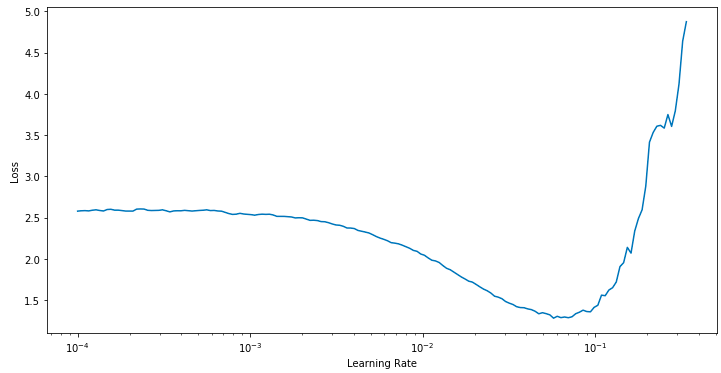
keras_lr_finder
 keras_lr_finder copied to clipboard
keras_lr_finder copied to clipboard
Published
20 hours ago •
 surmenok
surmenok
Add Exponential Smoothing Plot
After reading this blog post: https://sgugger.github.io/how-do-you-find-a-good-learning-rate.html
It seems that you can get better smoothing by using an exponential weighting. Could this potentially provide better a learning rate?
I'll make a pull request but my code currently looks like this:
def plot_exp_loss(self, beta=0.98, n_skip_beginning=10, n_skip_end=5):
exp_loss = self.exp_weighted_losses(beta)[n_skip_beginning:-n_skip_end]
plt.plot(self.lrs[n_skip_beginning:-n_skip_end], exp_loss, label="Loss")
plt.ylabel("Exponentially Weighted Loss")
plt.xlabel("Learning Rate (log scale)")
plt.xscale('log')
def plot_exp_loss_change(self, beta=0.98, n_skip_beginning=10, n_skip_end=5):
exp_der = self.exp_weighted_derivatives(beta)[n_skip_beginning:-n_skip_end]
plt.plot(self.lrs[n_skip_beginning:-n_skip_end], exp_der, label=r"exp weighted loss change")
plt.ylabel(r"Exponentially Weighted Loss Change $\frac{dl}{dlr}$")
plt.xlabel("Learning Rate (log scale)")
plt.xscale('log')
def get_best_lr_exp_weighted(self, beta=0.98, n_skip_beginning=10, n_skip_end=5):
derivatives = self.exp_weighted_derivatives(beta)
return min(zip(derivatives[n_skip_beginning:-n_skip_end], self.lrs[n_skip_beginning:-n_skip_end]))[1]
def exp_weighted_losses(self, beta=0.98):
losses = []
avg_loss = 0.
for batch_num, loss in enumerate(self.losses):
avg_loss = beta * avg_loss + (1 - beta) * loss
smoothed_loss = avg_loss / (1 - beta ** batch_num)
losses.append(smoothed_loss)
return losses
def exp_weighted_derivatives(self, beta=0.98):
derivatives = [0]
losses = self.exp_weighted_losses(beta)
for i in range(1, len(losses)):
derivatives.append((losses[i] - losses[i - 1]) / 1)
return derivatives
This repo implements exponential smoothing: https://github.com/WittmannF/LRFinder