/esrgan/smallX3RdnC1D2G4G064T10X3Patchsize129Compress50Sharpen0Datadiv2kVaryCTrueBestValGeneratorPSNRYEpoch474 | 3 | 26.711128 | 0.71996633 | 34.727586 | 0.86727797 |
| experiments | ./models/esrgan/smallX3RdnC1D2G4G064T10X3Patchsize129Compress50Sharpen0Datadiv2kVaryCTrueEpoch492 | 3 | 26.710465 | 0.72018824 | 34.778183 | 0.86716451 |
| experiments | ./models/esrgan/smallX3RdnC1D2G4G064T10X3Patchsize129Compress50Sharpen0Datadiv2kVaryCTrueBestValGeneratorPSNRYEpoch483 | 3 | 26.710426 | 0.7206586 | 34.746806 | 0.86808424 |
| experiments | ./models/esrgan/largeX2Epoch093 | 2 | 26.706247 | 0.83023461 | 28.815863 | 0.93199945 |
| experiments | ./models/esrgan/smallX3RdnC1D2G4G064T10X3Patchsize129Compress50Sharpen0Datadiv2kVaryCTrueEpoch486 | 3 | 26.705605 | 0.7194477 | 34.726334 | 0.86703404 |
| experiments | ./models/esrgan/smallX3RdnC1D2G4G064T10X3Patchsize129Compress50Sharpen0Datadiv2kVaryCTrueEpoch498 | 3 | 26.704985 | 0.71911327 | 34.77489 | 0.86747124 |
| experiments | ./models/esrgan/mediumX3RdnC1D10G64G064T10X3Patchsize129Compress50Sharpen0Datadiv2kVaryCTrueBestValGeneratorLossEpoch495 | 3 | 26.704975 | 0.71875961 | 34.791808 | 0.87158383 |
| experiments | ./models/esrgan/mediumX3RdnC1D10G64G064T10X3Patchsize129Compress50Sharpen0Datadiv2kVaryCTrueEpoch494 | 3 | 26.692782 | 0.71735841 | 34.835928 | 0.87058884 |
| experiments | ./models/esrgan/mediumX3RdnC1D10G64G064T10X3Patchsize129Compress50Sharpen0Datadiv2kVaryCTrueEpoch483 | 3 | 26.689034 | 0.71931162 | 34.607023 | 0.87121959 |
| experiments | ./models/esrgan/smallX3RdnC1D2G4G064T10X3Patchsize129Compress50Sharpen0Datadiv2kVaryCTrueEpoch495 | 3 | 26.683691 | 0.71753965 | 34.7926 | 0.86703853 |
| experiments | ./models/esrgan/mediumX3RdnC1D10G64G064T10X3Patchsize129Compress50Sharpen0Datadiv2kVaryCTrueEpoch491 | 3 | 26.682242 | 0.71724885 | 34.872402 | 0.87075604 |
| experiments | ./models/esrgan/mediumX3RdnC1D10G64G064T10X3Patchsize129Compress50Sharpen0Datadiv2kVaryCTrueEpoch486 | 3 | 26.60362 | 0.71913531 | 34.122965 | 0.87056607 |
| experiments | ./models/esrgan/largeX4BestValGeneratorPSNRYEpoch499 | 4 | 26.305065 | 0.68564815 | --- | --- |
| experiments | ./models/esrgan/largeX4BestValLossEpoch478 | 4 | 26.295849 | 0.68558038 | --- | --- |
| experiments | ./models/esrgan/largeX4Epoch491 | 4 | 26.290882 | 0.68527363 | --- | --- |
| experiments | ./models/esrgan/largeX4BestValGeneratorPSNRYEpoch488 | 4 | 26.290837 | 0.68555381 | --- | --- |
| experiments | ./models/esrgan/largeX4BestValGeneratorLossEpoch480 | 4 | 26.286791 | 0.68519037 | --- | --- |
| experiments | ./models/esrgan/largeX4BestValGeneratorPSNRYEpoch476 | 4 | 26.286697 | 0.68513463 | --- | --- |
| experiments | ./models/esrgan/largeX4Epoch486 | 4 | 26.273185 | 0.68526469 | --- | --- |
| esrgan-legacy | ./gans | 4 | 25.649999 | 0.66803822 | 33.716107 | 0.8542771 |
| esrgan-slim | . | 4 | 25.649999 | 0.66803822 | 33.716107 | 0.8542771 |
| experiments | ./models/esrgan/mediumX4BestValLossEpoch490 | 4 | 25.516175 | 0.64578005 | 34.690461 | 0.86061027 |
| experiments | ./models/esrgan/mediumX4BestValGeneratorLossEpoch491 | 4 | 25.510134 | 0.64501837 | 34.656584 | 0.85923085 |
| experiments | ./models/esrgan/mediumX4BestValGeneratorLossEpoch489 | 4 | 25.50044 | 0.64471462 | 34.643183 | 0.85944289 |
| experiments | ./models/esrgan/mediumX4BestValLossEpoch492 | 4 | 25.495334 | 0.64452954 | 34.656087 | 0.8588406 |
| experiments | ./models/esrgan/mediumX4Epoch498 | 4 | 25.494693 | 0.64514958 | 34.559716 | 0.86049618 |
| experiments | ./models/esrgan/mediumX4BestValLossEpoch487 | 4 | 25.490715 | 0.64400646 | 34.638818 | 0.85801655 |
| experiments | ./models/esrgan/mediumX4Epoch466 | 4 | 25.477304 | 0.6442963 | 34.57324 | 0.8595968 |
| experiments | ./models/esrgan/mediumX4Epoch480 | 4 | 25.452068 | 0.64275861 | 34.483031 | 0.85714784 |
| experiments | ./models/esrgan/mediumX4Epoch486 | 4 | 25.439638 | 0.64220874 | 34.355034 | 0.85526831 |
| experiments | ./models/esrgan/mediumX4Epoch495 | 4 | 25.406668 | 0.64373078 | 33.856489 | 0.85718488 |
| experiments | ./models/esrgan/smallX4Epoch469 | 4 | 25.320131 | 0.63794742 | 33.992109 | 0.84429595 |
| experiments | ./models/esrgan/smallX4BestValGeneratorPSNRYEpoch495 | 4 | 25.318115 | 0.63824099 | 33.926836 | 0.84487074 |
| experiments | ./models/esrgan/smallX4BestValGeneratorLossEpoch493 | 4 | 25.306135 | 0.63692146 | 33.910273 | 0.8411776 |
| experiments | ./models/esrgan/smallX4BestValLossEpoch490 | 4 | 25.296763 | 0.63608295 | 33.853387 | 0.84028661 |
| experiments | ./models/esrgan/smallX4Epoch498 | 4 | 25.290379 | 0.63566033 | 33.8339 | 0.84027772 |
| experiments | ./models/esrgan/smallX4Epoch486 | 4 | 25.287989 | 0.63687354 | 33.85752 | 0.84218836 |
| experiments | ./models/esrgan/smallX4BestValGeneratorLossEpoch491 | 4 | 25.287402 | 0.63642592 | 33.81488 | 0.84108363 |
| experiments | ./models/esrgan/smallX4Epoch480 | 4 | 25.285309 | 0.63659179 | 33.780253 | 0.84129552 |
| experiments | ./models/esrgan/smallX4BestValGeneratorLossEpoch494 | 4 | 25.283954 | 0.63710508 | 33.765919 | 0.84155131 |
| experiments | ./models/esrgan/smallX4Epoch483 | 4 | 25.282183 | 0.63703222 | 33.843838 | 0.84318863 |
| experiments | ./models/esrgan/mediumX4RdnC1D10G64G064T10X4Patchsize128Compress50Sharpen0Datadiv2kVaryCTrueBestValLossEpoch462 | 4 | 25.138729 | 0.62592211 | 33.409023 | 0.83826773 |
| experiments | ./models/esrgan/smallX4RdnC1D2G4G064T10X4Patchsize128Compress50Sharpen0Datadiv2kVaryCTrueEpoch485 | 4 | 25.133003 | 0.62719865 | 33.522005 | 0.83764591 |
| experiments | ./models/esrgan/mediumX4RdnC1D10G64G064T10X4Patchsize128Compress50Sharpen0Datadiv2kVaryCTrueEpoch490 | 4 | 25.131883 | 0.62524904 | 33.535911 | 0.83943019 |
| experiments | ./models/esrgan/smallX4RdnC1D2G4G064T10X4Patchsize128Compress50Sharpen0Datadiv2kVaryCTrueEpoch497 | 4 | 25.130666 | 0.62666721 | 33.529444 | 0.83851789 |
| experiments | ./models/esrgan/mediumX4RdnC1D10G64G064T10X4Patchsize128Compress50Sharpen0Datadiv2kVaryCTrueBestValGeneratorLossEpoch479 | 4 | 25.125082 | 0.62753685 | 33.274045 | 0.83746676 |
| experiments | ./models/esrgan/smallX4RdnC1D2G4G064T10X4Patchsize128Compress50Sharpen0Datadiv2kVaryCTrueBestValGeneratorPSNRYEpoch465 | 4 | 25.122535 | 0.62633243 | 33.478533 | 0.83700643 |
| experiments | ./models/esrgan/smallX4RdnC1D2G4G064T10X4Patchsize128Compress50Sharpen0Datadiv2kVaryCTrueBestValLossEpoch499 | 4 | 25.119118 | 0.62608503 | 33.538256 | 0.83853002 |
| experiments | ./models/esrgan/mediumX4RdnC1D10G64G064T10X4Patchsize128Compress50Sharpen0Datadiv2kVaryCTrueBestValGeneratorPSNRYEpoch484 | 4 | 25.118637 | 0.62687593 | 33.341797 | 0.83967847 |
| experiments | ./models/esrgan/smallX4RdnC1D2G4G064T10X4Patchsize128Compress50Sharpen0Datadiv2kVaryCTrueBestValGeneratorLossEpoch482 | 4 | 25.116082 | 0.62654996 | 33.488366 | 0.83800515 |
| experiments | ./models/esrgan/mediumX4RdnC1D10G64G064T10X4Patchsize128Compress50Sharpen0Datadiv2kVaryCTrueEpoch487 | 4 | 25.109375 | 0.62614912 | 33.254299 | 0.83896569 |
| experiments | ./models/esrgan/mediumX4RdnC1D10G64G064T10X4Patchsize128Compress50Sharpen0Datadiv2kVaryCTrueBestValLossEpoch475 | 4 | 25.109305 | 0.62525731 | 33.288131 | 0.83838372 |
| experiments | ./models/esrgan/smallX4RdnC1D2G4G064T10X4Patchsize128Compress50Sharpen0Datadiv2kVaryCTrueEpoch494 | 4 | 25.102916 | 0.62463399 | 33.525833 | 0.83806977 |
| experiments | ./models/esrgan/smallX4RdnC1D2G4G064T10X4Patchsize128Compress50Sharpen0Datadiv2kVaryCTrueBestValGeneratorLossEpoch478 | 4 | 25.101258 | 0.62554172 | 33.512563 | 0.8372539 |
| experiments | ./models/esrgan/mediumX4RdnC1D10G64G064T10X4Patchsize128Compress50Sharpen0Datadiv2kVaryCTrueEpoch493 | 4 | 25.098679 | 0.6250523 | 33.212868 | 0.83850204 |
| experiments | ./models/esrgan/smallX4RdnC1D2G4G064T10X4Patchsize128Compress50Sharpen0Datadiv2kVaryCTrueEpoch488 | 4 | 25.095446 | 0.62682867 | 33.373683 | 0.83812866 |
| experiments | ./models/esrgan/smallX4RdnC1D2G4G064T10X4Patchsize128Compress50Sharpen0Datadiv2kVaryCTrueBestValGeneratorPSNRYEpoch460 | 4 | 25.09 | 0.62585725 | 33.46495 | 0.83638434 |
| experiments | ./models/esrgan/smallX4RdnC1D2G4G064T10X4Patchsize128Compress50Sharpen0Datadiv2kVaryCTrueEpoch491 | 4 | 25.089867 | 0.62408923 | 33.450158 | 0.83652135 |
| experiments | ./models/esrgan/mediumX4RdnC1D10G64G064T10X4Patchsize128Compress50Sharpen0Datadiv2kVaryCTrueBestValGeneratorPSNRYEpoch473 | 4 | 25.079226 | 0.62673999 | 32.983699 | 0.83782711 |
| experiments | ./models/esrgan/mediumX4RdnC1D10G64G064T10X4Patchsize128Compress50Sharpen0Datadiv2kVaryCTrueEpoch499 | 4 | 25.074844 | 0.62606697 | 32.924446 | 0.83785955 |
| experiments | ./models/esrgan/mediumX4RdnC1D10G64G064T10X4Patchsize128Compress50Sharpen0Datadiv2kVaryCTrueEpoch496 | 4 | 25.049933 | 0.62584673 | 32.892611 | 0.83971219 |
| experiments | ./models/esrgan/largeX8Epoch494 | 8 | 23.443564 | 0.522546237 | --- | --- |
| experiments | ./models/esrgan/largeX8BestValGeneratorLossEpoch474 | 8 | 23.439513 | 0.522427447 | --- | --- |
| experiments | ./models/esrgan/largeX8BestValLossEpoch486 | 8 | 23.438326 | 0.522269854 | --- | --- |
| experiments | ./models/esrgan/largeX8BestValLossEpoch488 | 8 | 23.43366 | 0.522198085 | --- | --- |
| experiments | ./models/esrgan/largeX8BestValLossEpoch470 | 8 | 23.432424 | 0.52209714 | --- | --- |
| experiments | ./models/esrgan/largeX8Epoch497 | 8 | 23.431365 | 0.522017486 | --- | --- |
| experiments | ./models/esrgan/largeX8Epoch500 | 8 | 23.430308 | 0.522380473 | --- | --- |
| experiments | ./models/esrgan/largeX8BestValGeneratorPSNRYEpoch482 | 8 | 23.429303 | 0.522212003 | --- | --- |
| experiments | ./models/esrgan/largeX8Epoch491 | 8 | 23.428217 | 0.521827288 | --- | --- |
| experiments | ./models/esrgan/largeX8Epoch485 | 8 | 23.417453 | 0.521736284 | --- | --- |
| experiments | ./models/esrgan/mediumX8Epoch483 | 8 | 22.440909 | 0.462206317 | 30.733873 | 0.75275201 |
| experiments | ./models/esrgan/mediumX8BestValLossEpoch480 | 8 | 22.434487 | 0.461677502 | 30.692165 | 0.74993526 |
| experiments | ./models/esrgan/mediumX8BestValGeneratorLossEpoch488 | 8 | 22.425492 | 0.461062167 | 30.670107 | 0.75052999 |
| experiments | ./models/esrgan/mediumX8Epoch478 | 8 | 22.425456 | 0.461090191 | 30.685753 | 0.74977743 |
| experiments | ./models/esrgan/mediumX8Epoch495 | 8 | 22.425439 | 0.461473717 | 30.638027 | 0.75127478 |
| experiments | ./models/esrgan/mediumX8BestValGeneratorPSNRYEpoch489 | 8 | 22.423706 | 0.461224568 | 30.672953 | 0.74958716 |
| experiments | ./models/esrgan/mediumX8BestValLossEpoch492 | 8 | 22.420845 | 0.461194363 | 30.577952 | 0.74935149 |
| experiments | ./models/esrgan/mediumX8BestValGeneratorLossEpoch475 | 8 | 22.420093 | 0.461152177 | 30.676997 | 0.74963651 |
| experiments | ./models/esrgan/mediumX8Epoch486 | 8 | 22.417385 | 0.461126529 | 30.670189 | 0.74982903 |
| experiments | ./models/esrgan/mediumX8Epoch498 | 8 | 22.406215 | 0.461052889 | 30.456398 | 0.74843018 |
| experiments | ./models/esrgan/smallX8BestValGeneratorLossEpoch487 | 8 | 22.386646 | 0.460533677 | 30.43325 | 0.74331897 |
| experiments | ./models/esrgan/smallX8Epoch493 | 8 | 22.386563 | 0.460644747 | 30.438012 | 0.74341667 |
| experiments | ./models/esrgan/smallX8BestValLossEpoch477 | 8 | 22.382262 | 0.460706946 | 30.439114 | 0.74383908 |
| experiments | ./models/esrgan/smallX8Epoch486 | 8 | 22.379881 | 0.460877718 | 30.340109 | 0.74378033 |
| experiments | ./models/esrgan/smallX8Epoch490 | 8 | 22.378968 | 0.460779724 | 30.435332 | 0.74444157 |
| experiments | ./models/esrgan/smallX8BestValGeneratorPSNRYEpoch496 | 8 | 22.376733 | 0.46078248 | 30.426631 | 0.74382691 |
| experiments | ./models/esrgan/smallX8BestValGeneratorLossEpoch495 | 8 | 22.376119 | 0.460758331 | 30.405033 | 0.74370696 |
| experiments | ./models/esrgan/smallX8Epoch483 | 8 | 22.371997 | 0.460675519 | 30.326725 | 0.74352493 |
| experiments | ./models/esrgan/smallX8BestValGeneratorLossEpoch500 | 8 | 22.368865 | 0.460322787 | 30.393329 | 0.74238165 |
| experiments | ./models/esrgan/smallX8Epoch499 | 8 | 22.364259 | 0.460835839 | 30.380576 | 0.74291945 |
| experiments | ./models/esrgan/smallX8RdnC1D2G4G064T10X8Patchsize128Compress50Sharpen0Datadiv2kVaryCTrueEpoch487 | 8 | 22.20832 | 0.454452652 | 29.44479 | 0.73949023 |
| experiments | ./models/esrgan/smallX8RdnC1D2G4G064T10X8Patchsize128Compress50Sharpen0Datadiv2kVaryCTrueBestValLossEpoch456 | 8 | 22.202931 | 0.454356586 | 29.442219 | 0.7390724 |
| experiments | ./models/esrgan/mediumX8RdnC1D10G64G064T10X8Patchsize128Compress50Sharpen0Datadiv2kVaryCTrueBestValGeneratorLossEpoch488 | 8 | 22.186665 | 0.455039754 | 29.763783 | 0.74857137 |
| experiments | ./models/esrgan/smallX8RdnC1D2G4G064T10X8Patchsize128Compress50Sharpen0Datadiv2kVaryCTrueBestValLossEpoch497 | 8 | 22.182946 | 0.454355114 | 29.22403 | 0.73823963 |
| experiments | ./models/esrgan/smallX8RdnC1D2G4G064T10X8Patchsize128Compress50Sharpen0Datadiv2kVaryCTrueBestValGeneratorPSNRYEpoch457 | 8 | 22.182805 | 0.454053871 | 29.282474 | 0.73755478 |
| experiments | ./models/esrgan/smallX8RdnC1D2G4G064T10X8Patchsize128Compress50Sharpen0Datadiv2kVaryCTrueEpoch500 | 8 | 22.182327 | 0.454209903 | 29.175102 | 0.73831519 |
| experiments | ./models/esrgan/smallX8RdnC1D2G4G064T10X8Patchsize128Compress50Sharpen0Datadiv2kVaryCTrueEpoch493 | 8 | 22.182243 | 0.454118907 | 29.298442 | 0.7401866 |
| experiments | ./models/esrgan/smallX8RdnC1D2G4G064T10X8Patchsize128Compress50Sharpen0Datadiv2kVaryCTrueBestValGeneratorPSNRYEpoch462 | 8 | 22.180004 | 0.454411991 | 29.172155 | 0.73820693 |
| experiments | ./models/esrgan/mediumX8RdnC1D10G64G064T10X8Patchsize128Compress50Sharpen0Datadiv2kVaryCTrueBestValGeneratorPSNRYEpoch461 | 8 | 22.17605 | 0.453448123 | 29.759987 | 0.74463586 |
| experiments | ./models/esrgan/smallX8RdnC1D2G4G064T10X8Patchsize128Compress50Sharpen0Datadiv2kVaryCTrueEpoch496 | 8 | 22.17213 | 0.454803664 | 29.092512 | 0.73982237 |
| experiments | ./models/esrgan/smallX8RdnC1D2G4G064T10X8Patchsize128Compress50Sharpen0Datadiv2kVaryCTrueEpoch490 | 8 | 22.17164 | 0.454425286 | 28.964495 | 0.73855017 |
| experiments | ./models/esrgan/smallX8RdnC1D2G4G064T10X8Patchsize128Compress50Sharpen0Datadiv2kVaryCTrueBestValGeneratorLossEpoch472 | 8 | 22.169933 | 0.454232891 | 28.878073 | 0.73690089 |
| experiments | ./models/esrgan/mediumX8RdnC1D10G64G064T10X8Patchsize128Compress50Sharpen0Datadiv2kVaryCTrueEpoch491 | 8 | 22.168992 | 0.455586644 | 29.762178 | 0.75047743 |
| experiments | ./models/esrgan/mediumX8RdnC1D10G64G064T10X8Patchsize128Compress50Sharpen0Datadiv2kVaryCTrueEpoch487 | 8 | 22.168058 | 0.454852261 | 29.733748 | 0.74822827 |
| experiments | ./models/esrgan/mediumX8RdnC1D10G64G064T10X8Patchsize128Compress50Sharpen0Datadiv2kVaryCTrueBestValLossEpoch476 | 8 | 22.164326 | 0.455447706 | 29.545824 | 0.74632629 |
| experiments | ./models/esrgan/mediumX8RdnC1D10G64G064T10X8Patchsize128Compress50Sharpen0Datadiv2kVaryCTrueEpoch482 | 8 | 22.164207 | 0.454810763 | 29.547912 | 0.74805385 |
| experiments | ./models/esrgan/mediumX8RdnC1D10G64G064T10X8Patchsize128Compress50Sharpen0Datadiv2kVaryCTrueBestValGeneratorLossEpoch484 | 8 | 22.151611 | 0.455174547 | 29.608545 | 0.74736985 |
| experiments | ./models/esrgan/mediumX8RdnC1D10G64G064T10X8Patchsize128Compress50Sharpen0Datadiv2kVaryCTrueBestValLossEpoch494 | 8 | 22.140673 | 0.454886558 | 29.67571 | 0.74776154 |
| experiments | ./models/esrgan/mediumX8RdnC1D10G64G064T10X8Patchsize128Compress50Sharpen0Datadiv2kVaryCTrueEpoch500 | 8 | 22.098376 | 0.454436156 | 29.286125 | 0.74576661 |
| experiments | ./models/esrgan/mediumX8RdnC1D10G64G064T10X8Patchsize128Compress50Sharpen0Datadiv2kVaryCTrueEpoch497 | 8 | 21.988673 | 0.454076416 | 29.062481 | 0.7476624 |
| esrgan-legacy | ./div2k/3x | 3 | 21.672843 | 0.68057247 | 21.27948 | 0.82260103 |
| esrgan-legacy | ./div2k/4x | 4 | 19.886133 | 0.58683426 | 20.242761 | 0.76487683 |
| experiments | ./models/esrgan/smallX3BestValLossEpoch008 | 3 | 19.412768 | 0.467144073 | 20.477769 | 0.67834534 |
| experiments | ./models/esrgan/smallX3BestValLossEpoch007 | 3 | 18.935227 | 0.452510521 | 18.880078 | 0.66321491 |
| experiments | ./models/esrgan/smallX3BestValGeneratorLossEpoch009 | 3 | 18.526467 | 0.47791141 | 18.014888 | 0.67732242 |
| experiments | ./models/esrgan/smallX3BestValLossEpoch005 | 3 | 17.402387 | 0.41016145 | 16.114054 | 0.61564335 |
| experiments | ./models/esrgan/smallX3BestValGeneratorLossEpoch006 | 3 | 17.156218 | 0.425942757 | 15.53352 | 0.6329215 |
To a previous comment of yours:
Last time I checked, the results from div2k weren't nearly as good as the esrgan-legacy/gans
What's interesting is that these benchmarks prove it out; the div2k/3x and div2k/4x models are almost at the bottom of these benchmark results, and the div2k/2x scores worse than every other 2x model.
I've just released three model packages:
@upscalerjs/esrgan-slim@upscalerjs/esrgan-medium@upscalerjs/esrgan-thick
Previously esrgan-slim was the "default" model; I've renamed that to default-model (which is the 2x model exported via esrgan-slim).
Model docs are here and you can see performance / speed charts of all of 'em.