hast-util-to-html
 hast-util-to-html copied to clipboard
hast-util-to-html copied to clipboard
Subset option passed to stringifyEntities is overridden by a local subset.
Commit: Refactors handling of text, so that the character subset can be overridden by ctx.entities.subset
I made a small change that would allow a user to override the default subset of characters to be encoded by the stringifyEntities function. I would like this because the html file I am processing contains some templating syntax that includes ampersands as the actual character &, and I'd like to choose to preserve that. Right now, passing options.entities.subset to rehype-stringify does not prevent encoding of the ampersand.
Initial checklist
- [x] I read the support docs
- [x] I read the contributing guide
- [x] I agree to follow the code of conduct
- [x] I searched issues and couldn’t find anything (or linked relevant results below)
- [x] If applicable, I’ve added docs and tests
Description of changes
I made a small change that would allow a user to override the default subset of characters to be encoded by the stringifyEntities function. I did this by rearranging the order of arguments in the Object.assign call so that ctx.entities.subset is not overridden by the hardcoded subset of {subset: '<','&'}.
It is intentional and document that you can’t provide certain options: https://github.com/syntax-tree/hast-util-to-html#optionsentities. That’s because passing those options breaks HTML. I don’t see the value in letting users create broken output.
I would like this because the html file I am processing contains some templating syntax that includes ampersands as the actual character &, and I'd like to choose to preserve that.
Can you expand on this by providing input, actual output, and expected output?
Sure, here it is.
Input
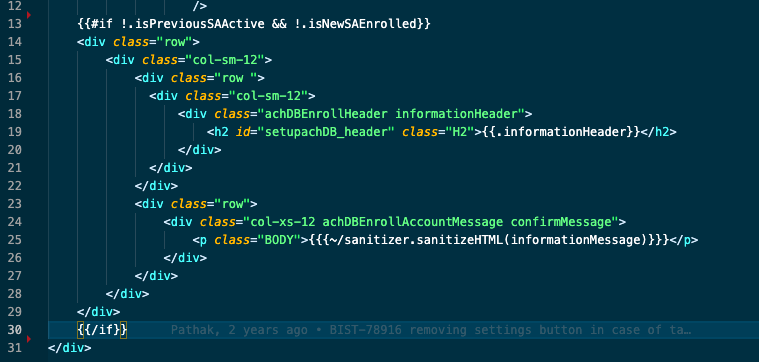
Output
I am performing changes on other parts of this file, but the unintended side effect is here.
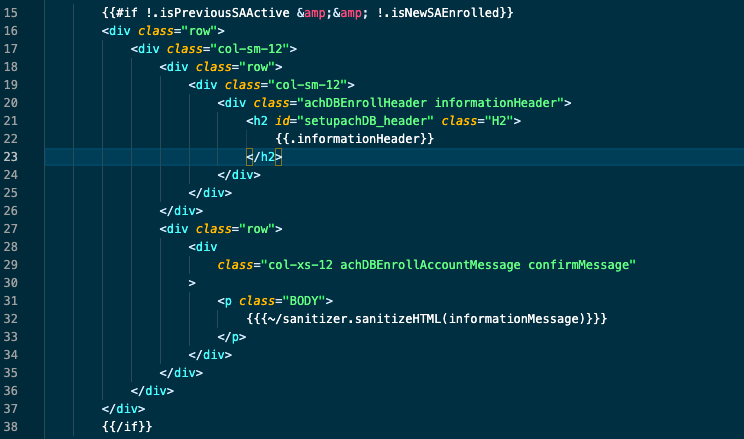
Expected Output I would like the ampersands in my templating syntax to remain untouched. This is not broken output for me, since then it is being consumed by a build tool/templating engine to produce the final html.
It is also encoding any ampersands that are in text nodes of elements, such as a paragraph tag. I may be wrong, but I don't think having an ampersand here is broken output.

I would like the ampersands in my templating syntax to remain untouched.
This is not something that can be done with ASTs. ASTs work by loosing information. They are not CSTs (concrete syntax trees, which do not loose information).
I believe we have talked about ASTs and CSTs in several threads now, perhaps this is an XY problem? Maybe there is a root problem that you’re having that can be solved?
I may be wrong, but I don't believe having an ampersand here is broken output.
The ampersands in these examples are fine, but ampersands combined with other characters can create parse errors, notably “ambiguous ampersands”. See the readme of rehype-parse for more information. Parse errors do not crash HTML parsers, but they should definitely be avoided.
That is why the HTML spec specifies that, when serializing HTML, all ampersands have to be encoded.
This sounds a lot like https://github.com/remarkjs/remark/discussions/922, where you aren't looking to handle HTML per se, but a templating language wrapping HTML. Similar to the idea there, and the idea in https://github.com/syntax-tree/unist/discussions/59, having parsing specific to the templating language could/would address the mismatch.
I believe we have talked about ASTs and CSTs in several threads now, perhaps this is an XY problem? Maybe there is a root problem that you’re having that can be solved?
Yes, we've discussed CST's before. I'm mainly concerned about encoding of the ampersands. I don't know if the fact that it is an AST affects this specific issue, since I'm not concerned about formatting/spacing here and I'm observing that text remains the same (except for things like quotes).
I guess the root problem is I want a parser/serializer that is not very strict. I just need to know the html that is there, and operate on it. I don't need to transform or even understand the templating syntax, just have it pass through. The files I have are safe, since they are my own files. I understand the need for following the HTML spec, but I thought there might be some escape hatches for different use cases. I understand your point, I may need to seek out a different tool or perhaps write a plugin down the line. It's difficult for me to abandon this approach just yet as there is significant code/time already invested and I've made it mostly work so far.
The ampersands in these examples are fine, but ampersands combined with other characters can create parse errors, notably “ambiguous ampersands”. See the readme of
rehype-parsefor more information. Parse errors do not crash HTML parsers, but they should definitely be avoided. That is why the HTML spec specifies that, when serializing HTML, all ampersands have to be encoded.
Thanks for the explanation. I guess this makes me wonder if this could fall under the option allowParseErrors. Or are those only for changes that save bytes?
I guess the root problem is I want a parser/serializer that is not very strict. I just need to know the html that is there, and operate on it. I don't need to transform or even understand the templating syntax,
That's generally not how parsers work. The templating language directly conflicts with HTML on some characters. It doesn't matter if the parser HTML is loose or strict, if the syntax conflicts with HTML, both types of HTML parsers will produce unexpected results from your templating language's perspective. The parser needs to be taught how to handle the templating syntax to produce consistent results.
just have it pass through.
Again this would be a CST.
The files I have are safe, since they are my own files
I appreciate the sentiment, but those sound like some famous last words. :sweat_smile: This edge case points to the potential (and likelihood) of more complex edge cases, that would need to be handled, to work around not parsing the template language.
It's difficult for me to abandon this approach just yet as there is significant code/time already invested and I've made it mostly work so far.
You may not need to, many templating language also produce an AST. It may be possible to adapt that AST into something https://github.com/syntax-tree/hast or https://github.com/syntax-tree/unist compatible. (Similar to what is done from rehype https://github.com/syntax-tree/hast-util-from-parse5) Which would allow plugins and other custom work to remain unchanged.
Then adding handler(s) to hast-util-to-html (or a new plugin) for the additional templating types added to hast.
I thought there might be some escape hatches for different use cases
There are some, maybe there could be more. And where there aren't https://www.npmjs.com/package/patch-package can also offer an alternative.
I just need to know the html that is there, and operate on it.
You already have this. You can use unified only to parse a document into a tree. Then you can access the positional info on nodes. You can use that to find certain nodes, and only replace those, by slicing the document based on their positions.
I guess this makes me wonder if this could fall under the option
allowParseErrors. Or are those only for changes that save bytes?
Yes, some option like that is likely possible. It would also save bytes (a & b -> a & b).
I was thinking of adding it to stringify-entities, which has several options to control what character references are generates.
It is likely a good idea to add the option. But as I noted before, I think you’re asking about an XY problem: it sounds like you’re asking about one symptom, and when we solve it, two other symptoms will pop up. Perhaps you can take some time to explain more generally what you are doing with unified?
Closing. As it stands I am not yet convinced this should go here as-is. Maybe somewhere else? Or maybe it can be clarified?
Hi! This was closed. Team: If this was merged, please describe when this is likely to be released. Otherwise, please add one of the no/* labels.