spyder
 spyder copied to clipboard
spyder copied to clipboard
Possible speed improvement using charset_normalizer instead of chardet
Issue Report Checklist
- [X] Searched the issues page for similar reports
- [ ] Read the relevant sections of the Spyder Troubleshooting Guide and followed its advice
- [ ] Reproduced the issue after updating with
conda update spyder(orpip, if not using Anaconda) - [ ] Could not reproduce inside
jupyter qtconsole(if console-related) - [ ] Tried basic troubleshooting (if a bug/error)
- [ ] Restarted Spyder
- [ ] Reset preferences with
spyder --reset - [ ] Reinstalled the latest version of Anaconda
- [ ] Tried the other applicable steps from the Troubleshooting Guide
- [ ] Completed the Problem Description, Steps to Reproduce and Version sections below
Problem Description
Encoding detection can be improved using charset_normalizer instead of chardet. We used chardet in our development which was changed later to cchardet - a C implementation for speed, but it does not work for py39+.
The one mentioned seems a reasonable substitution and may Spyder could benefit from this too.
https://github.com/Ousret/charset_normalizer
Thanks
Hi @dpizetta , thanks for the suggestion! What do you think @spyder-ide/core-developers ?
Seems like a pretty solid win in pretty much all major areas—performance, features, and accuracy—at least per their own (potentially not totally impartial) benchmarks. Aside from the modest work needed to migrate to it, the only other major concern is long-term sustainability, maintainability and bus factor, as it is under a personal account rather than an org and doesn't have quite as wide an existing contributor base or other stats. But it seems a lot of other core projects use it, at least anecdotally—I see it get installed into many/most Conda envs I create, even just with packages low in the stack.
This is an interesting idea, thanks @dpizetta for bringing it up! Do you have time to help us migrating to charset_normalizer?
Hey guys, thanks. I'll check the efforts and return to you, I think I can do it even not having too much time available at this point.
Hi, I take a look and I think the changes only applies to this function, because all other calls use this get_encoding.
https://github.com/spyder-ide/spyder/blob/7df1cee1182a992c84c83350a5a87c36deacc19a/spyder/utils/encoding.py#L112-L145
I make some tests, but there are some scenarios:
- when not forcing char detect, it parses the "coding" from text, but for this you should know the encoding too, this is commented in the line 123;
- if its reading like binary, in most of the cases inside the program, it uses the
chardetlibrary, but it only takes into account the first two lines of the file, so usingchardetin this case it uses the same amount of time (about 0.0003s) ascharset_normalizer. The problem is that using just two lines can give you the wrong encoding. (You can simple use common chars in the first two lines and encoding-specific chars in the other ones, it gives you ascii, but it is actually utf-8); - using
chardetto check the whole file it will critically depends on the file size (for a 500 line files ~0.0150s, for a 50 line files ~0.0025s). However using the charset_normalizer (for a 500 line files ~0.0030s, for a 50 line files ~0.0010s)
So if we just see the time spent, using the current behavior, both have about the same time. We can improve the quality of this analysis checking the whole file using charset_normalizer, but this will increase time a bit. Event for the first case, ideally you need to guess the encoding before use the "encoding" string to confirm if they are compatible, so ideally in all cases we should use the detector. Of course, most of the files today will rely on ascii/utf-8 encoding, so this test cannot be so useful.
Let me know your ideas about it, thanks :)
when not forcing char detect, it parses the "coding" from text, but for this you should know the encoding too, this is commented in the line 123;
Actually, as far as I can tell, I believe that comment is not actually correct (or at least up to date), so long as text is any str or bytes object, or any object with a working __str__ dunder method. Instead of trying to decode, to_text_string just calls str() to return the naive string representation of the object, which if bytes is just the repr of the relevant bytes, with any ASCII printable values displayed as such. Therefore, as no decoding is done (unless this is called with a custom object, and its __str__ object explicitly specifies such, which seems extremely unlikely), UnicodeDecodeError can never trigger here.
Furthermore, given we know the coding declaration itself is composed only of ASCII-printable characters, so long as it exists in some form on that line, it will still be successfully parsed even if that line somehow also contains other non-ASCII characters (unless bytes are passed which are in an encoding that is non-ASCII-compatible and does not have the alphanumeric characters at the same code points as ASCII—which is basically just UTF-16, virtually never used for text files).
We can improve the quality of this analysis checking the whole file using charset_normalizer, but this will increase time a bit.
As this only is a modest increase even for very long files, this seems reasonable. Perhaps it could be capped at the first ≈1000 lines, to avoid poor scaling on very large files.
Event for the first case, ideally you need to guess the encoding before use the "encoding" string to confirm if they are compatible, so ideally in all cases we should use the detector.
Actually, I don't believe that's necessary per my testing above above—the block will never actually error, and the only way a valid coding declaration wouldn't be detected is if the file is in a completely ASCII-incompatible encoding, which is basically just UTF-16 (which is essentially never used for text files)—and UTF-16/32 is trivial for any encoding detection to unambiguously and automatically detect, due to the mandatory presence of the BOM.
Of course, most of the files today will rely on ascii/utf-8 encoding, so this test cannot be so useful.
To note, per PEP 3120 any Python source files must be UTF-8 by default if they lack a coding declaration, so Spyder should immediately assume UTF-8 for any Python file for which the coding check fails to find a result rather than guessing, as that is the encoding with which the file will be read by the Python interpreter (Python 2 defaulted to ASCII only, of which UTF-8 is a superset, and will error for any file that contains non-ASCII characters without a coding declaration).
We can improve the quality of this analysis checking the whole file using charset_normalizer, but this will increase time a bit
I agree with @CAM-Gerlach that we should use the first 1000 lines of a file for this.
Event for the first case, ideally you need to guess the encoding before use the "encoding" string to confirm if they are compatible, so ideally in all cases we should use the detector
I agree with this too.
Let me know your ideas about it, thanks :)
Thanks for taking a look at this @dpizetta! I think we kind of agree now on what needs to be done, so you can proceed with the implementation of this feature. Please do it against our master branch because this is not critical and could introduce unforeseen regressions.
Event for the first case, ideally you need to guess the encoding before use the "encoding" string to confirm if they are compatible, so ideally in all cases we should use the detector
I agree with this too.
Per my comprehensive analysis and testing above, this is actually not the case, unless I'm missing something major. To summarize, it is impossible for that line to raise a UnicodeDecodeError because it performs no encoding/decoding, it performs the regex search either on an already-Unicode string, or on the ASCII repr of bytes. Furthermore, it will always correctly detect any valid coding declaration in a file of any supported encoding (except for the extremely rarely used UTF-16, which is trivially and unambiguously detected by the fallback detection anyway due to the mandatory presence of the BOM).
Per https://github.com/spyder-ide/spyder/issues/20510#issuecomment-1459614137, this is actually not the case
Ok, sorry for the confusion, your analysis was bit hard to read. So, let's not do that.
Sorry, I should have provided a TL;DR up top as I usually do if it gets that long—it ended up being more complicated than I initially thought.
Per https://github.com/spyder-ide/spyder/issues/20510#issuecomment-1459614137, this is actually not the case, unless I'm missing something major. To summarize, it is impossible for that line to raise a UnicodeDecodeError because it performs no encoding/decoding, it performs the regex search either on an already-Unicode string, or on the ASCII repr of bytes. Furthermore, it will always correctly detect any valid coding declaration in a file of any supported encoding (except for the extremely rarely used UTF-16, which is trivially and unambiguously detected by the fallback detection anyway due to the mandatory presence of the BOM).
Ok, I agree, thanks for checking.
I agree with @CAM-Gerlach that we should use the first 1000 lines of a file for this.
We can limit from 50kB-500kB, without any problem with time, as the data input is bytes, so we avoid any extra conversions.
Another possible solution, or improvement if used together, is to use this function from_bytes instead of detect. By its defaults, it analyses just some part of the bytes by a predefined criteria for speed up, using in my tests for a 1MB file, it get more coherent value of about ~0.0040 for all cases against ~0.0090 using detect.
Other points:
If the coding is declared, will we trust in this declaration without any other test? As it is, if you not use force_chardet it just return the declared one. So, some other improvements can be to force the analysis and compare the results, trusting the analysis.
Case 1) If the declaration is ASCII and there are utf-8 chars (ç, ã, ñ), it shows UTF-8-GUESSED, but saving we got the RuntimeError in the line 199, which will open the report to be sent to Spyder Team, at least I think we can remove this RuntimeError and proceed as the other ones, I don't think this report will worth. It would be nice to alert the user that the coding is wrong, without generating the this breaking error.
https://github.com/spyder-ide/spyder/blob/7df1cee1182a992c84c83350a5a87c36deacc19a/spyder/utils/encoding.py#L176
Case 2) If the declaration is changed editing the code, it will try to use the original encoding to save not the new one declared, only if fails it will try to check the encoding again.
https://github.com/spyder-ide/spyder/blob/7df1cee1182a992c84c83350a5a87c36deacc19a/spyder/utils/encoding.py#L147
As mentioned, for Python files without declaration, we should associate as utf-8, however, without any utf-8 specific char we get the return of ASCII from the analysis (chardet or charset_normalizer), which is not a problem because it is a subset, however it will read/write as ASCII. To ensure utf-8 for python files we should test the extension for this case, so more changes should be inserted - I think we should keep like this for now.
Just for a comparison to the current VSCode behavior, it seems it ignores the encoding declared, but you can set the encoding for a specific extensions. So, Spyder wins to consider the declaration.
Another possible solution, or improvement if used together, is to use this function
from_bytesinstead ofdetect. By its defaults, it analyses just some part of the bytes by a predefined criteria for speed up, using in my tests for a 1MB file, it get more coherent value of about ~0.0040 for all cases against ~0.0090 usingdetect.
Sounds like a good idea to me :+1:
If the coding is declared, will we trust in this declaration without any other test? As it is, if you not use force_chardet it just return the declared one. So, some other improvements can be to force the analysis and compare the results, trusting the analysis.
In the general case, yes, we should follow the declaration as specified and skip analysis, because that's why it's there. However, if loading the file fails with a UnicodeDecodeError, we should at least be popping up a suitable error message, and ideally include a line in that dialog box that says something like "We've detected your file is likely encoded in <encoding> instead. Would you like Spyder to update your encoding declaration to fix this problem?" which updates the coding line with the charset_normalizer-guessed encoding. This would also handle the ASCII/UTF-8 case mentioned below.
Case 1) If the declaration is ASCII and there are utf-8 chars (ç, ã, ñ), it shows UTF-8-GUESSED, but saving we got the RuntimeError in the line 199, which will open the report to be sent to Spyder Team, at least I think we can remove this RuntimeError and proceed as the other ones, I don't think this report will worth. It would be nice to alert the user that the
codingis wrong, without generating the this breaking error.
In general, on file opening encoding errors we shouldn't report at all and instead show a helpful error message explaining the problem, because this is almost certainly something not under Spyder's control. In this case, the above approach (popping up a dialog to update the coding line) will fix the problem not only for Spyder, but also anything else (e.g. python) reading the file as well.
As mentioned, for Python files without declaration, we should associate as utf-8, however, without any utf-8 specific char we get the return of ASCII from the analysis (chardet or charset_normalizer), which is not a problem because it is a subset, however it will read/write as ASCII. To ensure utf-8 for python files we should test the extension for this case, so more changes should be inserted - I think we should keep like this for now.
The concern here is that it might be possible for the analysis to guess a non-UTF-8 encoding, depending on if the specific algorithm strictly prefers UTF-8 if the text is valid UTF-8. This might be trivial to do, or it might not depending on the specifics of the usage.
NB, not sure if charset_normalizer has the same issue, but as long as I can remember and to this day, chardet (and thus Spyder) has incorrectly treated many UTF-8 encoded Python files that have all ASCII characters except for the copyright symbol (a common situation in source code) as ISO-8859-1 (Latin-1) instead of correctly as UTF-8, and there's no way to fix it aside from including a redundant manual encoding declaration. In fact, even Spyder/QtPy's own source code, e.g. qtpy.QtGui, has this problem. Maybe charset_normalizer fixes it for these cases, but if we followed PEP 3120 instead of trying to guess for Python files, this couldn't happen in the first place.
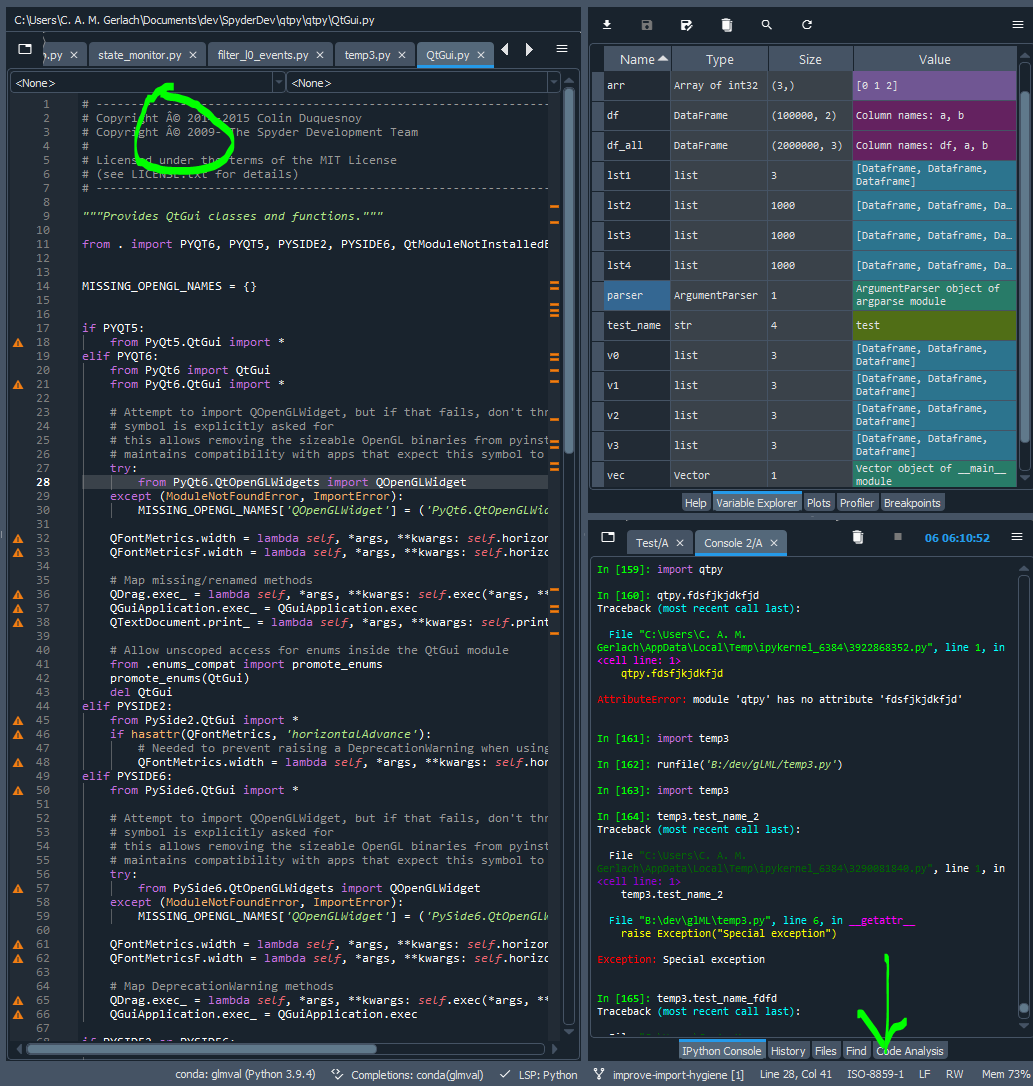
if we followed PEP 3120 instead of trying to guess for Python files, this couldn't happen in the first place.
I agree, If there is no coding, it should be treated as UTF-8 unless it is not valid UTF-8, at which point trying to guess is fine. That would be a big speed improvement as well.
Hi guys, I know I owe you the code for this, I'm moving, so I need to find some time to write it down.
We tried to switch to charset-normalizer (see PR #24654) and found that it's not reporting the right encodings for the test files we use.
So, it seems it won't be possible for us to switch to it, sorry.