all: Collect and suggest additional sharing links
Replaces #5758, now with proper storage in the database. Original disccussion on the forum.
Purpose
The ClusterConfig message from remote devices includes information about their peers for each common folder. This information is currently not considered at all, so here we start making use of it to show the user suggested links to close gaps in the mesh network structure. An announced device which is already configured locally will be highlighted in a folder's configuration because it already shares the folder indirectly. Other announced devices are listed as links to quickly add them locally and request sharing of the common folder.
To ease the review, I've split the changes in several smaller feature commits:
- Database storage layout and DB utility functions to handle those entries.
- Collection of candidate links when parsing remote ClusterConfigs.
- Removal of recorded candidate links when the involved devices / folders are changed in the config.
- Removal of recorded candidate links when no longer contained in a new ClusterConfig message.
- REST API endpoints for structured views of the stored data, grouped by candidate device or common folder.
- Dummy data to exercise the endpoints, used for the API documentation example response. [can be dropped later]
- GUI adaptation for known and unknown devices within a folder's "Sharing" tab.
- GUI adaptation in a device's "Sharing" tab to highlight folders for which that device is a candidate.
Known Issues
-
[ ] Some of the collected information (who introduced and when) is shown in a tooltip, but the user should have a better way to inspect why these suggestions are made. A separate dialog could be added, based on the mockups on the forum.
-
[ ] The GUI changes are currently only used when editing a folder, not when adding a pending folder shared from another device. In theory, there could already be candidate devices, so showing them in that incarnation of the dialog would make sense.
-
[ ] Candidate links are currently not stored if the announced folder is not yet configured locally ~~or paused. In both cases,~~ This could be helpful information, so this should be considered as well. EDIT: No issue if folder is paused.
-
[x] ~~The connection metadata (addresses, certName, name) for candidate devices is omitted in storage for known devices. If they are removed locally, they could still show up as candidates, but now unknown and with the details missing. So this could be changed to omit the data when building the API response, but collect it in the database in either case.~~ EDIT: Filtering is now done when building the API response.
-
Some smaller issues and questions marked FIXME in the code. RFC.
Testing
So far only manual GUI testing: All devices are listed under the expected category in a cluster with five devices. Selecting the suggested devices works, including cleanup of obsoleted entries. Clicking a suggested device ID replaces the Edit Folder modal with the Add Device modal, with the common folder preselected for sharing.
Screenshots
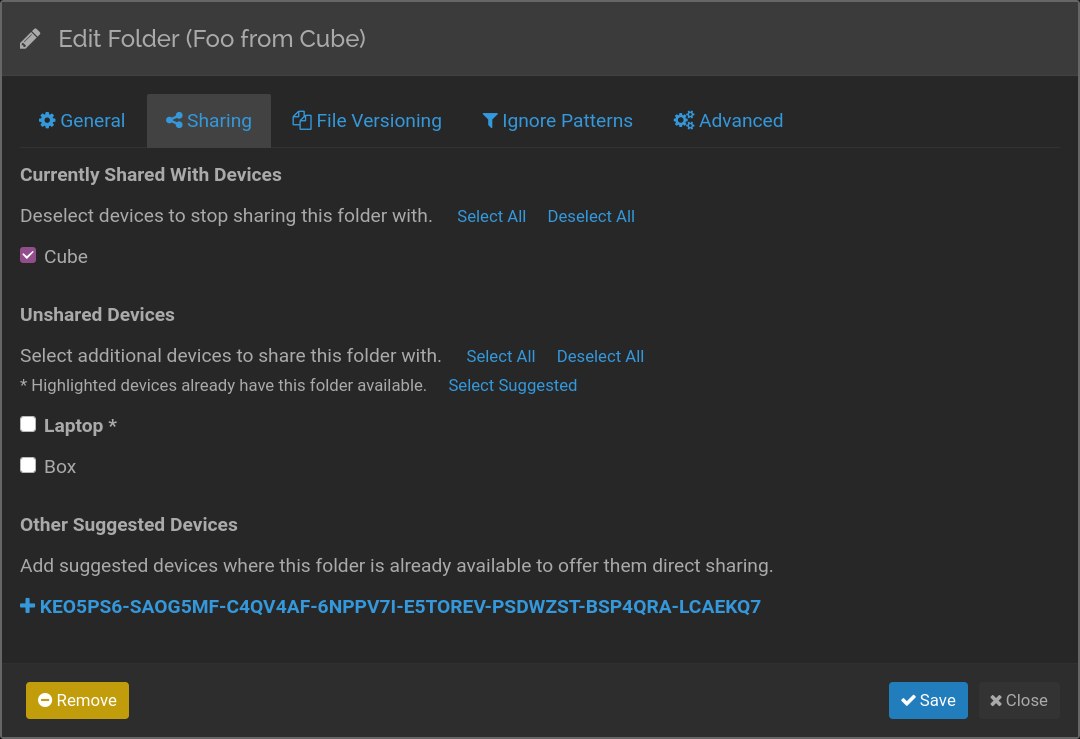
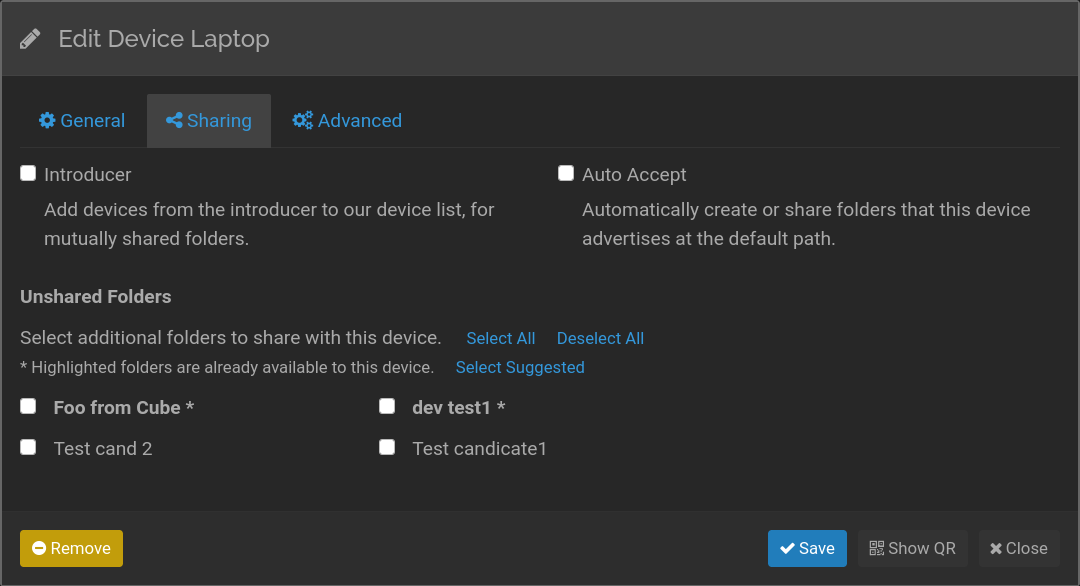
Documentation
End user documentation is not yet written, waiting to finalize the design first.
REST API documentation is added in https://github.com/syncthing/docs/pull/499.
I had a rough look at the Go part and first impression: It's a lot of code for a bit of usability. I do think (or at least hope) that can be trimmed down though.
E.g. there's 4 exported types for candidates: ObservedCandidateLink, CandidateDevice, CandidateFolder and CandidateLink. I think the first is db internal, exported only due to proto (maybe we can change that, will have a look later). I don't understand the need for the separate types. If you need the info indexed by folders and devices, just give the same type indexed by either folder or device ID?
And could you please remove all the unused and for development only code in the PR and keep that locally only - it's a lot to look at already :)
I had a rough look at the Go part and first impression: It's a lot of code for a bit of usability. I do think (or at least hope) that can be trimmed down though.
First of all: Thank you for taking a look at this. I agree that right now it's not a huge impact from the user perspective, because the GUI is kept deliberately unobtrusive. But I see some value in the stored data, with potential to add a more comprehensive overview later.
E.g. there's 4 exported types for candidates: ObservedCandidateLink, CandidateDevice, CandidateFolder and CandidateLink. I think the first is db internal, exported only due to proto (maybe we can change that, will have a look later).
You're right, ObservedCandidateLink should not necessarily be exported, but I couldn't achieve that through protobuf. It holds the metadata (DB value) and the topological information is in CandidateLink (mirrors the DB key).
I don't understand the need for the separate types. If you need the info indexed by folders and devices, just give the same type indexed by either folder or device ID?
CandidateDevice and CandidateFolder are differently structured views of the data, I think you got that right. There are three levels of maps involved, because of the candidate - folder - introducer relationships. Making one of them the "primary" for grouping means the levels below need to change, so it can't be the same contained type. Of course the structure could be flattened by using CandidateLink everywhere, but then it's more cumbersome for the API user. Regarding where this lives, there were several options:
-
lib/db/observed.go: Allows filtering while building the structure, instead of fetching all and then discarding again. It's a nicely self-contained place with only related functionality. -
lib/modelorlib/api: Already very large, didn't want more bloat. API would be logical to serve differently structured views when the rest of the backend doesn't need them. -
gui: Probably more cumbersome in JS, no pre-filtered data, not reusable for other frontends.
So I decided to keep it on the lowest level, although it's really sophisticated for a "data storage" layer. The types are designed so that the API needs no more transformations besides JSON marshalling. So if you question whether the different types are needed, we should try to agree on the API contents first before further discussing the backend implementation?
And could you please remove all the unused and for development only code in the PR and keep that locally only - it's a lot to look at already :)
Done. Did you look at the individual commits or just the end result? Because I tried to explain each step and make it easier to review with several smaller commits.
Regarding the merge conflicts, I noticed that the existingDevices and existingFolders caches were removed in initFolders(). With this PR, two function calls need the same input data, so rebuilding through DeviceMap() and FolderMap() twice seems unnecessary. Should I go back to the two local variables?
@imsodin The latest merge of main here wasn't really smooth in the GUI. The addDeviceAndShare() function was added before the default device config stuff and I'm not quite sure about the best way to replicate the new approach. Should probably factor out the request for /rest/config/defaults/device into a reusable function?
@imsodin I know you are quite busy with many topics around Syncthing. Just kindly asking for another (or continued) review of this PR? Would be nice to make some progress, especially if any extensive changes are going to be required (I hope not!)
Thanks for your patience waiting for my reaction. I do agree we should talk about API/UX primarily, otherwise we might use time for implementation aspects that then don't get used/need to be majorly changed. However I still need to continue the complexity topic, to not create false expectations:
As it is to me the benefits of this PR are much smaller than it's complexity. Following what the code does isn't overly complex, it's structured and commented, no complaint there - it's that there is a lot to follow. The kind of questions that I can't answer within reasonable time/effort for myself are "what's the purpose/need of all the types/methods". Again, I can follow when what is called/used, I just don't get the overall purpose/need/idea. And that might totally be a case of not enough effort done by me to understand it properly, and that's the problem: I am not willing to invest that much given the benefit.
That's why I brought up consolidating types above. I see your argument that doing that will just move the complexity somewhere else. I hoped that the types could be exchanged for some more conditions in the already existing loops in JS and thus the overall complexity reduced, but obviously I might be wrong.
On the UX side I tend to agree with @AudriusButkevicius from the topic you linked to above:
I agree that this is useful information that we are not showing, but I kind of disagree where this is being exposed.
I’d create a new menu item with a modal called “nearby/neighbouring devices”, which shows this information and allows adding devices and sharing shares, without cluttering the existing workflow.
Also, less accidental select all’s that people can click.
The proposal in this PR is neat in that it includes all the information in one, "list-like" view. However for most use-cases with low numbers of devices it adds more elements and explanations which I expect to cause more confusion than clarity/help. A separate dialog showing all this information that may be accessible from a single additional button in the sharing tab like proposed on the forum seems like a good idea.
As it is to me the benefits of this PR are much smaller than it's complexity.
I was probably thinking way further ahead, but neglected to say so clearly and put it into perspective. So the current UX doesn't need all the structured data now included in the APIs, totally agree. It needs an answer to three simple questions: For a given folder, which devices already share it indirectly? Who else is connected to that folder that we don't know yet? And for a given device, which of our folders do they already have, but we don't share directly?
As storing and serving this information at all is completely new, I came up with a broader approach that allows more sophisticated UI or other API uses in addition. So exposing more of it in the GUI ideally requires no more backend changes than what's in this PR.
One chunk of complexity comes from not limiting the response to a single device or folder if the API parameter is omitted. Then it returns all possible candidates, with exactly the same data structure. This part is important for a future "things you'd like to share in addition" dialog.
The other chunk concerns the obligatory follow-up questions for such suggestions: "Says who?" and "How up to date / stale is that info?". If the query was not restricted to a certain folder ID, also "What is the common link (shared folders) for making this suggestion?" (basically in which Folder section of a ClusterConfig was the device mentioned).
Making all that previously discarded information available for API consumers is my main motivation for this PR. But without any UI component at all it would be even more questionable, so I brought along a minimally intrusive but IMHO very useful UI implementation. Even if no overview panel is added in our GUI, I see the API endpoints as a useful service to external visualization / analytics software. But maybe I'm seeing the API too much like a web service type of thing, while it's just intended as an internal interface between backend and frontend? AIUI, Syncthing itself is designed to be independent from the (graciously included) Web GUI.
Having said that, of course I want to build an overview panel for this detailed information. But it is a) hard to make clear and comprehensible, b) another learning curve for me regarding Angular UI and c) depends on the backend code contained herein. So I focused first on getting the backend right.
The proposal in this PR is neat in that it includes all the information in one, "list-like" view.
Thanks, that's good to hear. I think it doesn't need to compete with a full-blown dialog, but complements it while already being useful in itself.
However for most use-cases with low numbers of devices it adds more elements and explanations which I expect to cause more confusion than clarity/help.
I took great care to keep elements hidden when not needed, so the simplest cases will look just the same.
A separate dialog showing all this information that may be accessible from a single additional button in the sharing tab like proposed on the forum seems like a good idea.
You mean add a new button within e.g. the Edit Folder - Sharing tab, that would lead to another modal overlay? I think that is hard to reach, two steps behind the Edit button on a folder. My thinking was closer to a top-level button like the Recent Changes dialog. That would be one central entry point to get hints on the "connectedness" of a cluster. If you happen to know Debian's aptitude tool, kind of like its "Audit Recommendations" command.
As usual, nothing wrong with the arguments you make. However the beneifts (nicer api, future more helpful UI dialogs) still do not justify the current complexity for me.
One trade-off you explain is complexity in the db/api vs complexity in the web UI. I am actually much more likely to be ok with complexity in the UI than in the db/api. If that turns out bad in any way, it can just be dropped. All the complexity in db/api is there to stay. And I still believe that a simple/basic/flat structure in the api and processing that in the UI will even be simpler overall.
With regards to the UI comments: I think the elements will still come up in many "basic" setups. E.g. when pairing two devices and selecting to share a folder with the remote: The remote device will be shown as having that folder, right? I mean it's correct, but it doesn't really add anything in that situation and the additional element/text is something more the user needs to "consume" (read, understand).
One trade-off you explain is complexity in the db/api vs complexity in the web UI. I am actually much more likely to be ok with complexity in the UI than in the db/api. If that turns out bad in any way, it can just be dropped. All the complexity in db/api is there to stay. And I still believe that a simple/basic/flat structure in the api and processing that in the UI will even be simpler overall.
It's also about efficiency, which in my mind is always a first-class concern. Pulling stuff out of the DB, then filtering out what's requested is more efficient than sending out everything over the wire in a flat structure, then using only a small part of the response. The backend knows best how to interpret the recorded data and refine it into a structure that summarizes its meaning. Doing that in "the" GUI means re-doing it in every API consumer.
I understand your concern, though must say I'm a bit sad again about the timing. I put up https://github.com/syncthing/docs/pull/499 for discussion almost one year ago, without getting any feedback. Did some restructuring there in November while starting work on the implementation, and based on changes to the related "pending" endpoints. The API really is the heart of it, where I spent most brainpower to present the information in meaningful ways and enabling future extended use. I'd really like to see that effort come to fruition, especially now that it's already implemented.
If nobody wants to make use of it, there will be low resistance and I'll help in reverting it to a simplified structure. My hope though is that having the information there easy to consume will spawn new ideas for using it, maybe outside of our GUI.
Is there any concrete pain point where the API responses are hard to grasp for you, or is it really just the amount of new code? Do you have a concrete idea for a "simpler" response structure? Something along the CandidateLinks() return value?
Btw. my first drafts had a much more complex storage layout in the DB already. I flattened that to what is now the internal CandidateLink struct, but kept the REST APIs as designed for their intended use.
With regards to the UI comments: I think the elements will still come up in many "basic" setups. E.g. when pairing two devices and selecting to share a folder with the remote: The remote device will be shown as having that folder, right? I mean it's correct, but it doesn't really add anything in that situation and the additional element/text is something more the user needs to "consume" (read, understand).
Your example is not quite clear to me, but I think you got it wrong. When the folder is shared to the (single) remote device, it will show up under "Currently Shared With Devices", and the remark under "Unshared Devices" (resp. the whole heading) will be hidden. Have you tried it? Might be some bug introduced during recent merges from main if it is in fact visible.
I just merely glanced at the code and the previous discussion, so this is superficial. But this seems to echo precisely the discussion we had in your previous large PR, which surprises me a bit. It's an almost 1000 line addition for a piece of functionality that doesn't intuitively seem to merit that amount of code.
Different people and different projects have different things that they feel are important. We have a culture of putting simplicity and maintainability foremost. You seem to have a culture of putting efficiency and, perhaps, theoretical beauty foremost. You're not wrong in prioritising what you feel is important. You will however get a lot of pushback when what you do is vastly different to how we would have done it.
I just merely glanced at the code and the previous discussion, so this is superficial. But this seems to echo precisely the discussion we had in your previous large PR, which surprises me a bit. It's an almost 1000 line addition for a piece of functionality that doesn't intuitively seem to merit that amount of code.
Thank you. Then I would appreciate some deeper look at what this thing does, because I fail to find a direction pointer in your response. Please help me understand which part(s) of those 1000 lines are acceptable and where it starts to make you shiver. After all, it's about collecting a new "data category" that previously was not persisted, and the GUI-visible change is just a minimal way to utilize it.
Will it help to split off the data collection in the DB into a separate PR, then discuss smaller additions for making use of it?
Regarding similarity to the previous PR discussion: It would have helped to get more feedback on the design early on, to maybe stop me before overthinking it. I somehow have a hard time explaining to you what my goal is in helping to extend Syncthing's functionality, either in the original forum discussion, or through a concrete code PR. At least up to a point where I can image how you'd go about it.
Oh and by the way, I'm a German engineer, so overthinking things is probably national heritage ;-)
Let me take an actual look at this and see what I would do instead of theorising. If it's in the same size ballpark as what you did I'll shut up and go away. :)
I started on a thing with my preferred approach:
https://github.com/syncthing/syncthing/compare/main...calmh:candnogui
Basically, track the relevant things in a regular data structure, update it from the model calls, serialize as appropriate. I don't think it's done, I run out of time and task switched, but it's how I would approach the problem.
I think it also does less than your variant, you're doing something with introducers that I didn't look into and (if I remember correctly, not looking at it now) you're cleaning out shared folders and taking care to just track "candidates" while I opted to just track all known folders (shared + "candidate") which is simpler.
Thanks for your suggestion @calmh. I scanned through it and it lacks some features compared to this PR (probably not exhaustive):
- The API needs to be called for every device (or folder) in turn to get a complete overview of candidates. This will also generate a lot of redundancy in the responses.
- The API user cannot tell where a specific candidate came from. That's vitally important information for me, to decide whether the suggested link can be trusted or makes sense for the desired topology.
- It makes no distinction on whether we actually share a folder with the device whose ClusterConfig advertises it. Therefore, following the suggestion might give access to some device that in fact has not previously shared our data indirectly. This cannot even be worked around by the API user because of the missing information mentioned above.
- As you say, cleanup for no longer known devices / folders is not included yet.
Some of these just move the complexity to the user side of the API for making sense of the collected entries, so that accounts for a bit less code. Others are simply impossible because the topology information is lost in your storage. So I think to reach roughly feature parity, your solution will end up with about as much code as this PR.
It also deviates far from the way we now handle pending devices / folders, which are logically all "observed" stuff, hence I treated them equivalently.
If we'd follow your route, it will be a different feature than what I wanted to enable. Additionally, my code is pretty much complete, tested and already adjusted for some corner cases I didn't see either in my first iterations. So I question if all that effort should be spent again just to reach parity or maybe less. It comes back down to who needs the feature and who is willing to contribute an implementation vs. who will maintain it. I offer both, and have some more ideas what to extend later on top of it. If the main concern is that my approach is harder to grasp, I can only offer to explain what's unclear, and we should start off discussing the API in that case.
I was trying to express the following before, but held off because @calmh brought up a concrete alternative approach. Now we are again in a similar spot, so here it goes:
There's a fundamental (as in not tied to actual code/proposals/PRs present) divide between our (Syncthing maintainers) and your approach, that makes these PRs become so slow and tedious. And I want to stress up front that this is not about good or bad, but about different options and a choice. The choice we as a project (basically people that invested a lot of time in it) are making is to strive for simple, robust and slim solutions. Now we definitely don't always reach those attributes as well as we'd like, I know I failed at it repeatedly. Large/complicated changes have to either address an important problem or bring a large benefits (indeed, subjective criteria).
Disclaimer: Story time - one can skip this entire paragraph without missing much:
Examples are my db PRs, which are terrifying. I really don't like them for all the points mentioned above. Audrius already has memes ready to express "DB? I am not going to stick my nose anywhere close to that!" and in some not-so-recent-anymore PR Jakob stated that the merge happened at least partly on trust only. That's truly terrifying to me, but there were documented and reproducible issues, that I couldn't think of solving a better way and I believe the changes made the code more robust. That's why they happened.
I have scrapped countless ideas, even fully functioning branches, because I was looking at the diff and thinking: I don't want anyone to review that in their free time (nor could I make them).
Or the encryption feature: It's easily the longest standing, most requested feature out there. There have been attempts before. It only now happened once Jakob found away to sneak it into the existing framework, with "minimal" changes. Square-quotes because it's still a lot of change.
Put another way: We value maintainability far above performance and "implementation-beauty". Large changes and/or new code require a strong justification/large benefit. Again that's not the correct or objectively right way to do it, it's just "our way". And likely I fell short of communicating this and my own view of the "cost-benefit-balance" in your PRs. I tried doing it in my earlier comment, and I didn't feel like the base message got through reading your latest comment:
As it stands the benefits (hints about new connections in the UI, nice rest API endpoint), to me do not justify the complexity of this PR. And thus I am not interested to review, approve and jointly (I do believe that you intend to stick around, you proved as much) take over maintaining this code and functionality.
I would be much more inclined to engage in discussions and keep providing suggestions to get this into a state more aligned with the principles outlined, if I sensed that you understood and accepted what those are. You need to like them, I just want to see signs that you take them seriously.
This code is bit-rotting really fast (#7537, #7567). I'd appreciate if we could reach a decision soon. #7503 will probably introduce the next conflicts which will be additional work for me to resolve.
As it stands the benefits (hints about new connections in the UI, nice rest API endpoint), to me do not justify the complexity of this PR. And thus I am not interested to review, approve and jointly (I do believe that you intend to stick around, you proved as much) take over maintaining this code and functionality.
@imsodin thanks for chiming in. I'm still having a hard time understanding what exactly the problem is, but this explanation is the best I read so far. Apologies if some points will be repetitive, but I also forget things that have been said, for this discussion has been dragging on for quite long already.
What I'm not sure about yet is whether the problem is complexity in my implementation or complexity of the perceived problem I try to solve. @calmh's alternative approach points toward the former, but is targeted at only a small part (basically the current UI suggestion) of the added benefit I see. If we disagree about that benefit OTOH, that's what should be cleared up.
My goal: Keep a record of known-to-be-missing (but maybe useful) sharing links and make that information available in a useful form. The relationships there are what's complex, and I say that because I thought about them long and hard, with countless tries to come up with a summarizing data structure. That should be dependable (no suggestions that might trick the user into sharing data inadvertently), comprehensible, and avoid unnecessary repetitions.
Immediate benefit: Included GUI enhancement to suggest devices / folders in sharing tab. Future benefit: Data can be used easily in external API tools and for future GUI enhancements. I like to design once, then build upon, when there is a future goal already known. So yes, the code does too much for the immediate benefit. But it's the ground work I want to re-use later, and maybe others. Changing the API in between makes no sense IMHO.
I wonder why has nobody ever looked at the docs PR, raising complexity concerns there? Why has no-one commented on the future enhanced GUI mockups I posted in the forum thread? Why is time being spent on a completely different implementation approach instead of seriously diving into this one (so far everyone said they just looked at it roughly), which stays very close to the existing mechanism from #6443? Why do I feel like many of my comments and explanations here are partly unnoticed or unanswered (like "for ... reasons, the alternative implementation will end up just as many LOCs")? (end of rant, feel free to answer any of those...)
I would be much more inclined to engage in discussions and keep providing suggestions to get this into a state more aligned with the principles outlined, if I sensed that you understood and accepted what those are. You need to like them, I just want to see signs that you take them seriously.
Sorry if I seem stubborn and fail to see where exactly your concerns lie. But from my perspective, it looks like everybody is scared off by the perceived complexity so we don't even talk about possible legitimate reasons why it looks like it does. A wise person once told me anything is trivial once you've stared at it long enough. Well I have, and it holds true. I wish someone else would seriously consider the details in and reasoning behind this PR (hint: much effort was spent on comprehensible commit messages), instead of punting off to discard the suggested implementation entirely. And I wish that had happened much earlier when I proposed the API (one year ago) instead of now that my volunteer work hours have been spent already.
It's my feature idea to scratch my itch and hopefully bring improvements for many users (of which I know a couple). Nobody cared enough to discuss the design drafts, so please understand that I keep pursuing my idea of how it should work. Can we just please get this discussion to a more technical level?
Sorry for the long read (again), brevity is obviously not my strength.
Up front because I think that gets lost and I can drop some "I thinks", "subjectively", ...:
Again, it's not about right or wrong objectively, it's about what I want - based on precedent, available time and energy and also just pure opinion/taste/... You want my time to review and co-maintain this, so my opinion matters. The following is my opinion.
If we disagree about that benefit OTOH, that's what should be cleared up.
Apparently I haven't been frank enough, so clearing that up: The benefit is far smaller than the cost of adding this code.
And future higher benefit is nice, but not the main deciding factor: What is to be merged is.
(like "for ... reasons, the alternative implementation will end up just as many LOCs")?
I engaged in some of that, because I do believe there are simpler ways of achieving something similar. I might be wrong, obviously. Then I don't think it's worth working on this, again due to the imbalance between benefit and cost.
As to not getting comments on UI drafts and API specs: I do believe you got some, clearly not of the kind you'd have required. I for one cannot give you all the feedback relevant to what we are discussion now, just based on those. To do that I needed to think through to the detail how I might arrive at those - that's already half the work to the end state. Maybe I am "not good enough" to just see that or am not investing enough time, in both cases either your expectations are off or pity for the project that standards are so low (couldn't resist a bit of sarcasm and hyperbole).
Can we just please get this discussion to a more technical level?
I wont do that. I have enough other things that require my energy, in Syncthing and outside of it, to spend much here. And just in case the Swiss attitude of beating around the bush got in my way again (feels plenty direct, almost rude to me already): I wont engage in any more meta discussions and in technical discussions only on questions/aspects related to dumbing this code down. As a consequence I won't review this PR as is.
Apparently I haven't been frank enough, so clearing that up: The benefit is far smaller than the cost of adding this code. And future higher benefit is nice, but not the main deciding factor: What is to be merged is.
So the two options are: 1. Extend what is to be merged for even higher benefit. Not likely to attract more review. OR 2. Reduce what it does to the absolutely necessary, then come back and overhaul it again once additional features land in future PRs. Disregards that we are talking persistent formats (DB proto) and an API whose consumers may not live within the same code-base. (Unless I misunderstood the "API" nature, as previously asked.)
As to not getting comments on UI drafts and API specs: I do believe you got some, clearly not of the kind you'd have required.
Zero comments on https://github.com/syncthing/docs/pull/499 and possible future UI mockups. Otherwise I would not dare to complain.
I for one cannot give you all the feedback relevant to what we are discussion now, just based on those. To do that I needed to think through to the detail how I might arrive at those - that's already half the work to the end state. Maybe I am "not good enough" to just see that or am not investing enough time, in both cases either your expectations are off or pity for the project that standards are so low (couldn't resist a bit of sarcasm and hyperbole).
I highly value every maintainer's technical ability, never meant to indicate otherwise. And a lack of interest for some ideas and consequently not investing time is understandable. Thanks for your honesty, though your statements in #5758 led me to believe there was a better chance to work together on this.
:robot: beep boop
I'm going to close this pull request as it has been idle for more than 90 days.
This is not a rejection, merely a removal from the list of active pull requests that is periodically reviewed by humans. The pull request can be reopened when there is new activity, and merged once any remaining issues are resolved.
:robot: beep boop
I'm going to close this pull request as it has been idle for more than 90 days.
This is not a rejection, merely a removal from the list of active pull requests that is periodically reviewed by humans. The pull request can be reopened when there is new activity, and merged once any remaining issues are resolved.
:robot: beep boop
I'm going to close this pull request as it has been idle for more than 90 days.
This is not a rejection, merely a removal from the list of active pull requests that is periodically reviewed by humans. The pull request can be reopened when there is new activity, and merged once any remaining issues are resolved.
Still intend to get this functionality in, after maybe some rework and definitely getting it back in shape without merge conflicts.