Input size of networks
Hello,
I have adapted the code for the SEN12 benchmark dataset where the images have a size of 256 x 256 pixels. I tried to figure out what the inputs and outputs of the different networks are (see sketch). 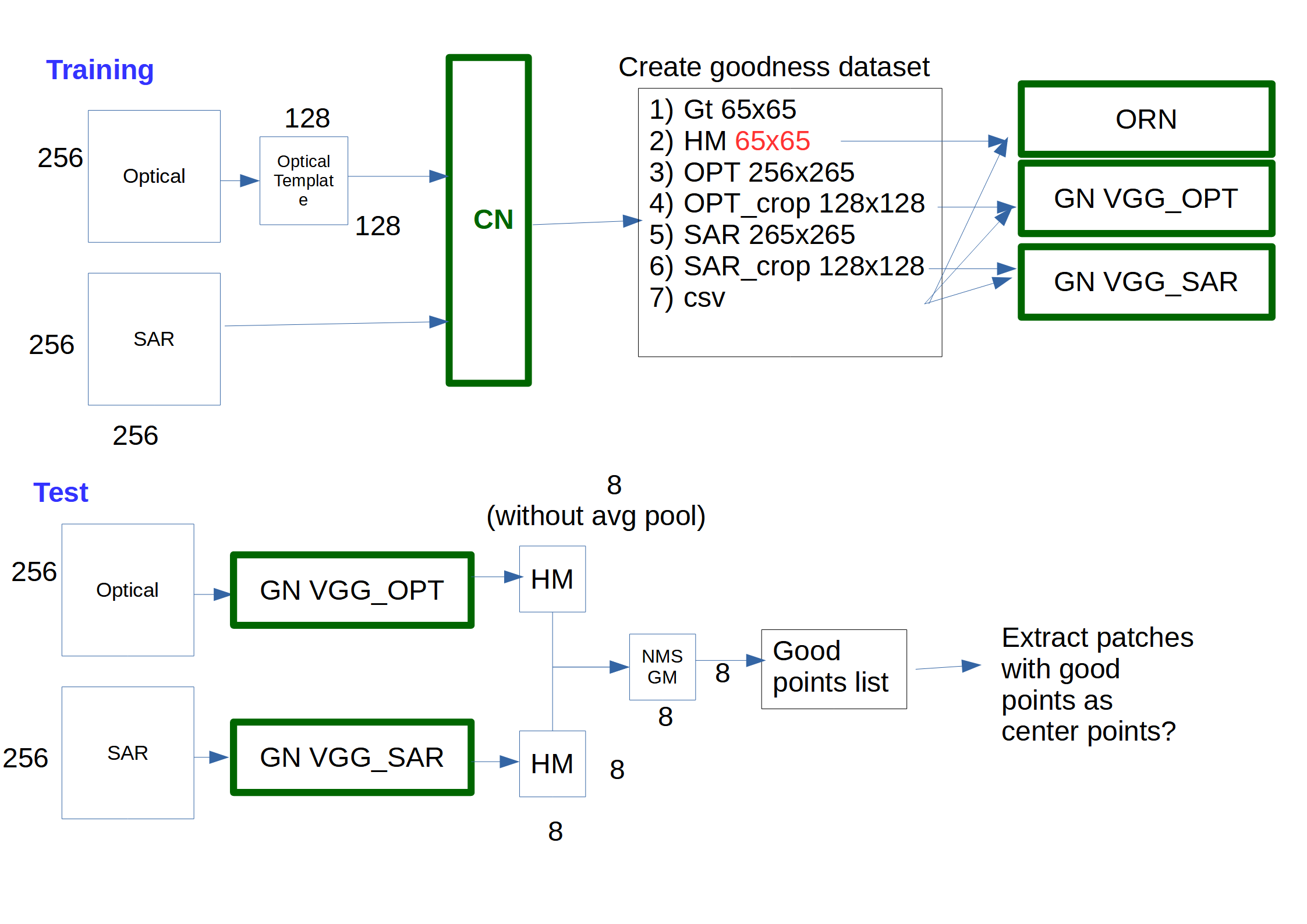 However, I still have some problems:
However, I still have some problems:
- from the correspondence net I get a heatmap size of 65 x 65 pixels, which is different from the 129 pixels in the paper (the heatmap sizes are calculated in line 83-84 in
corr_feature_net.py)-> how can I get model outputs (from FtsA + FtsB) with the same size as the 128 template and 256 search patch such that I get the 129 pixel heatmap or where is the factor 2 upsampling from 65 to 129 performed in the code? (I could also not find the padding to the 256 pixel heatmap). - during inference I can generate a list of "good points" with the goodness net + NMS stage. Should I use these points as new center points for cropping the patches for correspondence net?
- if I do the cropping as in 2. can I also use the SEN12 dataset for this? However, this would mean that I can only make the template and search images very small so that they are within the 256 size images from SEN12. Do you know which dataset I can maybe use instead for the test pipeline, thus I can generate patches from the "good points" of 256 pixels?
-
See Figure 5 in the paper – there is an upsampling operation which needs to be added to the output of the network. This is not required during training (in which case you generate the ground truth at the reduced resolution of 65x65), but it is recommended. Have a look at the
UrbanAtlasDatasetSiameseTripletand the effects of thefull_sizeflag. You can set this tofalsein which case the model will train using the smaller 65x65 output. However, it is recommended to rather upsample the output of the matching network before computing the loss – you can do this by adding the aninterpolationwith a scale factor of129/65- this is what was done in the paper. -
Yes – as the goodness map is down-sampled each point is actually a 32x32 pixel region in the original image. Thus you can compute the center of this patch and use that as the center pixel. The assumption made is that the offset between SAR and optical is never larger than 32pixels.
-
I think there is some confusion here. In 2 are you talking about creating the list of good points/patches which are then used for training? If so, I suggest you read that section of the paper again as we do not actually crop any new patches for training. If you mean on large-scale inference then you need to use a large S1 and S2 scene as input _ the patches in the original dataset were also 256x256 pixels so there is no reason the training process shouldn't work on SEN12
@system123 thank you very much for your answer. I think now I understand the training process. In 2 and 3 I had rather referred to the inference. I will test this with a large-scale scene, thus the down-sampled goodness map is not to small and I can extract 256x256 pixel patches for the inference with the correspondence network. But therefore I have to look again in the code how you implement to pass the predicted points from goodness for the extraction of the correspondence inference.
@leesureel Do you mean the config json file? I think this is not so different from the original config json. You just change the paths and use the dataset class name for the SEN12 dataset as the dataset type (for training and validation). Since the existing code was for SEN12-MS and not SEN12, I changed sen12_dataset and dfc_sen12ms_dataset and created a new csv_s12_dataset.py script.
sorry to bother you, however can you give your contact information or email address? I have some difficulties with this project
@system123 thank you very much for your answer. I think now I understand the training process. In 2 and 3 I had rather referred to the inference. I will test this with a large-scale scene, thus the down-sampled goodness map is not to small and I can extract 256x256 pixel patches for the inference with the correspondence network. But therefore I have to look again in the code how you implement to pass the predicted points from goodness for the extraction of the correspondence inference.
excuse me, can you share how to get the Urban Atlas dataset?