Lightweighting_Cookbook
 Lightweighting_Cookbook copied to clipboard
Lightweighting_Cookbook copied to clipboard
This project attempts to build neural network training and lightweighting cookbook including three kinds of lightweighting solutions, i.e., knowledge distillation, filter pruning, and quantization.
Training and Lightweighting Cookbook in JAX/FLAX

Introduction
- This project attempts to build neural network training and lightweighting cookbook including three kinds of lightweighting solutions, i.e., knowledge distillation, filter pruning, and quantization.
- It will be a quite long term project, so please get patient and keep watching this repository 🤗.
Requirements
- jax
- flax
- tensorflow ( to download CIFAR dataset )
Key features
Knowledge distillation | Filter pruning
Basic training framework in JAX/FLAX
How to use
- Move to the codebase.
- Train and evaluate our model by the below command.
# ResNet-56 on CIFAR10
python train.py --gpu_id 0 --arch ResNet-56 --dataset CIFAR10 --train_path ~/test
python test.py --gpu_id 0 --arch ResNet-56 --dataset CIFAR10 --trained_param pretrained/res56_c10
Experimental comparison with other common deep learning libraries, i.e., Tensorflow2 and Pytorch
-
Hardware: GTX 1080ti
-
Tensorflow implementation [link]
-
Pytorch implementation [link]
-
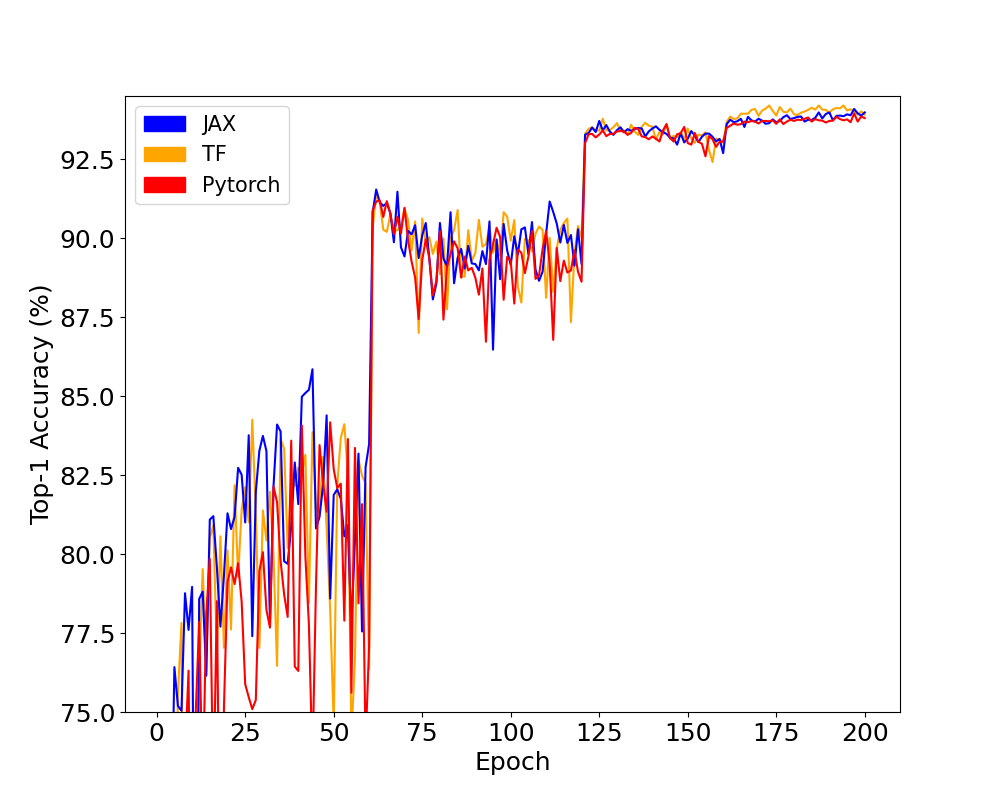
In order to check only training time except for model and data preparation, training time is calculated from the second to the last epoch.
-
Note that Accuracy on CIFAR dataset has a quite large variance
so that you should focus on another metrics, i.e., training time. -
As you can notice, JAX and TF are much faster than Pytorch because of JIT compiling.
- JIT compiling anlyzes computational graphs and cuts-off the meaningless memory allocations.
- It means that your PyTorch codes utilize GPU 100%, but parts of them are meaningless for actual training.
| Library | Accuracy | Time (m) |
|---|---|---|
| JAX | 93.98 | 54 |
| TF | 93.91 | 53 |
| Pytorch | 93.80 | 69 |

TO DO
-
[x] Basic training and test framework
- [x] Dataprovider in JAX
- [x] Naive training framework
- [x] Monitoring by Tensorboard
- [x] Profiling addons
- [ ] Enlarge model zoo including HuggingFace pre-trained models
-
[ ] Knowledge distillation framework
- [x] Basic framework
- [x] Off-line distillation
- [x] On-line distillation
- [ ] Self distillation
- [ ] Enlarge the distillation algorithm zoo
-
[ ] Filter pruning framework
- [x] Basic framework
- [x] Criterion-based pruning
- [ ] Search-based pruning
- [ ] Enlarge filter pruning algorithm zoo
-
[ ] Quantization framework
- [ ] Basic framework
- [ ] Quantization aware training
- [ ] Post Training Quantization
- [ ] Enlarge quantization algorithm zoo
-
[ ] Tools for handy usage.
Acknowledgement
- Google ML Ecosystem team supported this work by providing Google Cloud Credit.

Metadata
Owner
Metadata
This project attempts to build neural network training and lightweighting cookbook including three kinds of lightweighting solutions, i.e., knowledge distillation, filter pruning, and quantization.