entrypoints
 entrypoints copied to clipboard
entrypoints copied to clipboard
Caching entry point data
This issue is to discuss how best to cache entry points, and how to ensure that it's performant and accurate.
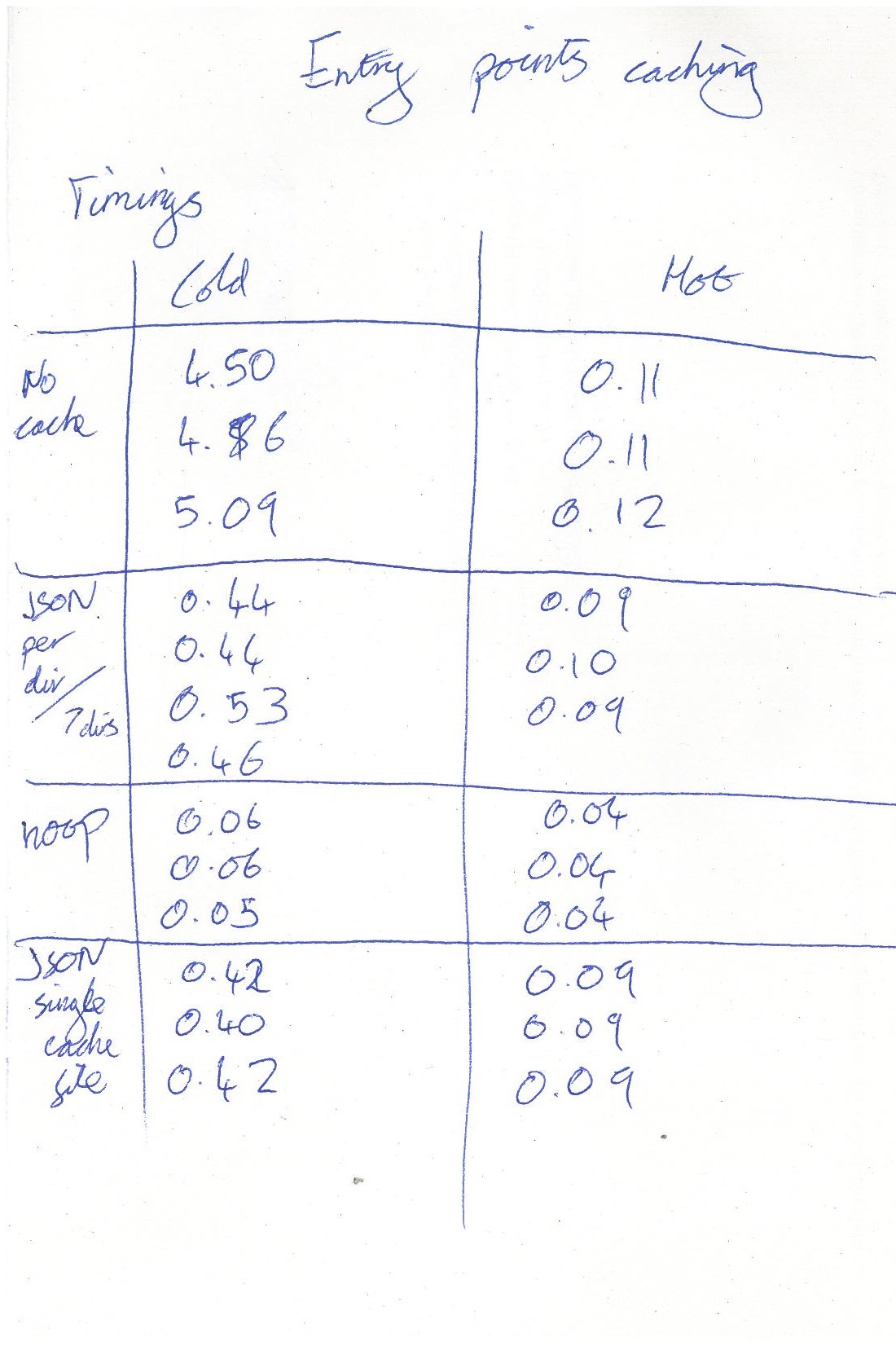
I have been experimenting with caching on the cache-experimentation branch. I tested one implementation with a cache file stored in each sys.path directory (make_cache.py and read_cache.py) and one with a single cache file with directories as keys (*_single_cache.py).
Cold start performance - where the files it reads are not cached in memory by the OS - tested using a command from here, on a system with a spinning hard drive (not an SSD). This is a worst case for this kind of operation, but it's realistic.
- Loading entrypoints with no cache files: 4.5 seconds
- Loading with a cache per directory: 0.44 seconds
- Loading with a single cache: 0.40 seconds
- Running Python with a no-op file: 0.05 seconds
However, my system has a short sys.path, with only 7 directories on it. If you have more a longer sys.path, e.g. because you're using 'egg' installations, the difference between per-directory caches and a single cache will be bigger.
Warm start performance - with the files in memory - didn't change much, from about 110ms with no cache to about 85ms with a single cache.
Full timing results (sorry, it's handwritten):
Single vs in-directory
Keeping a cache file in each sys.path directory is easier to work with conceptually - if the directory has different paths because it's accessed over NFS or bind-mounted into docker containers, the same cache works for all of them. If you delete the directory, you delete its cache. And in my case, the speed penalty over a single cache is minimal.
The performance of a single cache may be more important if you have a lot of entries on sys.path (eggs). It also allows you to create a cache for directories that you cannot write to, such as system directories, and for entry points from zip files (eggs again) without needing a special case.
Format options
- SQLite seems like a good solution, but it has a major achilles heel: NFS. Databases on NFS mounts get corrupted often enough that I don't want to rely on SQLite anywhere that the file might be stored in NFS.
- Something like cdb would work for this: create a new cache and replace the old one atomically, never updating an existing file. But we'd need to either parse the format in Python, or ship an extension module to parse it efficiently.
- I've gone for JSON, because Python already comes with a JSON parser implemented in C, so it should be cheap to read. That it's a familiar, human-readable format is a bonus.
To test performance on a Linux system, clone this repository and check out the cache-experimentation branch. Then:
# Make the caches
python3 make_single_cache.py
sudo python3 make_cache.py # Needs to write caches in system directories
# Loading with no caches
sync ; echo 3 | sudo tee /proc/sys/vm/drop_caches # Simulate cold start
time python3 entrypoints.py
# Loading with per-directory caches
sync ; echo 3 | sudo tee /proc/sys/vm/drop_caches # Simulate cold start
time python3 read_cache.py
# Loading with single cache
sync ; echo 3 | sudo tee /proc/sys/vm/drop_caches # Simulate cold start
time python3 read_single_cache.py
I've just realised that a considerable portion of the ~0.4 seconds running the cache examples is due to imports, rather than actually loading the entry points. In my tests, doing the same imports as read_single_cache.py but not calling anything takes about 0.36 seconds.
So loading the entry points from the cache is quicker than this suggests, and the proportional difference between a per-user cache and a per-directory cache is greater. I should work out how to measure it more accurately from inside Python.
Then again, what I care about as an application programmer is startup time. If finding entry points can be fast to the point that it's dwarfed by import time, I don't need to care about further speedups, no matter how big they are proportionally.
I think permissions management and NFS are going to be a bigger concern than speed when it comes to choosing between the per-directory and single-file cache designs.
With a single-file cache design, it's fairly straightforward to say:
- In an active virtual environment, store the cache in a defined location within the venv
- Outside a venv, if there's a per-user data caching directory defined and writable, use that (so the cache is shared between processes run by that user).
- Otherwise write the cache to a per-process temporary directory.
With per-directory caching, you'd have a harder time dealing with system site-packages directories that are owned by the root user, and an even higher chance of at least some of the caches ending up being stored on network drives.
I guess it depends what model of cache you're thinking about. The single file cache is easy for the application to build without requiring different tools to co-ordinate. But cache invalidation is really hard that way - if I install a plugin systemwide with yum or apt, it can't update the cache for every user who might have used that application. You could do it manually, with a 'check for new plugins' button/command, but that loses the plug-and-play benefit of entry points. Applications can do this kind of caching without any changes to the entry points system: get their entry points once and save the results.
With the per-directory model, cache invalidation still isn't easy, but if you can get all the tools that (un)install packages to run some hooks, applications should mostly be able to rely on the cache, with manual intervention only rarely needed. I'm basing this idea on the XDG mime system: mime types are declared in a collection of separately installable XML files, and installer code runs update-mime-database after changing those files to rebuild a database, which is what applications read.
I don't think files being on NFS is a particular problem unless we use SQLite (and that's why I'm not using it). Loading them will be slower, but so will loading any modules and data files.
I'll try to think about hybrid approaches that could bridge the gap and allow applications to use caching while package managers get on board.
One possible hybrid approach would be to have per-directory markers that optimised cache validity checks. Without that, you'd technically need to check for mtime shifting forward or back on all of the entry_points.txt files that contributed to building the cache to ensure it was fresh (which should still be faster than reading them all, but it's still quite a few extra stat calls on startup).
After all, your baseline here is:
- Read every available entry_points.txt file on startup
- Cache that in memory for use by the current process
- Restart the process to invalidate the cache
A per-user cache replaces that with:
- Check the mtime of every available entry_points.txt file on startup
- Read a per-venv or per-user JSON blob
- If the mtimes all match, just use the blob, otherwise update the cache
Per-directory caching would then be about optimising the cache validity check and the cache update operation, rather than being the solve caching mechanism available.
For reference, I just checked the performance of fetching the mtimes of all entry points files. Best of 3 tries:
- Cold start: 4.5 seconds (about the same as reading them)
- Warm start: 0.08 (vs reading about 0.11)
(Not including loading any cache)
Interesting! Given those numbers, I'm guessing a generic per-user cache wouldn't be all that useful - when outside a venv, you'd just fall back to building the in-memory cache on app startup.
Inside a venv though, I think you'd have a better case for allowing an optional externally managed cache file - then folks could generate it as part of their build process, and apps would just assume that if it was present, it was suitable for use.
Yeah, in the context of deployment tools that build an environment as a ~immutable thing, and any changes in dependencies mean building a new env, creating a single-file cache definitely makes sense.
I've started playing with an implementation that uses the mtime of the site-packages directory to check if the cache is valid. For eggs, it skips that, because the egg filename contains a version number, so a new version should be a new path (and there may be many eggs, so we don't want to stat them all).
The performance of this is - on my system - roughly comparable with the caching approaches I timed earlier - ~0.45 seconds cold start when the cache is present and up to date.
The crucial question, of course, is when it the validity check can go wrong. It could be wrong when:
- You edit an entry points file without un/installing a package. If someone is doing this, I think it's acceptable to expect them to manually regenerate the cache.
- On a FAT filesystem, according to this Microsoft support page, changing the contents of a directory does not change its mtime. From what I can find, directory mtimes work as needed on NTFS and ext* filesystems. I doubt many people are installing Python packages on FAT - it's mostly used for memory sticks and SD cards now. But inevitably some people are, so I need to come up with some workaround - which may just be a way to disable caching for a folder.
- Network filesystems? I'd have to investigate more, but they're generally the bane of trying to do anything clever with files.
fyi, in a project I'm working on they developed https://pypi.org/project/reentry/ which is basically a cache on top of setuptools. They decided to use JSON as a backend. Since I'm trying to switch to something like Poetry or Flint, having to have setuptools around just for the plugin-stuff in the project isn't nice.
I'm interested in improving the scanning speed for entry points to use in python-openstackclient and stevedore. I've put together a patch in #41 as an example of another approach. It seems a little simpler than the versions already in the cache-experimentation branch. In particular, it's possible that I'm assuming too much about changes to the mtime for path entries, and the hash computation should include some more values. I'm curious to know what you think.