Problem when adding a new language
Hi all!
First time posting a question, feel free to correct me if I'm not following conventions. I'm a Python newbie trying to start an NLP project, so all help is welcome!
I'm trying to add a new language (Old English) to Stanza, to train a model to automatically annotate OE texts. My data is converted into the corresponding format, I have word2vec word vectors, and I have a tokenized raw text file according to the documentation (https://stanfordnlp.github.io/stanza/new_language.html#data-format). My main issue is that the documentation is not clear for me. The case example used to explain how to add new languages to Stanza, and more concretely the section CharacterLM, assumes that the user is going to use data either from Wikipedia or from conll17 or OSCAR, so the terminal commands examples are fitting those scenarios. As my data is from other source, I'm using this command python3 -m stanza.utils.charlm.make_lm_data extern_data/charlm_raw extern_data/charlm from the third bulletpoint, giving my source directory and target directory.
This is where my problem starts, when I enter the command in the terminal, the following error appears:
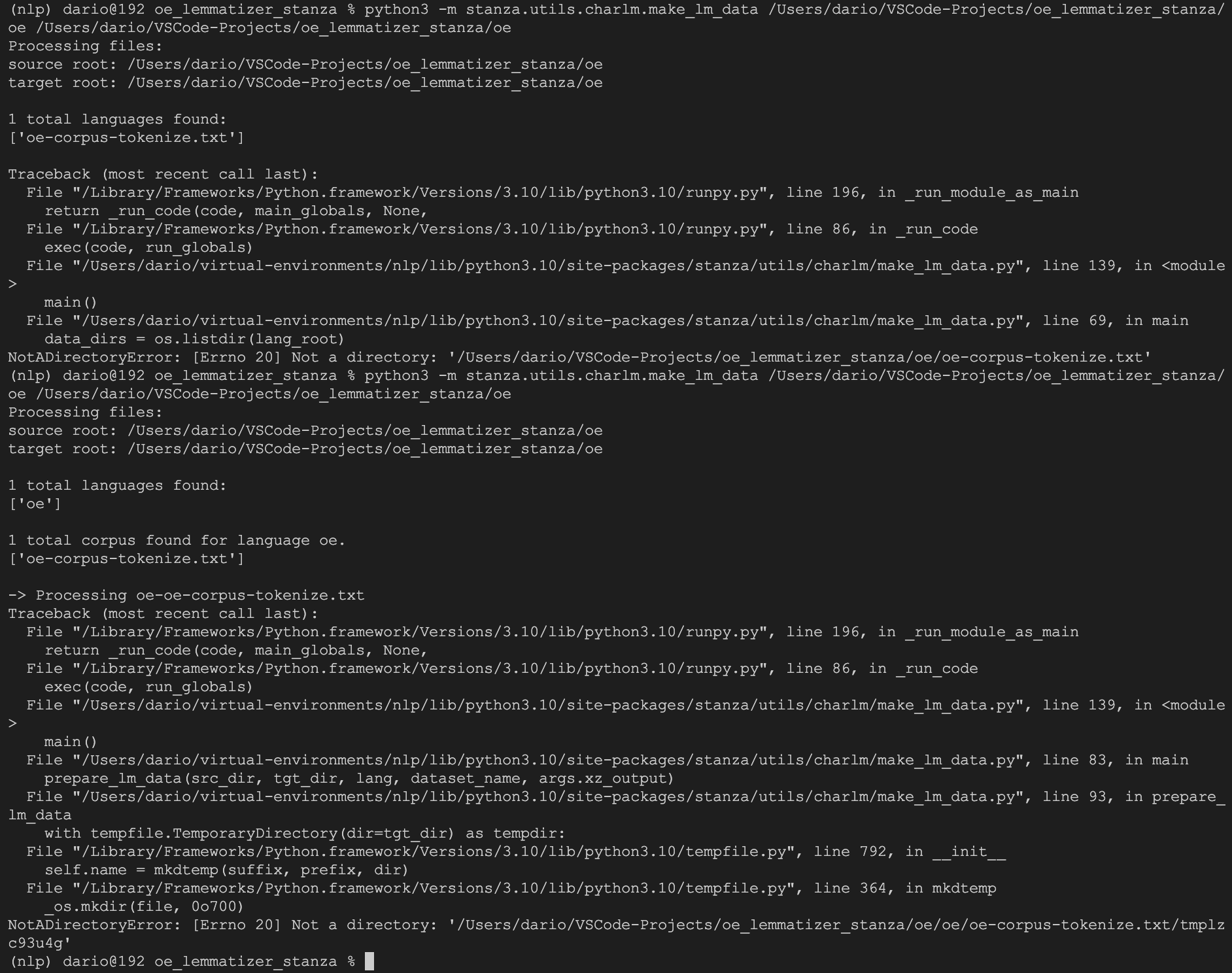
The command automatically looks for a language, although the language parameter is optional in the command. It also appears that the command tries to create the target directory, although the target directory parameter is not optional for the command, and then the error NotADirectoryError appears.
Is there anything that I'm doing wrong that prevents me from progressing in this project? Any thoughts on how I can solve this problem? I have tried looking for info in the published issues in this repo and on the internet, but I haven't found any extra info about how to add new languages.
Thanks for your help, and sorry for the long post!
Can we back up a moment? The tokenizer and lemmatizers don't actually use the pretrained charlm. The sentiment, NER, and constituency parsers do. Are you using one of those annotators?
Long post is fine, but generally speaking I prefer text instead of images for text based errors.
I have attempted to clarify the documentation on when it is appropriate to use a charlm. Furthermore, the dev branch now includes less confusing documentation on those flags, along with ignoring files that are not directories in the locations expected for lang/package.
On Fri, Jun 24, 2022 at 10:32 AM John Bauer @.***> wrote:
Can we back up a moment? The tokenizer and lemmatizers don't actually use the pretrained charlm. The sentiment, NER, and constituency parsers do. Are you using one of those annotators?
Long post is fine, but generally speaking I prefer text instead of images for text based errors.
Thanks for the clarification! I'm not using sentiment, NER or constituency parsers, but ideally, I will be using dependency parsers. From what I can understand from your answer, I guess that I will not need to use a charlm for the dependency parsing, am I right?
Thanks for your help!
Correct
On Sat, Jun 25, 2022, 2:32 AM Dario Metola Rodriguez < @.***> wrote:
Thanks for the clarification! I'm not using sentiment, NER or constituency parsers, but ideally, I will be using dependency parsers. From what I can understand from your answer, I guess that I will not need to use a charlm for the dependency parsing, am I right?
Thanks for your help!
— Reply to this email directly, view it on GitHub https://github.com/stanfordnlp/stanza/issues/1057#issuecomment-1166240735, or unsubscribe https://github.com/notifications/unsubscribe-auth/AA2AYWLCT6QQKUOZ3ZBUKTTVQ3G3PANCNFSM5ZXH64UA . You are receiving this because you commented.Message ID: @.***>
@AngledLuffa I'm also facing the same issue, ISSUE: python3 -m stanza.utils.charlm.make_lm_data extern_data/charlm_raw extern_data/charlm Processing files: source root: extern_data/charlm_raw target root: extern_data/charlm
1 total languages found: ['SINDHIDATA.txt.xz']
Traceback (most recent call last):
File "/usr/lib/python3.10/runpy.py", line 196, in _run_module_as_main
return _run_code(code, main_globals, None,
File "/usr/lib/python3.10/runpy.py", line 86, in _run_code
exec(code, run_globals)
File "/home/msi/.local/lib/python3.10/site-packages/stanza/utils/charlm/make_lm_data.py", line 139, in
although all i've putted all files is exact directories but it still gives me this 'Not a directory' error.
Hopefully addressed here:
https://github.com/stanfordnlp/stanza/issues/1075
This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.