sutracli
 sutracli copied to clipboard
sutracli copied to clipboard
Sutracli is an AI-powered code manager for coding agents. It spawns agents for multiple projects, connects repos through cross-indexing, and builds dependency graphs for better change suggestions. By...
Sutra Knowledge CLI
An intelligent codebase analysis and knowledge management tool that provides AI-powered insights, semantic search capabilities, and comprehensive project understanding through advanced parsing and embedding technologies. Focus on writing your code and thinking of the business-logic! The CLI will take care of the rest.
⚡️ Quick Start
First, download and install Python. Version 3.11 or
higher is required.
Installation is done by using the pip install command:
pip install sutrakit
Setup environment
Sets up ~/.sutra directory, downloads ML models, creates config files, sets environment variables, and prepares BAML client for AI code analysis.
sutrakit-setup

That's all you need to know to start! 🎉
Indexing Your Projects
To enable analysis, each project must be indexed. This process parses the codebase, extracts structures, and builds embeddings for semantic search.
- Navigate to your project directory (e.g.,
cd my-project). - Run
sutrakit– if the project isn't indexed, you'll be prompted to do so.- Confirm indexing when asked; it typically takes a few minutes depending on project size.
For ecosystems with multiple related projects (e.g., backend, frontend, microservices):
- Repeat the above in each project's directory.
- Sutrakit automatically links them by matching connections, creating a dependency graph for ecosystem-wide analysis.
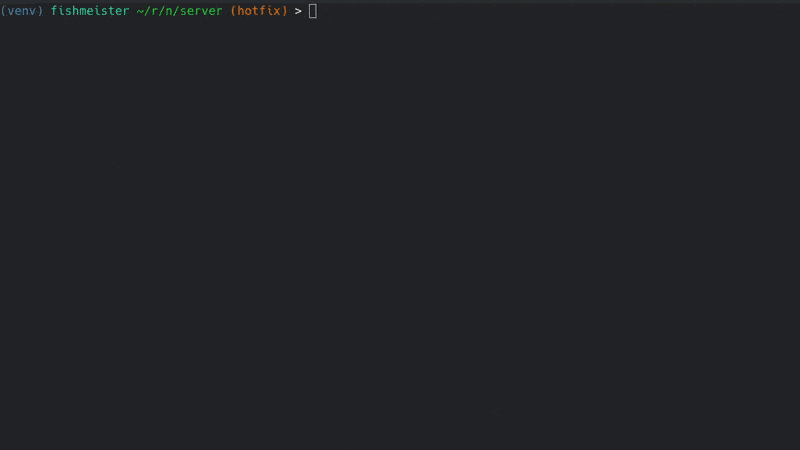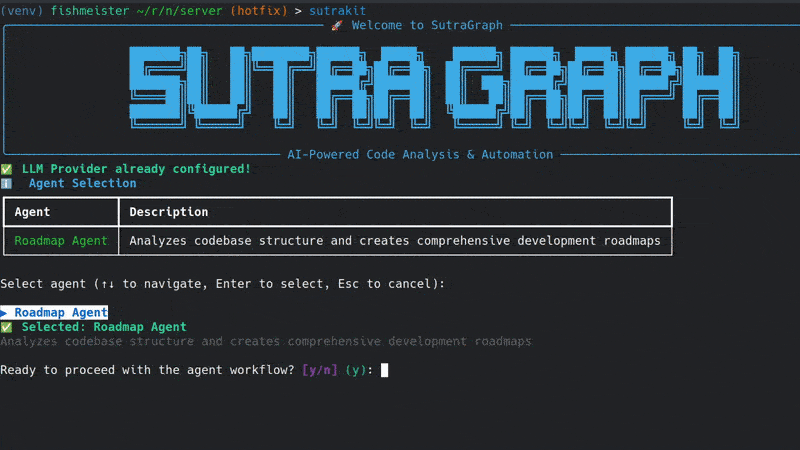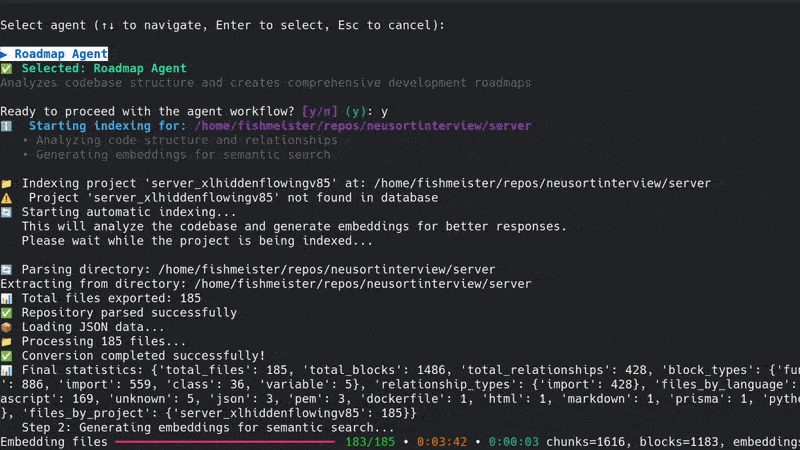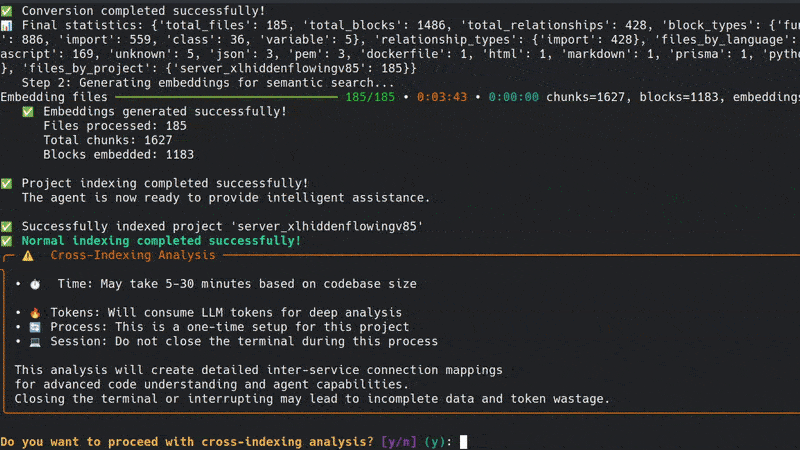
Important Note:
- For the Roadmap Agent to fully discover and navigate inter-project connections (e.g., API calls, message queues, WebSockets), cross-indexing is required during the indexing phase. This builds a dependency graph of external links that standard parsing might miss. Without it, the agent can't trace code flows across projects, resulting in incomplete roadmaps.
- Do not run cross-indexing parallelly for multiple projects, as it can lead to conflicts and incomplete or incorrect dependency graphs.
Supported Languages and Parsing:
Sutrakit uses Tree-sitter for advanced AST-based parsing to extract code blocks such as functions, classes, methods, etc. Currently, this is fully supported only for Python, TypeScript, and JavaScript, where custom extractors have been implemented for precise structure extraction and embedding. For other languages, the tool falls back to default file-based indexing, where individual code blocks are not extracted—instead, embeddings are generated based on chunks of a certain word length. As a result, the quality of semantic search, analysis, and insights may vary for unsupported languages.
📝 Key Features
Sutrakit is an orchestrator for AI agents and services, focused on multi-project codebase analysis and management. It helps developers handle complex ecosystems by providing intelligent insights and automated workflows. Below are the core features, with a diagram for the key component.
-
AI-Powered Roadmap Agent:
- Processes user queries to create minimal plans across projects.
- Identifies change locations, reuses code, and defines integrations.
- Refines via feedback; orchestrates sub-agents for execution.
-
Orchestration of Sub-Agents:
- Spawns AI sub-agents for parallel project updates.
- Handles dependencies seamlessly.
- Note: Before spawning sub-agents, set up and authenticate rovodev or gemini CLI tools (currently supported providers). Install them via their respective docs (e.g., pip install rovodev or Google Cloud SDK for Gemini) and ensure auth (API keys, tokens) is configured to avoid runtime issues.
-
Cross-Indexing Service:
- Discovers and indexes external connections (e.g., APIs, message queues, WebSockets) beyond standard parsing, using advanced matching for identifiers, parameters, wrappers, and variables.
- Builds a dependency graph by scanning new projects against existing ones, creating links for matched connections to enable seamless navigation and hopping between projects during analysis.
-
Semantic Search and Code Analysis:
- Queries codebases with semantic/keyword tools.
- Manages memory to optimize operations.
Roadmap Agent Workflow
flowchart TD
A[User Query] --> D[Analyze & Plan]
D --> E[Verify & Review]
E -->|Refine| D
E -->|Approve| F[Execute via Sub-Agents]
F --> SA[Sub-Agent: Project A]
F --> SB[Sub-Agent: Project B]
F --> SC[Sub-Agent: Project C]
Use Cases
Sutrakit excels in interconnected projects like microservices or full-stack apps:
- New Feature: Maps backend-to-frontend changes; generates contracts; updates via sub-agents.
- Bug Fix: Traces dependencies; plans minimal fixes.
- Refactor: Analyzes patterns; roadmaps reusable updates.
- Onboard Repo: Indexes and links to ecosystem for integrations.
This keeps focus on practical value to see if it fits your needs.
Configuration
Sutrakit allows customization through the system configuration file located at ~/.sutra/config/system.config. This JSON file controls various aspects of the tool, such as database paths, storage directories, embedding models, logging, and LLM providers. You can edit it manually to tweak settings—changes take effect on the next run. Always back up the file before modifying, and ensure valid JSON format to avoid errors.
Here's a partial view of the config file (focusing on the LLM section for brevity; other sections like database and storage are omitted):
{
...
"llm": {
"provider": "aws_bedrock|anthropic|google_ai|vertex_ai|azure_openai|openai|azure_aifoundry|openrouter",
"aws_bedrock": {
"access_key_id": "YOUR_ACCESS_KEY",
"secret_access_key": "YOUR_SECRET_KEY",
"region": "us-east-2",
"model_id": "us.anthropic.claude-sonnet-4-20250514-v1:0",
"max_tokens": "OUTPUT_TOKENS"
},
"anthropic": {
"api_key": "YOUR_API_KEY",
"model_id": "us.anthropic.claude-sonnet-4-20250514-v1:0",
"max_tokens": "OUTPUT_TOKENS"
},
"google_ai": {
"api_key": "YOUR_API_KEY",
"model_id": "gemini-2.5-pro",
"base_url": "https://generativelanguage.googleapis.com/v1beta",
"max_tokens": "OUTPUT_TOKENS"
},
"vertex_ai": {
"location": "global",
"model_id": "gemini-1.5-flash",
"max_tokens": "OUTPUT_TOKENS"
},
"azure_openai": {
"api_key": "YOUR_API_KEY",
"base_url": "https://your-resource-name.openai.azure.com/openai/deployments/your-deployment-id",
"api_version": "2025-01-01-preview",
"max_tokens": "OUTPUT_TOKENS"
},
"openai": {
"api_key": "YOUR_API_KEY",
"model_id": "gpt-4.1",
"max_tokens": "OUTPUT_TOKENS"
},
"azure_aifoundry": {
"api_key": "YOUR_API_KEY",
"base_url": "https://RESOURCE_NAME.REGION.models.ai.azure.com",
"max_tokens": "OUTPUT_TOKENS"
},
"openrouter": {
"api_key": "YOUR_API_KEY",
"model_id": "openai/gpt-3.5-turbo",
"max_tokens": "OUTPUT_TOKENS",
"http_referer": "YOUR-SITE-URL", //Optional
"x_title": "YOUR-TITLE" //Optional
}
}
...
}
Example: Changing the LLM Provider
The "llm" section lets you switch AI providers (e.g., for the Roadmap Agent) and configure credentials. By default, it's set to "aws_bedrocks". To change it:
- Update
"provider"to one of:"aws_bedrock","anthropic","google_ai","vertex_ai","azure_openai","openai","azure_aifoundry", or"openrouter". - Fill in the corresponding subsection with your API keys or credentials (leave others blank if unused).
- Optionally, adjust model IDs for specific LLMs.
Switch to Anthropic Example:
"llm": {
"provider": "anthropic",
"aws_bedrock": { /* Leave as-is or blank */ },
"anthropic": {
"api_key": "YOUR_API_KEY",
"model_id": "claude-4-sonnet-20250514",
"max_tokens": "OUTPUT_TOKENS"
},
"google_ai": { /* Leave as-is or blank */ },
"vertex_ai": { /* Leave as-is or blank */ },
"azure_openai": { /* Leave as-is or blank */ },
"openai": { /* Leave as-is or blank */ },
"azure_aifoundry": { /* Leave as-is or blank */ },
"openrouter": { /* Leave as-is or blank */ }
}
After saving, restart Sutrakit to apply changes. For other sections (e.g., logging level or embedding model), edit values directly—refer to the file for details.
Common Maximum Output Token Limits
Here are typical max_tokens values for popular models (as of early 2025):
- GPT-5: 128,000 tokens
- GPT-4.1: 32,000 tokens
- Claude Sonnet 4: 64,000 tokens
- Gemini 2.5 Pro: 64,000 tokens
Note: The max_tokens parameter controls the maximum number of tokens in the model's output response, not the input context window. Always check your model's documentation for the exact output token limit, as these values may change with model updates.
🛠️ Development Setup
If you want to contribute to the project or modify the BAML configurations, follow these steps:
Prerequisites
- Python 3.11+
- Git
- pip
Quick Setup
-
Clone the repository:
git clone https://github.com/sutragraph/sutracli.git cd sutracli -
Run the development setup script:
./scripts/setup-dev.sh
This script will:
- Install development dependencies (including pre-commit)
- Set up pre-commit hooks
- Test BAML client generation
- Run initial code quality checks
Manual Setup
If you prefer to set up manually:
-
Install development dependencies:
pip install -e ".[dev]" -
Install pre-commit hooks:
pre-commit install -
Generate BAML client (if needed):
./scripts/generate-baml.sh -
Run Setup:
sutrakit-setup
Pre-commit Hooks
The project uses pre-commit hooks to ensure code quality and keep BAML client files up-to-date:
-
BAML Generation: Automatically regenerates BAML client files when
baml_src/files change - Code Formatting: Runs Black and isort on Python files
- Code Quality: Checks for trailing whitespace, large files, merge conflicts, etc.
- File Validation: Validates YAML, JSON, and TOML files
Working with BAML
When you modify files in baml_src/, the pre-commit hooks will automatically:
- Regenerate the BAML client files in
baml_client/ - Add the updated client files to your commit
- Ensure code formatting and quality standards
You can also manually regenerate BAML client files:
./scripts/generate-baml.sh
Running Tests
# Run all pre-commit hooks
pre-commit run --all-files
# Run specific hook
pre-commit run baml-generate
⭐️ Project assistance
If you want to say thank you or/and support active development of
Sutra Knowledge CLI:
- Add a GitHub Star to the project.
- Write interesting articles about project on Dev.to, or personal blog.
🏆 A win-win cooperation
And now, I invite you to participate in this project! Let's work together to create the most useful tool for developers on the web today.
- Issues: ask questions and submit your features.
- Pull requests: send your improvements to the current.
Together, we can make this project better every day! 😘
Metadata
Owner
Metadata
Sutracli is an AI-powered code manager for coding agents. It spawns agents for multiple projects, connects repos through cross-indexing, and builds dependency graphs for better change suggestions. By...