Why are declarations and allocations done on different lines in write_array?
I'm looking at code like the below for write_array, log_prob, and other places we do FnReadParam
// ex in log_prob
stan::io::reader<local_scalar_t__> in__(params_r__, params_i__);
//...
Eigen::Matrix<local_scalar_t__, -1, -1> VV;
VV = Eigen::Matrix<local_scalar_t__, -1, -1>(N, M);
current_statement__ = 1;
VV = in__.matrix(N, M);
Is there a reason why this is not just
Eigen::Matrix<double, -1, -1> VV = in__.matrix(N, M);
This would probably be a lot easier for the C++ compiler to optimize. For example see the godbolt link below with the example assembly output for both versions above
https://godbolt.org/z/3yqJfN (gcc) https://godbolt.org/z/KawadE (clang)
The assembly for the way things are done now (top view, left part of diff view) has a lot more stuff than the simpler method (bottom view, right part of diff view). The current method also has to do an extra allocation and deletion.
I tried parsing out how to do the simpler method but I got lost at pp_compiler_internal_fn where the compiler does
| Some FnReadParam -> (
match es with
| {Expr.Fixed.pattern= Lit (Str, base_type); _} :: dims ->
pf ppf "@[<hov 2>in__.%s(@,%a)@]" base_type (list ~sep:comma pp_expr)
dims
For the VV = in__.matrix(N, M);, but couldn't find where the original declaration and initialization is for
Eigen::Matrix<double, -1, -1> VV;
VV = Eigen::Matrix<double>(N, M);
Any pointers on where to look?
And it looks like the sequence for reading in a parameter is in Transform_Mir.ml, where decl is the Decl constructor (that's turned into the declaration and assignment later in Statement_gen) and bodyfn is the FnReadParam that generates the in__ code. I guess you'd need to combine these to prevent the extra initialization?
Going to try tmrw to see how to combine these tomorrow.
@bob-carpenter with the way it's done in the new compiler now (the one at the top with initialization, allocation, then assignment all in 3 seperate steps), if that is assigning a matrix of vars would it call the stack allocator twice?
The declaration is created here: https://github.com/stan-dev/stanc3/blob/eaf1f960dba26f8f44270e7538e984d687ac625a/src/stan_math_backend/Statement_gen.ml#L58-L61
pp_set_size emits the allocation.
I'm working on array inits #493 and I can change this so it emits
Eigen::Matrix<local_scalar_t__, -1, -1> VV;
current_statement__ = 1;
VV = in__.matrix(N, M);
is that good enough?
However, we can't remove the allocation in all cases because
parameters {
vector[3] vec[3];
}
creates a loop
std::vector<Eigen::Matrix<local_scalar_t__, -1, 1>> vec;
vec = std::vector<Eigen::Matrix<local_scalar_t__, -1, 1>>(3,
Eigen::Matrix<local_scalar_t__, -1, 1>(4));
for (size_t sym1__ = 1; sym1__ <= 3; ++sym1__) {
assign(vec, cons_list(index_uni(sym1__), nil_index_list()),
in__.vector(4), "assigning variable vec");}
Also, I'm not sure what's going on here but this looks scary https://github.com/stan-dev/stanc3/blob/eaf1f960dba26f8f44270e7538e984d687ac625a/src/stan_math_backend/Statement_gen.ml#L181-L188
Eigen::Matrix<local_scalar_t__, -1, -1> VV;
current_statement__ = 1;
VV = in__.matrix(N, M);
is that good enough?
Yep that looks good!
https://godbolt.org/z/VxebJ5
and lol yeah that's a bit of a weird one
I’m curious if this actually affects performance - not currently seeing any degradation afaik. This might be a bit annoying to tackle; we don’t have any passes that act on more than one statement at a time I think. I can take a look if someone has benchmarks showing this is important.
On Fri, Apr 10, 2020 at 12:01 Steve Bronder [email protected] wrote:
Eigen::Matrix<local_scalar_t__, -1, -1> VV; current_statement__ = 1; VV = in__.matrix(N, M);
is that good enough?
Yep that looks good!
https://godbolt.org/z/VxebJ5
and lol yeah that's a bit of a weird one
— You are receiving this because you are subscribed to this thread. Reply to this email directly, view it on GitHub https://github.com/stan-dev/stanc3/issues/503#issuecomment-612095720, or unsubscribe https://github.com/notifications/unsubscribe-auth/AAGET3BRVHWGSY5BI2DQHA3RL47E7ANCNFSM4MFCAW2A .
I have a benchmark here you can make and run with
make init_test.o && make init_test && ./init_test
# multiple reps
./init_test --benchmark_repetitions=30 --benchmark_report_aggregates_only=true
I think this captures what we are trying to test, i.e. initializing a vector of vars and doubles with the current and proposed method. I'm bad at plotting performance benchmarks so data and graph code are here
This is a graph of the current way vs. the proposed with the benchmark code above. I'm not sure why the initial one is down but it seems like there are gains 2 be made by using the proposed method I use above.
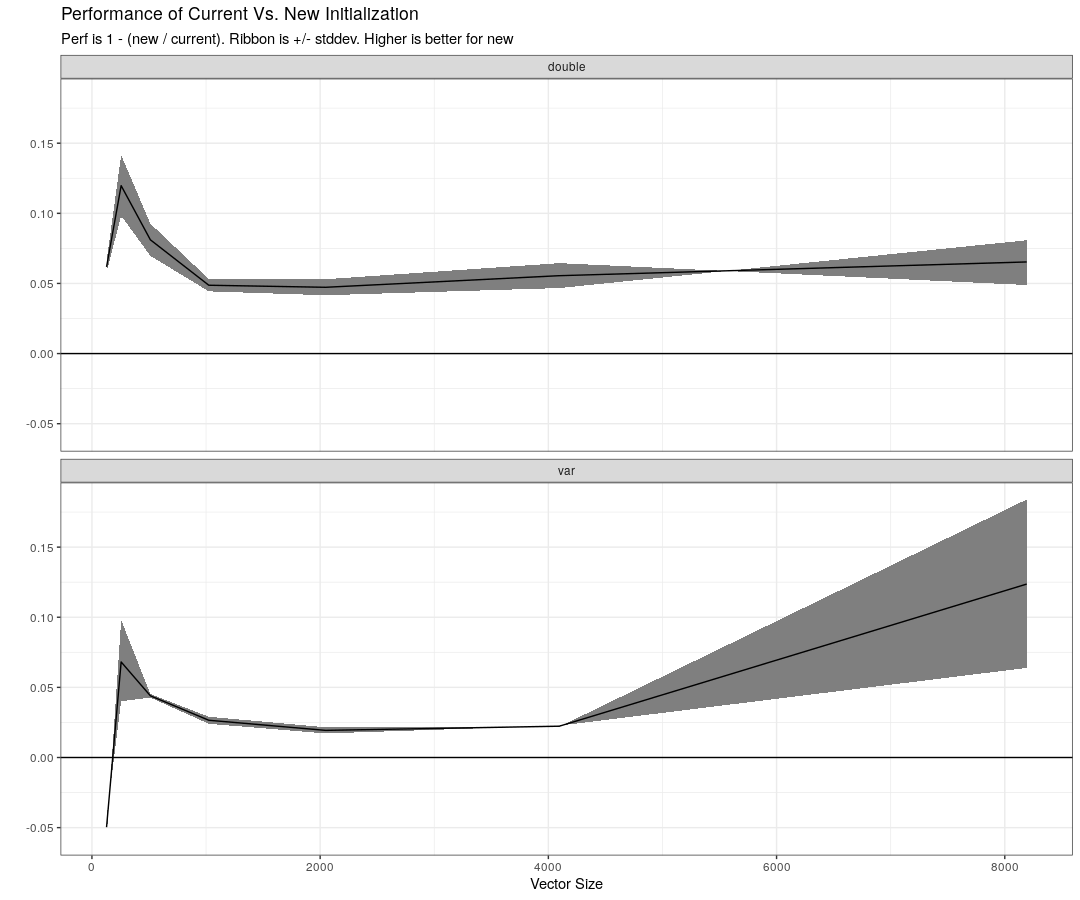
Thanks for the benchmarks! Those seem to be for std::vector and doing something a bit different than the Eigen stuff up thread... but either way, it looks like @nhuurre has a solution that doesn't need the more complicated thing I was talking about before anyway. Thanks :)
For run times, I like plotting
-
(new / old) vs. size with a log10 scale and natural unit labels on the y axis
-
using medians and quantiles like 80% instead of means and std deviation
That is, y axis markings are 0.01, 0.1, 1, 10, 100, with 1 being taking the same amount of time and lower being better. Markings base 2 also make sense: 1/8, 1/4, 1/2, 1, 2, 4, 8. The labels stay in natural units of speed ratio, not log units (don't transform data, transform y-axis using scale_y_log10 or whatever it is in ggplot).
Reversing the ratio to old / new gives units of speedup, so that 10 means 10 times as fast and 1 means equally fast.
What's the motivation for -(1 - new / old)?
It also seems like for var there is a slowdown up to a certain size.