[MEMORY] Strings de-duplication in lexicons etc.
NERFeatureFactory has a lexicon Map<String,String> containing ~500k entries.
The values (wordClass) seem to be integer numbers in String form. Switching to Integer would help a bit with loss of generality, but de-duplicating the wordClass strings would help a lot, since there are only few word classes, but 500k copies of their string name.
Distsim.lexicon has the same issue
values in that map are strings of small integer numbers.
A similar thing happens in Dictionaries.genderNumber. It is a Map [String] -> GenderEnum.
In the string-sequence keys there are many "!" (100s of k) as duplicate String instances.
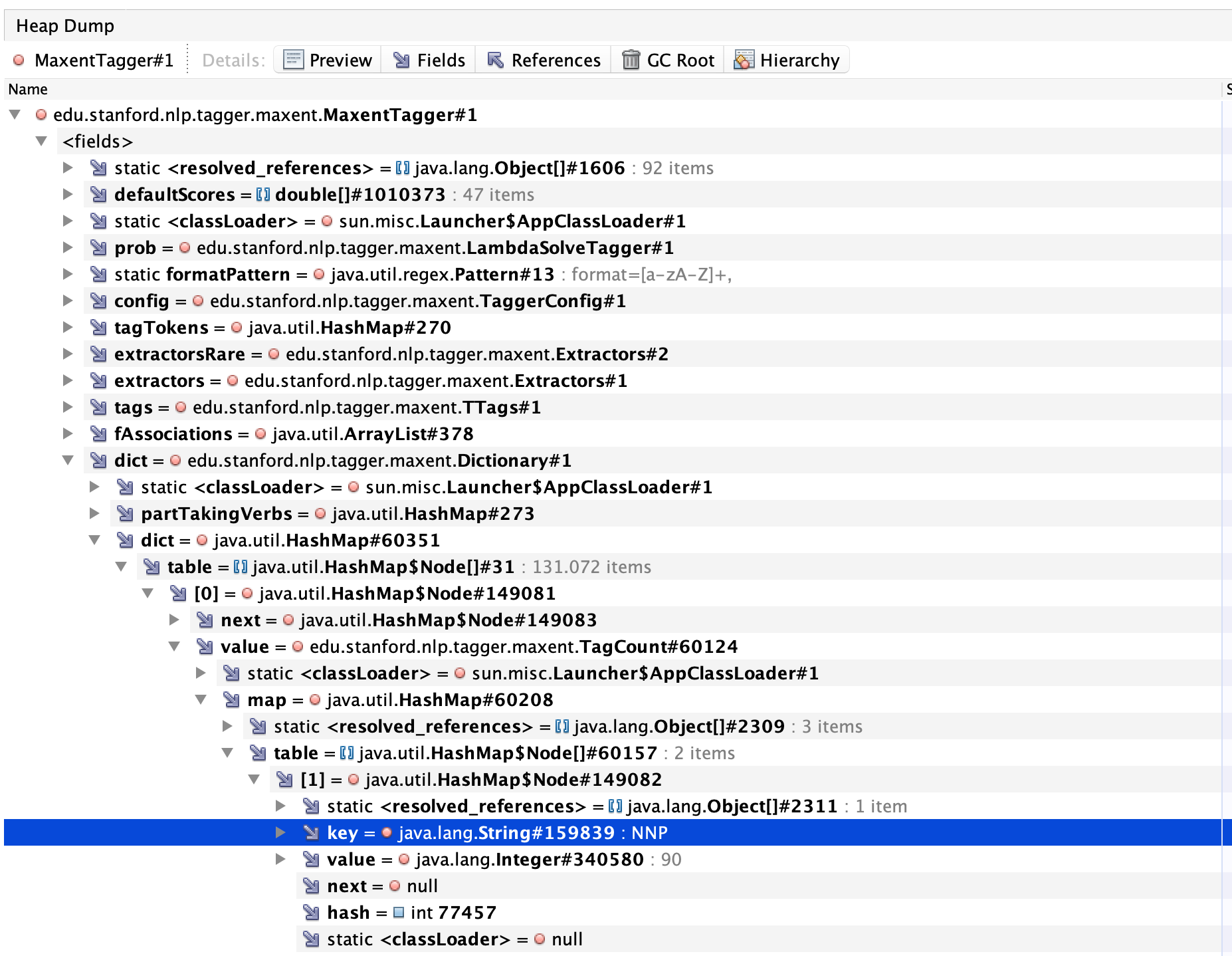
MaxentTagger.dict has many TagCount instances with repetitive keys and values.
There are JVM internal optimizations that de-duplicate strings, but the JVM chooses if and when to apply them.
- JEP192 GC based string-dedup https://openjdk.java.net/jeps/192
- JEP254 latin1 string optimization, using 1 byte instead of 2byte char arrays for strings. https://openjdk.java.net/jeps/254
I'm not sure if these are enabled by default and relying on users to enable them makes deployment rather annoying. Also these features kick in only after the models are loaded and a few GC cycles have run, so peak heap usage stays the same.
String.intern() is a bit crude as it invokes magic, just using some corenlp string pooling singleton would be a good choise, also making the behavior configurable. See https://shipilev.net/jvm/anatomy-quarks/10-string-intern/
Starting the JVM with -XX:+UseG1GC -XX:+UseStringDeduplication -Xlog:stringdedup*=debug leads to the following debug output of the G1GC string deduplication:
[163.650s][info ][gc,stringdedup] Concurrent String Deduplication (163.650s)
[163.650s][info ][gc,stringdedup] Concurrent String Deduplication 232.0B->0.0B(232.0B) avg 45.6% (163.650s, 163.650s) 0.040ms
[163.650s][debug][gc,stringdedup] Last Exec: 0.040ms, Idle: 5652.364ms, Blocked: 0/0.000ms
[163.650s][debug][gc,stringdedup] Inspected: 7
[163.650s][debug][gc,stringdedup] Skipped: 0( 0.0%)
[163.650s][debug][gc,stringdedup] Hashed: 3( 42.9%)
[163.650s][debug][gc,stringdedup] Known: 1( 14.3%)
[163.650s][debug][gc,stringdedup] New: 6( 85.7%) 232.0B
[163.650s][debug][gc,stringdedup] Deduplicated: 6(100.0%) 232.0B(100.0%)
[163.650s][debug][gc,stringdedup] Young: 0( 0.0%) 0.0B( 0.0%)
[163.650s][debug][gc,stringdedup] Old: 6(100.0%) 232.0B(100.0%)
[163.650s][debug][gc,stringdedup] Total Exec: 52/12090.851ms, Idle: 52/149051.517ms, Blocked: 31/35.861ms
[163.650s][debug][gc,stringdedup] Inspected: 14327231
[163.650s][debug][gc,stringdedup] Skipped: 0( 0.0%)
[163.650s][debug][gc,stringdedup] Hashed: 2145075( 15.0%)
[163.650s][debug][gc,stringdedup] Known: 19785( 0.1%)
[163.650s][debug][gc,stringdedup] New: 14307446( 99.9%) 416.8M
[163.650s][debug][gc,stringdedup] Deduplicated: 7783929( 54.4%) 190.1M( 45.6%)
[163.650s][debug][gc,stringdedup] Young: 1( 0.0%) 24.0B( 0.0%)
[163.650s][debug][gc,stringdedup] Old: 7783928(100.0%) 190.1M(100.0%)
[163.650s][debug][gc,stringdedup] Table
[163.650s][debug][gc,stringdedup] Memory Usage: 82.4M
[163.650s][debug][gc,stringdedup] Size: 2097152, Min: 1024, Max: 16777216
[163.650s][debug][gc,stringdedup] Entries: 2482216, Load: 118.4%, Cached: 418485, Added: 6540855, Removed: 4058639
[163.650s][debug][gc,stringdedup] Resize Count: 13, Shrink Threshold: 1398101(66.7%), Grow Threshold: 4194304(200.0%)
[163.650s][debug][gc,stringdedup] Rehash Count: 0, Rehash Threshold: 120, Hash Seed: 0x0
[163.650s][debug][gc,stringdedup] Age Threshold: 3
[163.650s][debug][gc,stringdedup] Queue
[163.650s][debug][gc,stringdedup] Dropped: 0
Process finished with exit code 130 (interrupted by signal 2: SIGINT)
Showing that around half (190MiB) can be removed with deduplication.
Deduplicated: 7783929( 54.4%) 190.1M( 45.6%)
Are these deduplicated strings mostly found in the Tagger & NER, or is this overall? We're trying to finalize a new release in the next couple of weeks, and there's still room to get small changes which save memory into that release. Ones which rely on retraining the models are almost definitely not happening, so testing the conversion of doubles to floats will have to wait, for example.
On Fri, Feb 28, 2020 at 12:31 PM lambdaupb [email protected] wrote:
Starting the JVM with -XX:+UseG1GC -XX:+UseStringDeduplication -Xlog:stringdedup*=debug leads to the following debug output of the G1GC string deduplication:
[163.650s][info ][gc,stringdedup] Concurrent String Deduplication (163.650s) [163.650s][info ][gc,stringdedup] Concurrent String Deduplication 232.0B->0.0B(232.0B) avg 45.6% (163.650s, 163.650s) 0.040ms [163.650s][debug][gc,stringdedup] Last Exec: 0.040ms, Idle: 5652.364ms, Blocked: 0/0.000ms [163.650s][debug][gc,stringdedup] Inspected: 7 [163.650s][debug][gc,stringdedup] Skipped: 0( 0.0%) [163.650s][debug][gc,stringdedup] Hashed: 3( 42.9%) [163.650s][debug][gc,stringdedup] Known: 1( 14.3%) [163.650s][debug][gc,stringdedup] New: 6( 85.7%) 232.0B [163.650s][debug][gc,stringdedup] Deduplicated: 6(100.0%) 232.0B(100.0%) [163.650s][debug][gc,stringdedup] Young: 0( 0.0%) 0.0B( 0.0%) [163.650s][debug][gc,stringdedup] Old: 6(100.0%) 232.0B(100.0%) [163.650s][debug][gc,stringdedup] Total Exec: 52/12090.851ms, Idle: 52/149051.517ms, Blocked: 31/35.861ms [163.650s][debug][gc,stringdedup] Inspected: 14327231 [163.650s][debug][gc,stringdedup] Skipped: 0( 0.0%) [163.650s][debug][gc,stringdedup] Hashed: 2145075( 15.0%) [163.650s][debug][gc,stringdedup] Known: 19785( 0.1%) [163.650s][debug][gc,stringdedup] New: 14307446( 99.9%) 416.8M [163.650s][debug][gc,stringdedup] Deduplicated: 7783929( 54.4%) 190.1M( 45.6%) [163.650s][debug][gc,stringdedup] Young: 1( 0.0%) 24.0B( 0.0%) [163.650s][debug][gc,stringdedup] Old: 7783928(100.0%) 190.1M(100.0%) [163.650s][debug][gc,stringdedup] Table [163.650s][debug][gc,stringdedup] Memory Usage: 82.4M [163.650s][debug][gc,stringdedup] Size: 2097152, Min: 1024, Max: 16777216 [163.650s][debug][gc,stringdedup] Entries: 2482216, Load: 118.4%, Cached: 418485, Added: 6540855, Removed: 4058639 [163.650s][debug][gc,stringdedup] Resize Count: 13, Shrink Threshold: 1398101(66.7%), Grow Threshold: 4194304(200.0%) [163.650s][debug][gc,stringdedup] Rehash Count: 0, Rehash Threshold: 120, Hash Seed: 0x0 [163.650s][debug][gc,stringdedup] Age Threshold: 3 [163.650s][debug][gc,stringdedup] Queue [163.650s][debug][gc,stringdedup] Dropped: 0
Process finished with exit code 130 (interrupted by signal 2: SIGINT)
Showing that around half (190MiB) can be removed with deduplication. Deduplicated: 7783929( 54.4%) 190.1M( 45.6%)
— You are receiving this because you are subscribed to this thread. Reply to this email directly, view it on GitHub https://github.com/stanfordnlp/CoreNLP/issues/1004?email_source=notifications&email_token=AA2AYWPOEZ67VUTZF7TCC4DRFFYBBA5CNFSM4K5SBRKKYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOENKBY6Y#issuecomment-592714875, or unsubscribe https://github.com/notifications/unsubscribe-auth/AA2AYWKPTUX4Z4EEKSOLNE3RFFYBBANCNFSM4K5SBRKA .
This is overall with just a loaded pipeline.
tokenize,ssplit,pos,lemma,ner,depparse,coref,quote
The issue description I think covers most of the duplicates.
It should be possible to catch most of it doing some sort of dedup before inserting strings into the data structures.
Like here in Dictionaries.loadGenderNumber:
String[] words = split[0].split(" ");
// FIXME: pool strings in list
List<String> tokens = Arrays.asList(words);
genderNumber.put(tokens, gender);
or in NERFeatureFactory.initLexicon:
// FIXME: string pool both
lexicon.put(word, wordClass);
or possibly post-processed if it is de-serialized when using the model.
Distsim.lexicon and NERFeatureFactory.lexicon seem to be deserialized and so deduplication needs to be injected with a magic deserialize method.
private void readObject(java.io.ObjectInputStream in) throws IOException, ClassNotFoundException {
in.defaultReadObject();
StringDedup.INST.dedupInplace(lexicon);
}
Interesting. I'll take a look.
There is already an Interner class in e.s.n.util.Interner, btw
Do you have any insight into whether the CollectionValuedMap changes had the desired effect? It would be disappointing if not
056c413b2468ce6937dfa6aeb4ae03235e5fa09a comes out at 3243MB, so 82MB improvement.
Its quick to measure though, Just download https://visualvm.github.io/ and the pipeline setup + sleep main.
Hopefully you mean using all the code at 056c413, not just cherrypicking, since that particular change was just a refactoring to set up a tagger change. Thanks for checking!
My current workflow has been to make the changes over ssh as our test suite uses data files on our cluster, so the link is appreciated but will not be immediately useful.
Yeah, just the master branch in this repo at 056c413.
I just put the models jar manually into the project in intellij and start my main class in the IDE.
What I just did instead is output the result of SystemUtils.getMemoryInUse()
That should work great as well. But be sure to call System.gc() a few times.
If the goal is to avoid peak memory usage, interning the lexicon after loading it might not help
However, creating the lexicon with interned strings should do it, right? Just not this time around... would only help the next time we retrain & reserialize the models. I suppose it would also be possible to run a conversion program which loads a model, interns the strings in the lexicon, and then saves that. Might be significantly smaller, too
That seems to work exactly as I had hoped (although the models don't get smaller on disk, sadly)
Well, it accounts for around 300MB extra total, and the models are loaded sequentially. I think it would still achieve lower peak usage.
Deduplicating the strings before serializing is probably 80%, but the overlap between other models stays duplicated.
Dedup before serializing is quite a large fraction of the gain, and I'm a little adverse to changing the readObject method because of how confusing it becomes for people working on the code later (including myself).
It is very magical.
I don't know how much java serialization is used in this project in general, but replacing it with more boring solutions might be advisable in the mid-term. It is one of the more regretted features of the java platform and brings a lot of weird issues with it.
Lots, for better or worse.
It does make people's lives easier in the short term, especially when you can wrap it into a single function call as we have for several of the models. Doing so makes it rather difficult to customize it, though.