realtime
 realtime copied to clipboard
realtime copied to clipboard
Sending batches of messages through WebSockets
Feature request
Is your feature request related to a problem? Please describe.
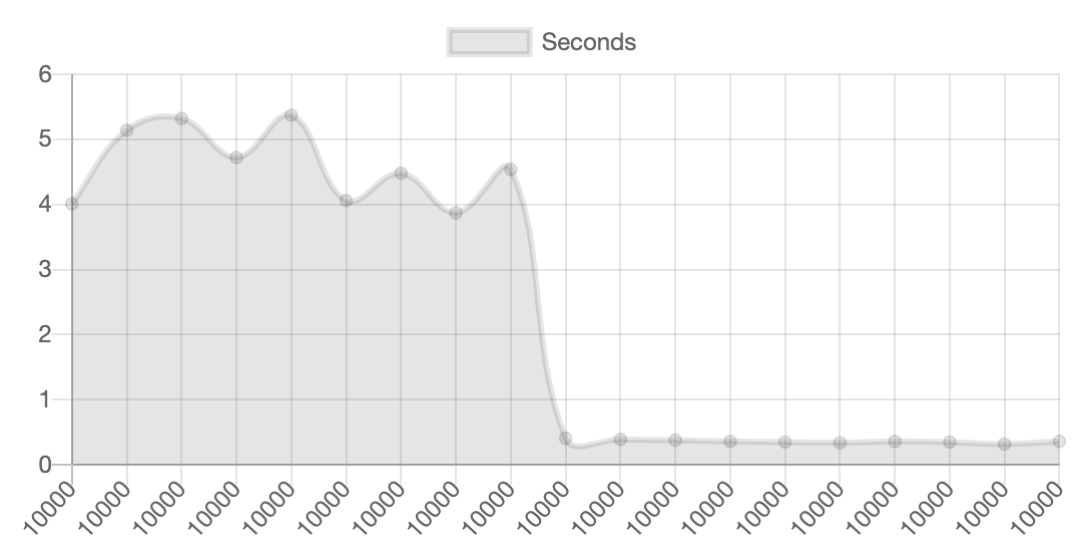
Tests show that sending messages by batches is much-much faster than by one (but eats more memory).
On the chart below first nine tries of 10k messages are sent one by one through broadcast_from, next in the batch.
Describe the solution you'd like
It needs to accumulate all changes in something like a queue. For sending needs to read first N changes (batch size) and then push that slice through broadcast_from.
On the client-side, we should receive a message with a custom event, eg "multi", where the payload will be an array and in the loop, have to handle all elements of how it's processed each old event.
In onConnMessage:
if (event === 'multi') {
const self = this
msg.payload.forEach(function(e: Message) {
self.channels
.filter((channel: RealtimeSubscription) => channel.isMember(topic))
.forEach((channel: RealtimeSubscription) =>
channel.trigger(e.type, e, ref)
)
self.stateChangeCallbacks.message.forEach((callback) => callback(e))
})
}
Describe alternatives you've considered
Use it only for large transactions.
Function like Realtime.SubscribersNotification.notify_subscribers but need to filter all changes and then send a slice (batch size) through broadcast_from.
Additional context
@abc3 awesome proposal!
eats more memory
Yep, you called it! Realtime already consumes a lot of memory when processing large transactions so this will definitely increase memory usage. However, I love how it's many times faster when sending large transactions.
We're planning some changes to Realtime, see (https://github.com/supabase/realtime/issues/134#issuecomment-831498705), and eventually when we introduce multi-tenancy and support listening to multiple Postgres databases, then this is something we'll need in order to improve performance and we'll have more available memory to go around when batching and broadcasting.
I'm going to keep this open b/c it's something we'll want to implement.
Thanks, @abc3!
Thanks!
Yes, that approach will eat more memory, but the speed is increasing so significantly! Anyway, my main goal was to share with you this chart. I was excited when I saw that :open_mouth:
@abc3 yea, I was blown away and got excited too! Also, it's a good thing you made that chart in the first place. Awesome to actually visualize it!