wazero
 wazero copied to clipboard
wazero copied to clipboard
compiler: optimize bulk memory operations
Currently the assembly implementations of memory.copy and memory.fill (and table equivalents) are pretty native
and simply do the for-loop copying one by one.
amd64: https://github.com/tetratelabs/wazero/blob/266320e257e6a0496781aa740c79e61833d7d83a/internal/wasm/jit/jit_impl_amd64.go#L3536
arm64: https://github.com/tetratelabs/wazero/blob/266320e257e6a0496781aa740c79e61833d7d83a/internal/wasm/jit/jit_impl_arm64.go#L3071
Therefore, there's plenty of rooms for improvements wrt performance as we can see in, for example, musl libs' assembly:
memory.copy, table.copy, memory.init and table.init
- arm64: https://git.musl-libc.org/cgit/musl/tree/src/string/aarch64/memcpy.S?id=v1.2.1
- amd64: https://git.musl-libc.org/cgit/musl/tree/src/string/x86_64/memcpy.s?id=v1.2.1
memory.fill
- arm64: https://git.musl-libc.org/cgit/musl/tree/src/string/aarch64/memset.S?id=v1.2.1
- amd64: https://git.musl-libc.org/cgit/musl/tree/src/string/x86_64/memset.s?id=v1.2.1
Hi @mathetake! One more valuable source must be GOlangs memmove implementation: https://go.dev/src/runtime/memmove_amd64.s It has some comments on why particular decisions where made. I've made some x86 experiments today on my own to find a fast and easy to implement memcpy function. You can check the sources out at https://github.com/dranikpg/memcpy-perf-research/.
Wazero currently uses a simple copy loop (orange "loop" on the plot). While it is really hard to be more performant on small sizes, advanced implementations are over several times faster on mid and large sized arrays. Opt - is a combination of "loop 8byte" and "movs 8byte" with some additional cases for small values.
I'd personally choose "loop 8byte", because there won't be any hassle with the currently not present REP, MOVSX instructions and special register cases. Movs of all kinds are already implemented in wazeros assembler. I'm no expert on ARM, but I'll guess an 8byte loop will perform similarly well. What do you think?
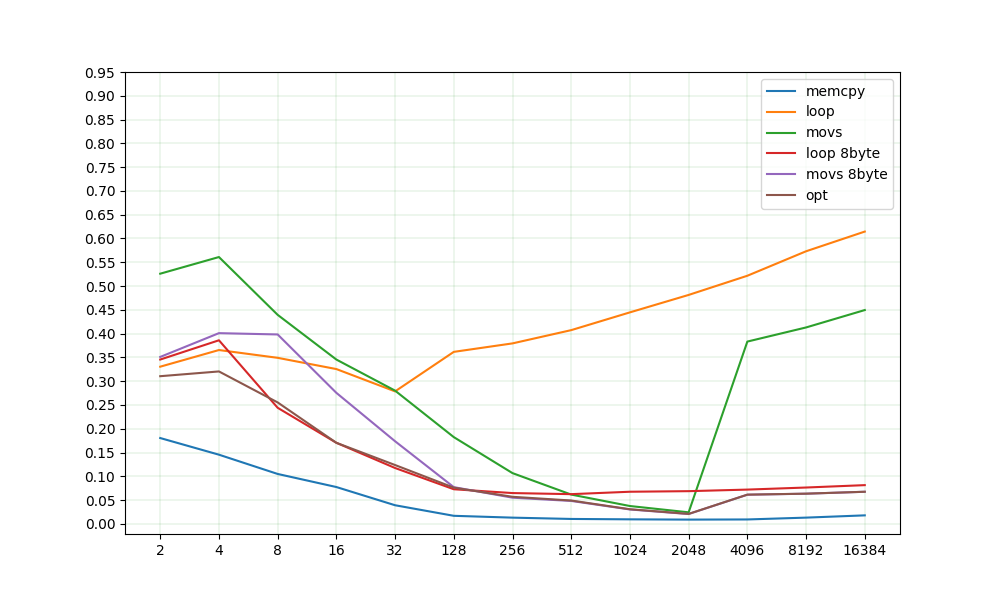
X axis - size in bytes Y axis - time per element, scaled to be in 0-1 range. Values between different sizes are not ment to be compared. See repo for more details
@dranikpg thank you for taking your time to do some research on it.
I'd personally choose "loop 8byte", because there won't be any hassle with the currently not present REP, MOVSX instructions and special register cases.
So it's possible to implement the fastest memcpy if we have REP and MOVSX? Adding new instructions is fairly easy and straightforward, plus we already have MOVSX kinds here as MOV__SX where __ is like BL, BQ etc.
Having said that, I see that the Go's impl is pretty complex and hard to maintain, so I agree with you that let's implement 8-byte each copy loop, and do the same for arm64. That should come with the great balance between maintainability and performance considering that we don't have many engs on this project and performance is not the top priority for now.
So do you want to contribute the change to wazero by yourself? If so let's do step by step like the first PR is about amd64's memory.copy and then the next one would be on memory.fill, etc. After you finished amd64, then let's do the same for arm64.
So it's possible to implement the fastest memcpy if we have REP and MOVSX?
Great. It's fastest for lengths over 128 bytes. I cannot estimate, what lengths will be used more often then others.
So do you want to contribute the change to wazero by yourself?
I'm keen to 😀 I'll open the first one in the coming days
cool, thanks! If the change will come with the refactoring, feel free to submit the separate PR before the actual optimization! See you later!
I've done some research on memset.
The bad news is, its harder than I thought to get it right 🥲. The good news is, there are really huuuge performance improvements possible. I've updated my repo with the assembly sources.
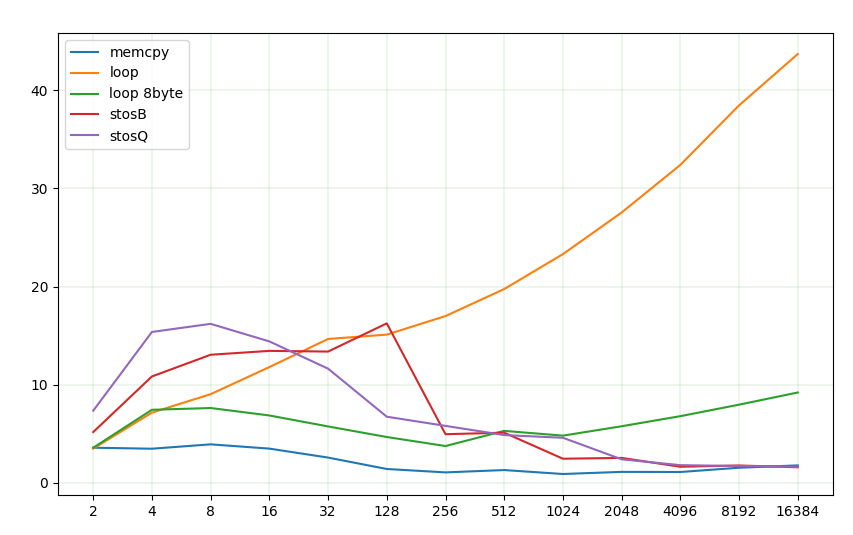
Again, results for different sizes shouldn't be compared. I've scaled them to fit one plot.
The REP family is a good fit for sizes 256+. STOSQ(8 bytes) and STOSB(1 byte) have roughly the same performance, because on almost all modern CPUs they correspond to a special microcode. But they're significantly slower for small sizes up to 128.
golangs runtime favours vector instructions over the REP family, however they're equally fast for large arrays. Besides, they're much harder to implement.
The 8-byte loop performs well for small sizes.
So, the options might be:
- loop up to 128, then stosB (easiest)
- loop up to %8, then stosQ (easy, musl libc does it roughly that way)
- loop up to 16, then stosQ (easy)
- loop up to %8, then 8-byte loop up to 128, then stosb (hardest, but fastest)
@mathetake Let me know, what you think 😄
One more question I have is that the current table fill implementation doesn't work as expected with non-zero fill values (but I guess nobody would fill a table with non-zero values?).
Particularly, https://github.com/tetratelabs/wazero/blob/c5daf5a218439489fa2ffe5a0f719b720036adc4/internal/engine/compiler/impl_amd64.go#L3843-L3844
it doesn't replicate the fill byte onto the full register, so 7/8 of it are just empty.