jest-dom
 jest-dom copied to clipboard
jest-dom copied to clipboard
toHaveTextContent fails when NumberFormatter is used in node 14
@testing-library/jest-domversion: 5.13.0nodeversion: 14.15.0npm(oryarn) version:yarn
Relevant code or config:
Given this helper method.
const formatter = Intl.NumberFormat('de-DE', {
style: 'currency',
currency: 'EUR',
})
export const formatMoneyValue = (value: number): string => {
return formatter.format(value)
}
And this component code.
<template>
<div data-testid="element">{{ money }}</div>
</template>
<script>
import { formatMoneyValue } from './formatMoneyValue'
export default {
computed: {
money() {
formatMoneyValue(42)
}
}
}
</script>
And this test code
import { render, screen } from '@testing-library/vue'
import { formatMoneyValue } from './formatMoneyValue'
import TestComponent from './TestComponent'
it('should render money values correctly.', () => {
render(TestComponent)
expect(screen.getByTestId('element')).toHaveTextContent(
formatMoneyValue(42)
)
})
What happened:
I expected this test to succeed but it actually failed.
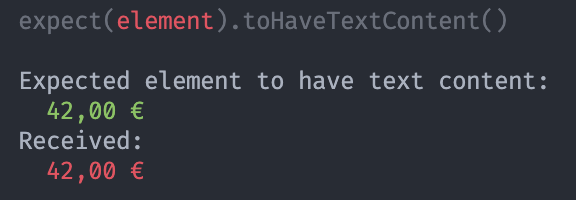
Problem description:
It seems like the NumberFormatter includes non-standard whitespace in the string it produces. It doesn't matter whether I set the normalizeWhitespace option to true or false. In the end, I "fixed" it locally by changing the formatMoneyValue method.
export const formatMoneyValue = (value: number): string => {
return formatter.format(value).replace(/\s+/, ' ')
}
Suggested solution:
I'm not sure how to handle this. It would be great if it "could just work" or if the error message would be a bit more explicit about the whitespace issue. As it is right now this left me staring at my screen in disbelief.
As I said this also only happens on node@14. With node@12 the test passes just fine.
I looked into this, and I'm as baffled as you are.
I added this test inside the test file for to-have-text-content.js in this repo:
test.only('with a number formatter', () => {
const formatter = new Intl.NumberFormat('de-DE', {
style: 'currency',
currency: 'EUR',
})
const {queryByTestId} = render(`
<div data-testid="money">${formatter.format(42)}</div>
`)
console.log({
strNormalized: formatter.format(42).replace(/\s+/, ' '),
strNormalizedLength: formatter.format(42).replace(/\s+/, ' ').length,
str: formatter.format(42),
txt: queryByTestId('money').textContent,
strLength: formatter.format(42).length,
txtLength: queryByTestId('money').textContent.length,
eq: formatter.format(42) === queryByTestId('money').textContent,
})
expect(queryByTestId('money')).toHaveTextContent('42,00 €')
})
The console.log statement yields this output:
{
"strNormalized": "42,00 €",
"strNormalizedLength": 7,
"str": "42,00 €",
"txt": "42,00 €",
"strLength": 7,
"txtLength": 7,
"eq": true
}
What I'm most baffled with is the second property in that object. How is that the length of the string is the same after having applied the call to .replace(/\s+/, ' ')? Apparently, there are some characters in that string that do not contribute to the length but they do contribute to making it be different.
I also found out that this problem would go away if we changed this line in our code:
https://github.com/testing-library/jest-dom/blob/317e31910c8ed5212cae7c743a96b2676549cfd4/src/to-have-text-content.js#L12
In the following way:
- : node.textContent.replace(/\u00a0/g, ' ') // Replace with normal spaces
+ : node.textContent
However, that breaks a key aspect of the functionality expressed in this test:
https://github.com/testing-library/jest-dom/blob/317e31910c8ed5212cae7c743a96b2676549cfd4/src/tests/to-have-text-content.js#L55-L61
So doing so would be an undesired and breaking change.
I'm out of ideas as to how to accommodate both needs. So I'm afraid that, since you have that workaround, I recommend we do nothing and you keep using the workaround. Unless someone finds a way to satisfy both needs.
Chiming in here to say that this also happens with Number.prototype.toLocaleString:
Node v13+ with bundled full-icu, right result:
> (42).toLocaleString('fi-FI', { style: 'currency', currency: 'EUR' })
'42,00 €'
Node v12 without full-icu, wrong result:
> (42).toLocaleString('fi-FI', { style: 'currency', currency: 'EUR' })
'€42.00'
(Background article on ICU changes: https://mtsknn.fi/blog/using-non-default-locales-with-tolocalestring-in-nodejs/.)
I was surprised to find out that even explicitly turning normalizeWhitespace off... well, doesn't, completely. I'm not sure why got this special treatment, surely the authors who rely on them being preserved could have explicitly used the nonbreaking space characters rather than standard spaces in their tests? Unfortunately undoing this transformation now would indeed be a breaking change.
In my case I think is the right separator to use between monetary values and the currency symbol, so my workaround was to add an extra .replace(/\u00a0/g, ' ') to the value being compared against in the test itself and linking back to this issue to explain why.
I had a similar issue except with DateTimeFormat. I had a formatter that looks like this:
export const formatDateTime = (date) => {
const formatter = new Intl.DateTimeFormat('en-US', {
dateStyle: 'short',
timeStyle: 'short',
});
return formatter.format(date);
};
I too ran into issues with toHaveTextContent not matching because of subtle whitespace differences.
If you run into that scenario you can do what I did which is to leverage the normalizeWhitespace: false option on toHaveTextContent like so:
expect(element).toHaveTextContent(expectedValue, {
normalizeWhitespace: false
});
This workaround resolved the issue for me.
Versions in case it helps:
@testing-library/jest-dom: 6.4.2
@testing-library/react: 14.2.1
jest: 29.6.2
jest-dom: 6.4.2
jest-environment-jsdom: 29.6.2
Is this issue relevant, considering how outdated Node v14 is? Though we still seem to support it, but I'd rather fix this by dropping support for Node v14. Thoughts?