Error when running shared HMC on distributed GPUs with big dataset
I'm currently running a distributed HMC on 4 Tesla V100 cards, and my codes are like:
import functools
import collections
import contextlib
from jax.config import config
config.update("jax_enable_x64", True)
import jax
import jax.numpy as jnp
from jax import lax
from jax import random
import tensorflow as tf
from tensorflow_probability.substrates import jax as tfp
tfd = tfp.distributions
tfb = tfp.bijectors
tfm = tfp.mcmc
tfed = tfp.experimental.distribute
tfde = tfp.experimental.distributions
tfem = tfp.experimental.mcmc
Root = tfed.JointDistributionCoroutine.Root
def shard_value(x):
x = x.reshape((jax.device_count(), -1, *x.shape[1:]))
return jax.pmap(lambda x: x)(x) # pmap will physically place values on devices
shard = functools.partial(jax.tree_map, shard_value)
Y=jnp.ones((256*256,258),dtype=jnp.float64)
dtype = jnp.float64
@functools.partial(jax.pmap, axis_name='data', in_axes=(None, None,0), out_axes=(None,None))
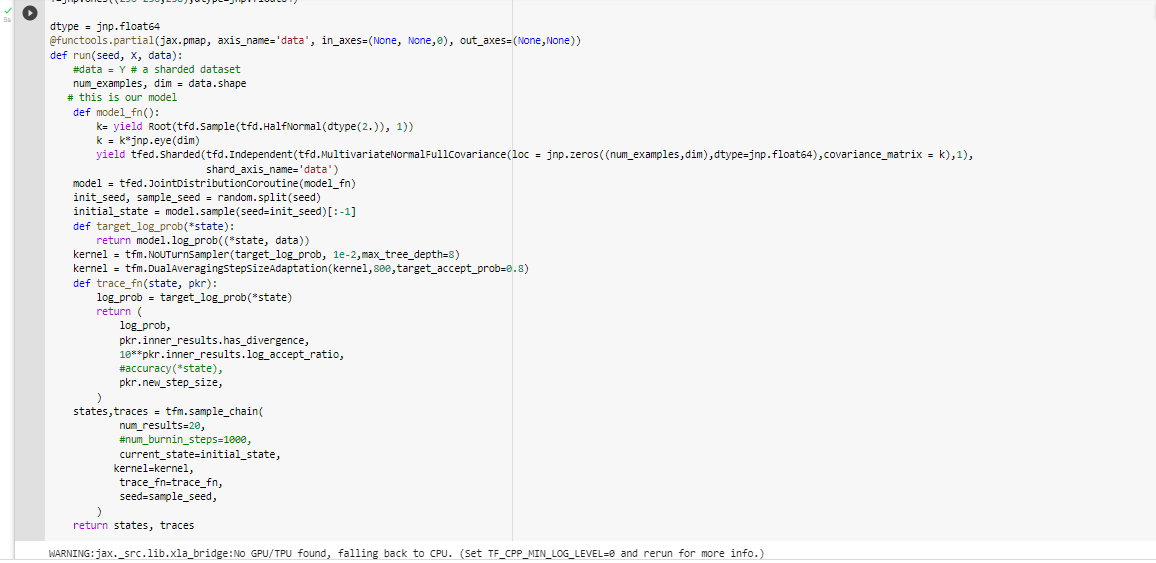
def run(seed, X, data):
#data = Y # a sharded dataset
num_examples, dim = data.shape
# this is our model
def model_fn():
k= yield Root(tfd.Sample(tfd.HalfNormal(dtype(2.)), 1))
k = k*jnp.eye(dim)
yield tfed.Sharded(tfd.Independent(tfd.MultivariateNormalFullCovariance(loc = jnp.zeros((num_examples,dim),dtype=jnp.float64),covariance_matrix = k),1),
shard_axis_name='data')
model = tfed.JointDistributionCoroutine(model_fn)
init_seed, sample_seed = random.split(seed)
initial_state = model.sample(seed=init_seed)[:-1]
def target_log_prob(*state):
return model.log_prob((*state, data))
kernel = tfm.NoUTurnSampler(target_log_prob, 1e-2,max_tree_depth=8)
kernel = tfm.DualAveragingStepSizeAdaptation(kernel,800,target_accept_prob=0.8)
def trace_fn(state, pkr):
log_prob = target_log_prob(*state)
return (
log_prob,
pkr.inner_results.has_divergence,
10**pkr.inner_results.log_accept_ratio,
#accuracy(*state),
pkr.new_step_size,
)
states,traces = tfm.sample_chain(
num_results=20,
#num_burnin_steps=1000,
current_state=initial_state,
kernel=kernel,
trace_fn=trace_fn,
seed=sample_seed,
)
return states, traces
The code works fine when the second axis of Y is shorter than 256, however, when Y.shape[1]>256, it reports:
2022-12-23 12:12:25.279516: E external/org_tensorflow/tensorflow/compiler/xla/stream_executor/cuda/cuda_driver.cc:752] failed to free device memory at 0x14c238201200; result: CUDA_ERROR_ILLEGAL_ADDRESS: an illegal memory access was encountered 2022-12-23 12:12:25.279535: E external/org_tensorflow/tensorflow/compiler/xla/stream_executor/cuda/cuda_driver.cc:752] failed to free device memory at 0x14c238200c00; result: CUDA_ERROR_ILLEGAL_ADDRESS: an illegal memory access was encountered 2022-12-23 12:12:25.279539: E external/org_tensorflow/tensorflow/compiler/xla/stream_executor/cuda/cuda_driver.cc:752] failed to free device memory at 0x14c238201400; result: CUDA_ERROR_ILLEGAL_ADDRESS: an illegal memory access was encountered 2022-12-23 12:12:25.279541: E external/org_tensorflow/tensorflow/compiler/xla/stream_executor/cuda/cuda_driver.cc:752] failed to free device memory at 0x14c238200e00; result: CUDA_ERROR_ILLEGAL_ADDRESS: an illegal memory access was encountered 2022-12-23 12:12:25.279544: E external/org_tensorflow/tensorflow/compiler/xla/stream_executor/cuda/cuda_driver.cc:752] failed to free device memory at 0x14c238201000; result: CUDA_ERROR_ILLEGAL_ADDRESS: an illegal memory access was encountered 2022-12-23 12:12:25.279551: E external/org_tensorflow/tensorflow/compiler/xla/stream_executor/cuda/cuda_driver.cc:752] failed to free device memory at 0x14c2862a3c00; result: CUDA_ERROR_ILLEGAL_ADDRESS: an illegal memory access was encountered 2022-12-23 12:12:25.279562: E external/org_tensorflow/tensorflow/compiler/xla/stream_executor/cuda/cuda_driver.cc:752] failed to free device memory at 0x14c2862a3600; result: CUDA_ERROR_ILLEGAL_ADDRESS: an illegal memory access was encountered 2022-12-23 12:12:25.279565: E external/org_tensorflow/tensorflow/compiler/xla/pjrt/pjrt_stream_executor_client.cc:2153] Execution of replica 1 failed: INTERNAL: Unable to launch triangular solve 2022-12-23 12:12:25.279572: E external/org_tensorflow/tensorflow/compiler/xla/stream_executor/cuda/cuda_driver.cc:752] failed to free device memory at 0x14c2862a3e00; result: CUDA_ERROR_ILLEGAL_ADDRESS: an illegal memory access was encountered 2022-12-23 12:12:25.279576: E external/org_tensorflow/tensorflow/compiler/xla/stream_executor/cuda/cuda_driver.cc:752] failed to free device memory at 0x14c2862a3800; result: CUDA_ERROR_ILLEGAL_ADDRESS: an illegal memory access was encountered 2022-12-23 12:12:25.279599: E external/org_tensorflow/tensorflow/compiler/xla/stream_executor/cuda/cuda_driver.cc:752] failed to free device memory at 0x14c2862a3a00; result: CUDA_ERROR_ILLEGAL_ADDRESS: an illegal memory access was encountered 2022-12-23 12:12:25.279614: E external/org_tensorflow/tensorflow/compiler/xla/pjrt/pjrt_stream_executor_client.cc:2153] Execution of replica 0 failed: INTERNAL: cublas error 2022-12-23 12:12:25.279668: E external/org_tensorflow/tensorflow/compiler/xla/stream_executor/cuda/cuda_driver.cc:752] failed to free device memory at 0x14c238401200; result: CUDA_ERROR_ILLEGAL_ADDRESS: an illegal memory access was encountered 2022-12-23 12:12:25.279679: E external/org_tensorflow/tensorflow/compiler/xla/stream_executor/cuda/cuda_driver.cc:752] failed to free device memory at 0x14c238400c00; result: CUDA_ERROR_ILLEGAL_ADDRESS: an illegal memory access was encountered 2022-12-23 12:12:25.279682: E external/org_tensorflow/tensorflow/compiler/xla/stream_executor/cuda/cuda_driver.cc:752] failed to free device memory at 0x14c238401400; result: CUDA_ERROR_ILLEGAL_ADDRESS: an illegal memory access was encountered 2022-12-23 12:12:25.279685: E external/org_tensorflow/tensorflow/compiler/xla/stream_executor/cuda/cuda_driver.cc:752] failed to free device memory at 0x14c238400e00; result: CUDA_ERROR_ILLEGAL_ADDRESS: an illegal memory access was encountered 2022-12-23 12:12:25.279687: E external/org_tensorflow/tensorflow/compiler/xla/stream_executor/cuda/cuda_driver.cc:752] failed to free device memory at 0x14c238401000; result: CUDA_ERROR_ILLEGAL_ADDRESS: an illegal memory access was encountered 2022-12-23 12:12:25.279697: E external/org_tensorflow/tensorflow/compiler/xla/pjrt/pjrt_stream_executor_client.cc:2153] Execution of replica 2 failed: INTERNAL: cublas error 2022-12-23 12:12:25.280175: E external/org_tensorflow/tensorflow/compiler/xla/stream_executor/cuda/cuda_blas.cc:219] failed to create cublas handle: cublas error 2022-12-23 12:12:25.280206: W external/org_tensorflow/tensorflow/compiler/xla/stream_executor/stream.cc:1088] attempting to perform BLAS operation using StreamExecutor without BLAS support 2022-12-23 12:12:25.280218: E external/org_tensorflow/tensorflow/compiler/xla/stream_executor/cuda/cuda_driver.cc:752] failed to free device memory at 0x14c238601200; result: CUDA_ERROR_ILLEGAL_ADDRESS: an illegal memory access was encountered 2022-12-23 12:12:25.280221: E external/org_tensorflow/tensorflow/compiler/xla/stream_executor/cuda/cuda_driver.cc:752] failed to free device memory at 0x14c238600c00; result: CUDA_ERROR_ILLEGAL_ADDRESS: an illegal memory access was encountered 2022-12-23 12:12:25.280224: E external/org_tensorflow/tensorflow/compiler/xla/stream_executor/cuda/cuda_driver.cc:752] failed to free device memory at 0x14c238601400; result: CUDA_ERROR_ILLEGAL_ADDRESS: an illegal memory access was encountered 2022-12-23 12:12:25.280227: E external/org_tensorflow/tensorflow/compiler/xla/stream_executor/cuda/cuda_driver.cc:752] failed to free device memory at 0x14c238600e00; result: CUDA_ERROR_ILLEGAL_ADDRESS: an illegal memory access was encountered 2022-12-23 12:12:25.280230: E external/org_tensorflow/tensorflow/compiler/xla/stream_executor/cuda/cuda_driver.cc:752] failed to free device memory at 0x14c238601000; result: CUDA_ERROR_ILLEGAL_ADDRESS: an illegal memory access was encountered 2022-12-23 12:12:25.280241: E external/org_tensorflow/tensorflow/compiler/xla/pjrt/pjrt_stream_executor_client.cc:2153] Execution of replica 3 failed: INTERNAL: Unable to launch triangular solve
I checked that it probably is not the OOM problem, because when Y.shape[0]=256, it only took half of the GPU memory.
My environment is
jax=0.3.23,CUDA=11.8,jaxlib=0.3.22+cuda11.cudnn82,tensorflow_probability=0.19,tensorflow = 2.11
Does anyone have the same problem as me?
hey dkn16 this issue is still open? I tried to run and it works fine for me.
Thank you for your response! The code works fine with CPU, thus I suppose it is correct. However, when we converted to GPU, it started to go wrong. We're more interested in GPU because this is much faster.
Strangely, in jax=0.3.23, the maximum allowed second axis size of Y is 256, when Y.shape==(65536,256), things are all right, and it only took half of the VRAM, thus I suppose it is not because of OOM. But (65536,257) will raise this error.
hey dkn16 this issue is still open? I tried to run and it works fine for me.
Thank you for your response! The code works fine with CPU, thus I suppose it is correct. However, when we converted to GPU, it started to go wrong. We're more interested in GPU because this is much faster.
Strangely, in jax=0.3.23, the maximum allowed second axis size of
Yis 256, when Y.shape==(65536,256), things are all right, and it only took half of the VRAM, thus I suppose it is not because of OOM. But (65536,257) will raise this error.
Thanks for inform the error dkn16. Can you please share a snapsort of the error in the comment.
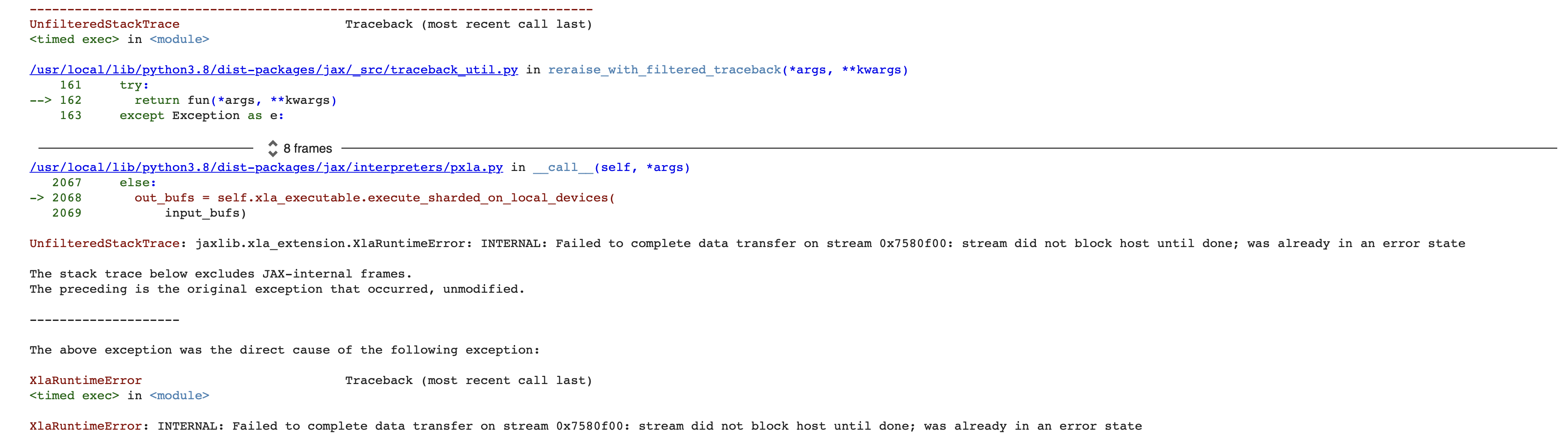
Here is the snapshot @ADITYADAS1999 . Besides, I created a colab notebook where we can reproduce the error. The link is: https://colab.research.google.com/drive/1H7uhwCAAkenBT5bRut2t9DbPp9XcwnY8?usp=sharing
You can see that when the Y.shape==(4096,256), the code is OK and VRAM usage is about 50%. However, (4096,258) would fail.
Here is the snapshot @ADITYADAS1999 . Besides, I created a colab notebook where we can reproduce the error. The link is: https://colab.research.google.com/drive/1H7uhwCAAkenBT5bRut2t9DbPp9XcwnY8?usp=sharing
You can see that when the Y.shape==(4096,256), the code is OK and VRAM usage is about 50%. However, (4096,258) would fail.
thanks for sharing dkn16 😃