xGeMM
 xGeMM copied to clipboard
xGeMM copied to clipboard
Accelerated General (FP32) Matrix Multiplication from scratch in CUDA
xGeMM
Accelerated General (FP32) Matrix Multiplication. Tested on NVIDIA RTX 3090 using Ubuntu 24.04.1 LTS with nvidia-driver-550 and CUDA 12.4.
Watch the YouTube video (click the image below)
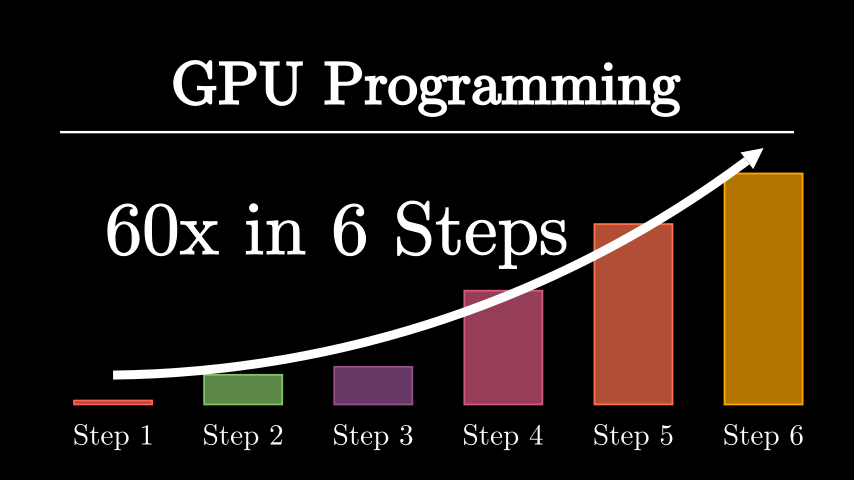
Dependencies
- Eigen 3.4.0 (Put it in
lib)
Running Benchmarks
1. Eigen (CPU) matrix multiplication
Compile: make 00a_benchmark_cpu.out
Execute: ./00a_benchmark_cpu.out
2. cuBLAS (GPU) matrix multiplication:
Compile: make 00b_benchmark_cuBLAS.out
Execute: ./00b_benchmark_cuBLAS.out
3. Naive (GPU) matrix multiplication:
Compile: make 01_benchmark_naive.out
Execute: ./01_benchmark_naive.out
4. Coalesced (GPU) matrix multiplication:
Compile: make 02_benchmark_coalesced.out
Execute: ./02_benchmark_coalesced.out
5. Tiled (GPU) matrix multiplication:
Compile: make 03_benchmark_tiled.out
Execute: ./03_benchmark_tiled.out
6. 1D thread coarsening (GPU) matrix multiplication:
Compile: make 04_benchmark_coarse_1d.out
Execute: ./04_benchmark_coarse_1d.out
7. 2D thread coarsening (GPU) matrix multiplication:
Compile: make 05_benchmark_coarse_2d.out
Execute: ./05_benchmark_coarse_2d.out
8. Vectorized Mmemory accesses (GPU) matrix multiplication:
Compile: make 06_benchmark_coarse_2d_vec.out
Execute: ./06_benchmark_coarse_2d_vec.out