stanza
 stanza copied to clipboard
stanza copied to clipboard
[QUESTION] Rebuilding an existing language from sources
This is my first question, so sorry if I make any mistake, but I haven't had found information about rebuilding an exsiting language from its sources. I plan doing this before building a variant of the language with a variant of the corpus.
Tranks, I have missed this part of the documentation.
I have tried out the example of English-EWT, and it seems to work, though with lengthy trainings. Same result for Spanish-GSD, but Spanish-AnCora crashes at the very beginning claimning to lack files somewhere, and AnCora corpus is a very interesting one.
These are the error lines, where [[PythonPath]] shortens the path to Python folder.
2022-08-20 15:08:50 INFO: Datasets program called with:
[[PythonPath]]\Python39\lib\site-packages\stanza\utils\datasets\prepare_tokenizer_treebank.py UD_Spanish-AnCora-master
Traceback (most recent call last):
File "[[PythonPath]]\Python39\lib\runpy.py", line 197, in _run_module_as_main
return _run_code(code, main_globals, None,
File "[[PythonPath]]\Python39\lib\runpy.py", line 87, in _run_code
exec(code, run_globals)
File "[[PythonPath]]\Python39\lib\site-packages\stanza\utils\datasets\prepare_tokenizer_treebank.py", line 1136, in
The name is UD_Spanish-AnCora not UD_Spanish-AnCora-master
On Sat, Aug 20, 2022 at 6:15 AM student-nlp-project < @.***> wrote:
These are the error lines, where [[PythonPath]] shortens the path to Python folder.
2022-08-20 15:08:50 INFO: Datasets program called with: [[PythonPath]]\Python39\lib\site-packages\stanza\utils\datasets\prepare_tokenizer_treebank.py UD_Spanish-AnCora-master Traceback (most recent call last): File "[[PythonPath]]\Python39\lib\runpy.py", line 197, in _run_module_as_main return _run_code(code, main_globals, None, File "[[PythonPath]]\Python39\lib\runpy.py", line 87, in _run_code exec(code, run_globals) File "[[PythonPath]]\Python39\lib\site-packages\stanza\utils\datasets\prepare_tokenizer_treebank.py", line 1136, in main() File "[[PythonPath]]\Python39\lib\site-packages\stanza\utils\datasets\prepare_tokenizer_treebank.py", line 1133, in main common.main(process_treebank, add_specific_args) File "[[PythonPath]]\Python39\lib\site-packages\stanza\utils\datasets\common.py", line 134, in main process_treebank(treebank, paths, args) File "[[PythonPath]]\Python39\lib\site-packages\stanza\utils\datasets\prepare_tokenizer_treebank.py", line 1089, in process_treebank short_name = common.project_to_short_name(treebank) File "[[PythonPath]]\Python39\lib\site-packages\stanza\utils\datasets\common.py", line 19, in project_to_short_name return treebank_to_short_name(treebank) File "[[PythonPath]]\Python39\lib\site-packages\stanza\models\common\constant.py", line 177, in treebank_to_short_name assert len(splits) == 2, "Unable to process %s" % treebank AssertionError: Unable to process Spanish-AnCora-master
— Reply to this email directly, view it on GitHub https://github.com/stanfordnlp/stanza/issues/1102#issuecomment-1221313071, or unsubscribe https://github.com/notifications/unsubscribe-auth/AA2AYWPUUDIBNA7BXQZWA23V2DK7DANCNFSM564L4ZKQ . You are receiving this because you commented.Message ID: @.***>
Thnaks, I renamed the directory and now the trainer can access it, but I now get two differente errors in Windows and in Linux, and they seem to have to do with the training data format.
In Windows:
2022-08-20 16:59:31 INFO: Datasets program called with:
[[PythonPath]]\Python39\lib\site-packages\stanza\utils\datasets\prepare_tokenizer_treebank.py UD_Spanish-AnCora
Preparing data for UD_Spanish-AnCora: es_ancora, es
Traceback (most recent call last):
File "[[PythonPath]]\Python39\lib\runpy.py", line 197, in _run_module_as_main
return _run_code(code, main_globals, None,
File "[[PythonPath]]\Python39\lib\runpy.py", line 87, in _run_code
exec(code, run_globals)
File "[[PythonPath]]\Python39\lib\site-packages\stanza\utils\datasets\prepare_tokenizer_treebank.py", line 1136, in
In Linux:
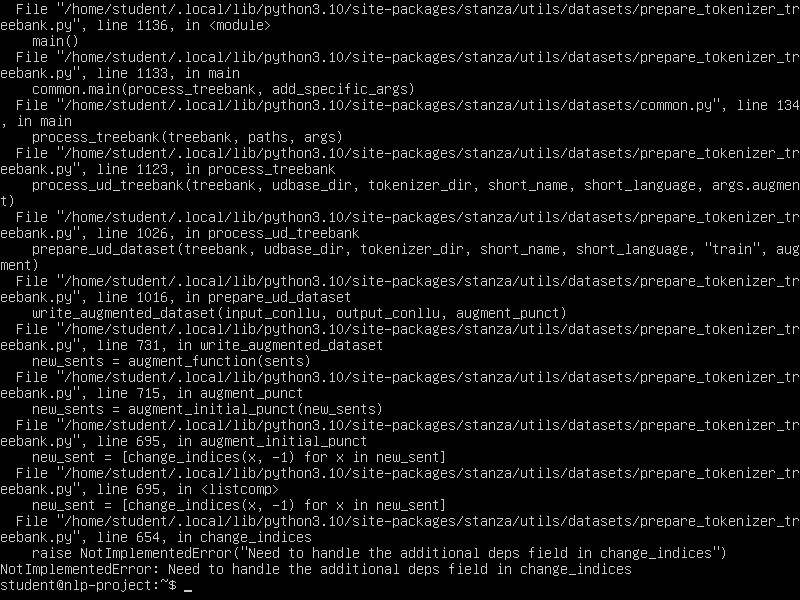
The Linux error fixed on the dev branch. Please use that. The Windows error is fixable, but then there's another error regarding unicode errors, plus you need perl installed for a later tool which hasn't been converted yet, so it's a bit of a hassle.
We are planning a new release, but there's always another last minute thing to do...
In general you can post text with ``` rather than pasting images
Thanks for advising about perl, and sorry for lacking a better way of copying from the Linux machine.
This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
not stale - will leave it open as a reminder to one day get rid of the perl dependency