envd
 envd copied to clipboard
envd copied to clipboard
feat(lang): Support serving
Description
envd is designed to be the development environment for training. But I am thinking if we should support serving.
There are a few things we need to confirm:
- The pain points of environment management in serving
- The current experience
- How to integrate with serving servers
- How to integrate with model monitoring
The serving environment has the same problem: it's hard for the data scientists to write a Dockerfile with the best practice and integrate it with the CI/CD pipeline.
Usually, it's offered by the AI infra team, but they may not be able to review all the changes.
Requirements:
- non-root
- CUDA runtime & version (may need to run
ldconfig) - required Python packages (installed from pip or conda)
- environments (optional, like
OMP_NUM_THREADS,MKL_NUM_THREADS,CUDA_VISIBLE_DEVICES, etc.) - where to get the model data
- entrypoint (
tinior some other tools)
I checked the current interface and implementation. There are several things we need to consider.
serving requirements
- minimal base image: cuda-runtime like
nvidia/cuda:11.6.2-runtime-ubuntu20.04 - conda environment (optional)
- minimal Python: created from conda
base image: exclude from dev env
- base apt packages like
vim,git,mercurial,wget,curl,sudo,zsh starshiphorustenvd-sshd
python image: need to refactor the logic
jupytervscodestarshippromptgitconfig- entrypoint
diff with custom
will be a breaking change but may not really affect the current users
- non-root user and home dir
- python
- PATH
implementation
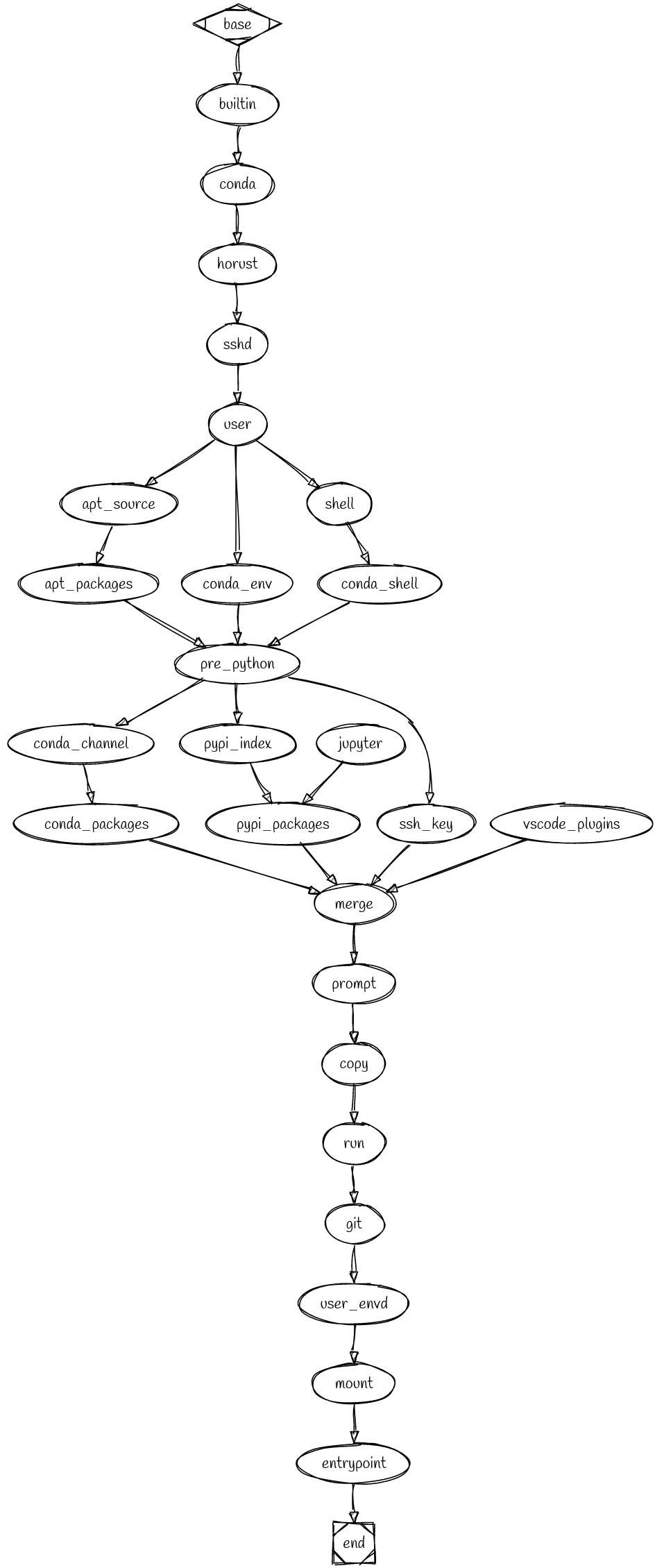
- Need to refactor the
Graph.Compile()related functions. Compiling dev/serving/custom env should be distinct functions, so no moreif g.Image != nileverywhere - We maintain only one base image remote cache for each default configuration.
- dev CPU
- dev GPU
- serving CPU
- serving GPU
interface
- As we discussed in https://github.com/tensorchord/envd/issues/1179,
osandimagewill be unified toimagewith the standard format liketensorchord/python:latest. We also need a new parameter inbaseto indicate that this environment is for development or online serving. - We may need a new parameter to indicate the env requires conda (default=True), related to https://github.com/tensorchord/envd/issues/672
- Serving env looks similar to custom env, but not 100%. For example, we will provide the Python env but custom env should maintain its own
others
- we should provide more functions in envdlib like
pytorch(),tensorflow_gpu(),tensorflow_cpu() - these changes may also affect Julia and R lang environments
Another important point about serving is log. I think we should consider it .
Should we introduce a new CLI to support the serve?
Maybe envd deploy or something else.
Another important point about serving is
log. I think we should consider it .
Which kind of logger/collectors are you using? I used to try the GCP StackDriver, users only need to log stdout/stderr in JSON format.
Should we introduce a new CLI to support the serve?
Maybe envd deploy or something else.
SGTM.
Maybe we could design a interface such as:
runtime.log(driver="logstash", ...)
I think in serving scenario, logs are handled by k8s. Such as a deamonset, or a sidecar container to send the logs to remote API endpoint. Is there anything special that envd needs take care of? I think the only thing we need to support here is the log file path?
I think in serving scenario, logs are handled by k8s. Such as a deamonset, or a sidecar container to send the logs to remote API endpoint. Is there anything special that envd needs take care of? I think the only thing we need to support here is the log file path?
You are right.
I'm trying to make it compatible with the current interface.
A draft for the envd file:
envdlib = include("https://github.com/tensorchord/envdlib")
requirements = [
"torch --extra-index-url https://download.pytorch.org/whl/cpu",
"torchvision",
"numpy",
"mosec",
"msgpack",
"Pillow",
]
dev = requirements + ["httpx"]
def build():
base(language="python3") # will use the default dev image
install.python_packages(name=dev)
envdlib.tensorboard(host_port=8888)
runtime.expose(envd_port=8000, host_port=8000, service="service")
def serving():
base(language="python3", dev=False, conda=False) # will use the default CPU serving image
install.python_packages(name=requirements)
def custom():
base(image="rust:bullseye", dev=True, conda=True)
install.python_packages(name=dev)
install.system_packages(name=["ripgrep"])
This uses the resnet50 example from mosec:
- service: https://github.com/mosecorg/mosec/blob/main/examples/resnet50_server_msgpack.py
- client: https://github.com/mosecorg/mosec/blob/main/examples/resnet50_client_msgpack.py
Should we make dev and conda in base? Or should we split base to several funcs?
Should we make dev and conda in base? Or should we split base to several funcs?
I think the dev is highly related to the base image. conda could be another function.
dev=True, conda=True looks a bit weird. Can we merge them?
Possible proposal:
builtin_packages=dev()anddevis an internal function which returns a list of packages such as['sshd', 'conda']
builtin_packages=dev()anddevis an internal function which returns a list of packages such as['sshd', 'conda']
What should users do with the returned packages? Or should we provide the all-in-one dev_environment()?
I think we only embed the sshd and starship for users. Are there any other packages?
I think we only embed the sshd and starship for users. Are there any other packages?
Check my comment above: https://github.com/tensorchord/envd/issues/157#issuecomment-1318377491
builtin_packages=dev()anddevis an internal function which returns a list of packages such as['sshd', 'conda']What should users do with the returned packages? Or should we provide the all-in-one
dev_environment()?
It's just the default options. User can do anything they want. Common scenario I think will be custom base image + nothing extra from envd
builtin_packages=dev()anddevis an internal function which returns a list of packages such as['sshd', 'conda']What should users do with the returned packages? Or should we provide the all-in-one
dev_environment()?It's just the default options. User can do anything they want. Common scenario I think will be custom base image + nothing extra from envd
The problem is that this may return a lot of packages. That will introduce lots of boilerplate code. I think it should be easy to set up the common basic environment for dev and serving. Hopefully in one or two lines. Then they can add whatever they need.
What do you mean by boilerplate code? And what would the common basic environment look like?
What do you mean by boilerplate code? And what would the
common basic environmentlook like?
Do you mean users should pop items from builtin_packages=dev() to disable them? That's hard to implement for the current design. Because we don't use any returned values except for include. Otherwise, users need to specify which one they want to use, that's what I mean by boilerplate code.
User can directly do buildin_packages=[] if nothing needed, or buildin_packages=['conda'] if he needs conda. However the possible item here will be limited
User can directly do
buildin_packages=[]if nothing needed, orbuildin_packages=['conda']if he needs conda. However the possible item here will be limited
But this is weird for starlark. Others work like a function, but this is a global variable if I understand correctly.
Actually I mean base(buildin_packages=[]) instead of base(dev=True, conda=True) 😲
Actually I mean
base(buildin_packages=[])instead ofbase(dev=True, conda=True)astonished
Oh, I see. But it's not just some packages. For example, you cannot use runtime.daemon for serving because usually, you won't install horust for serving. This means, in this flexible way, there will be tons of if-else in the implementation everywhere. Because we're not able to know how many features users enabled for this build unless we loop against all the possibilities.
Idealy, we don't need to distinguish among dev, serving, custom envs.
We should provide the atomic functions like:
dev_tools()install.conda()install.python()- etc.
Users can choose what they like. We only maintain the default dev env remote cache. (It's only useful for the 1st build)
I'll be working the implementation.
TODO:
- research conda
- research UID
BTW, how to handle the envdlib in the new design? Will these be in a new subgraph, or use the default graph directly?
BTW, how to handle the envdlib in the new design? Will these be in a new subgraph, or use the default graph directly?
Still the default graph, I think. It should be compatible.
BTW, how to handle the envdlib in the new design? Will these be in a new subgraph, or use the default graph directly?
Still the default graph, I think. It should be compatible.
I have kind of concern about complexity in default graph. But we could refactor it after all ir features seems stable.