Low-volume consumers regularly replay old partition offsets
We're experiencing a recurring issue with low-volume consumers (like for error topics) where the partition offset isn't being regularly ack'd back to the brokers causing the same messages to be replayed. While some offset replay is expected with higher volume topics, I don't think it should be happening with low volume ones as well.
Consider the following evidence:
Every time the canary (kafkacat-consumer) dyno restarts, it reads in a few messages. That's suspect (knowing our error message production - from other dynos - is not that even).
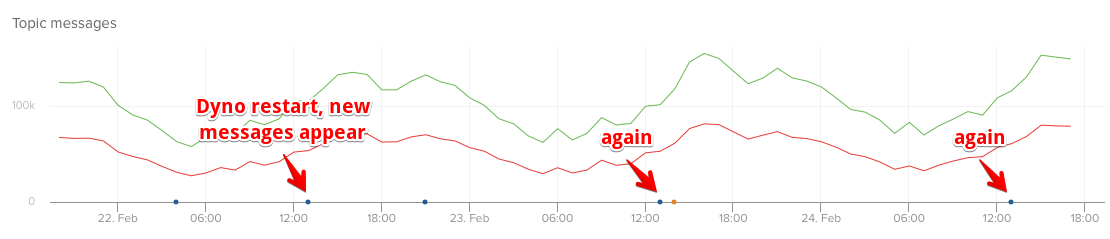
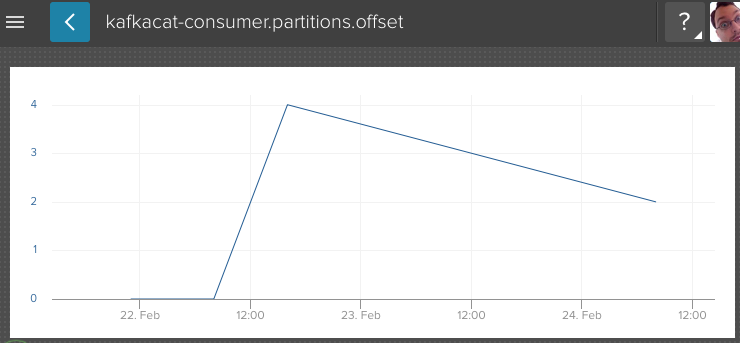
Consider also that at each of these dyno restarts, the partition offsets of the messages received by the consumer don't always increase! See partition29 as an example, where it drifts sideways for two measurements (which also should never happen), then up, then down.
This tells me that Kaffe consumers for low-volume topics don't ack back their offsets to the broker frequently enough and when they're restarted they start back on an offset that was already received. I know we've looked at this in the past, and I believe you said every 5s the partition is ack'd, but I see reason to believe that's not the case. It appears to be more volume based than anything (once very x messages?).
We should make sure low-volume consumption behaves more predictably.
Hmm, I don't see this happening locally. At least not trivially:
initial run
[elixir 1.3.4][ruby 2.3.0][dev-services]~/temp/cafe:master ✓
$ iex -S mix
Erlang/OTP 18 [erts-7.2.1] [source] [64-bit] [smp:4:4] [async-threads:10] [hipe] [kernel-poll:false]
Compiling 1 file (.ex)
Generated cafe app
Interactive Elixir (1.3.4) - press Ctrl+C to exit (type h() ENTER for help)
iex(1)>
14:40:17.814 [info] group coordinator (groupId=cafe1,memberId=,generation=0,pid=#PID<0.173.0>):
connected to group coordinator kafka:9092
14:40:17.814 [info] group coordinator (groupId=cafe1,memberId=nonode@nohost/<0.173.0>-a5ce9c46-34b7-4000-848e-1cbd66e1f986,generation=1,pid=#PID<0.173.0>):
elected=true
14:40:17.814 [info] group coordinator (groupId=cafe1,memberId=nonode@nohost/<0.173.0>-a5ce9c46-34b7-4000-848e-1cbd66e1f986,generation=1,pid=#PID<0.173.0>):
assignments received:
whitelist:
partition=0 begin_offset=undefined
14:40:17.819 [info] client :cafe1 connected to kafka:9092
5 kafka messages from a core transaction
cafe consuming whitelist topic, partition 0, offset: 417432: TijlLDkzGHwV5qmSOcga3eOUdKs
cafe consuming whitelist topic, partition 0, offset: 417433: Abkd29rx8p9mFHpBbDlNoosYq1i
cafe consuming whitelist topic, partition 0, offset: 417434: Abkd29rx8p9mFHpBbDlNoosYq1i
cafe consuming whitelist topic, partition 0, offset: 417435: Abkd29rx8p9mFHpBbDlNoosYq1i
cafe consuming whitelist topic, partition 0, offset: 417436: TijlLDkzGHwV5qmSOcga3eOUdKs
waited 5+ seconds then aborted
BREAK: (a)bort (c)ontinue (p)roc info (i)nfo (l)oaded
(v)ersion (k)ill (D)b-tables (d)istribution
a
spinning up the node again
[elixir 1.3.4][ruby 2.3.0][dev-services]~/temp/cafe:master ✓
$ iex -S mix
Erlang/OTP 18 [erts-7.2.1] [source] [64-bit] [smp:4:4] [async-threads:10] [hipe] [kernel-poll:false]
Interactive Elixir (1.3.4) - press Ctrl+C to exit (type h() ENTER for help)
iex(1)>
14:40:36.607 [info] group coordinator (groupId=cafe1,memberId=,generation=0,pid=#PID<0.142.0>):
connected to group coordinator kafka:9092
14:40:39.788 [info] group coordinator (groupId=cafe1,memberId=nonode@nohost/<0.142.0>-8579b470-acc5-4aa6-89fe-ef03f889655a,generation=2,pid=#PID<0.142.0>):
elected=true
14:40:39.788 [info] group coordinator (groupId=cafe1,memberId=nonode@nohost/<0.142.0>-8579b470-acc5-4aa6-89fe-ef03f889655a,generation=2,pid=#PID<0.142.0>):
assignments received:
whitelist:
partition=0 begin_offset=417437
14:40:39.793 [info] client :cafe1 connected to kafka:9092
5 more transactions
cafe consuming whitelist topic, partition 0, offset: 417437: UqzitnnQKoacW5fTm4QmJ1FSZvg
cafe consuming whitelist topic, partition 0, offset: 417438: 2yWwLw2YbhfIuqUhaHoZbH7P3GD
cafe consuming whitelist topic, partition 0, offset: 417439: 2yWwLw2YbhfIuqUhaHoZbH7P3GD
cafe consuming whitelist topic, partition 0, offset: 417440: 2yWwLw2YbhfIuqUhaHoZbH7P3GD
cafe consuming whitelist topic, partition 0, offset: 417441: UqzitnnQKoacW5fTm4QmJ1FSZvg
immediately quit the node and restarted
BREAK: (a)bort (c)ontinue (p)roc info (i)nfo (l)oaded
(v)ersion (k)ill (D)b-tables (d)istribution
a
[elixir 1.3.4][ruby 2.3.0][dev-services]~/temp/cafe:master ✓
$ iex -S mix
Erlang/OTP 18 [erts-7.2.1] [source] [64-bit] [smp:4:4] [async-threads:10] [hipe] [kernel-poll:false]
Interactive Elixir (1.3.4) - press Ctrl+C to exit (type h() ENTER for help)
iex(1)>
14:40:51.948 [info] group coordinator (groupId=cafe1,memberId=,generation=0,pid=#PID<0.142.0>):
connected to group coordinator kafka:9092
14:40:55.804 [info] group coordinator (groupId=cafe1,memberId=nonode@nohost/<0.142.0>-fdb69e5a-c295-482e-a03b-caa18df1d49d,generation=3,pid=#PID<0.142.0>):
elected=true
14:40:55.806 [info] group coordinator (groupId=cafe1,memberId=nonode@nohost/<0.142.0>-fdb69e5a-c295-482e-a03b-caa18df1d49d,generation=3,pid=#PID<0.142.0>):
assignments received:
whitelist:
partition=0 begin_offset=417437
14:40:55.812 [info] client :cafe1 connected to kafka:9092
the 5 previous messages are reconsumed
cafe consuming whitelist topic, partition 0, offset: 417437: UqzitnnQKoacW5fTm4QmJ1FSZvg
cafe consuming whitelist topic, partition 0, offset: 417438: 2yWwLw2YbhfIuqUhaHoZbH7P3GD
cafe consuming whitelist topic, partition 0, offset: 417439: 2yWwLw2YbhfIuqUhaHoZbH7P3GD
cafe consuming whitelist topic, partition 0, offset: 417440: 2yWwLw2YbhfIuqUhaHoZbH7P3GD
cafe consuming whitelist topic, partition 0, offset: 417441: UqzitnnQKoacW5fTm4QmJ1FSZvg
5 more messages
cafe consuming whitelist topic, partition 0, offset: 417442: 9YG8Vxau0AK0u3UVMi1Yjp9CC98
cafe consuming whitelist topic, partition 0, offset: 417443: 9Wfapxs8HzFfX7sYDmFgO4GjPTN
cafe consuming whitelist topic, partition 0, offset: 417444: 9Wfapxs8HzFfX7sYDmFgO4GjPTN
cafe consuming whitelist topic, partition 0, offset: 417445: 9Wfapxs8HzFfX7sYDmFgO4GjPTN
cafe consuming whitelist topic, partition 0, offset: 417446: 9YG8Vxau0AK0u3UVMi1Yjp9CC98
waited 5+ seconds then aborted/restarted
BREAK: (a)bort (c)ontinue (p)roc info (i)nfo (l)oaded
(v)ersion (k)ill (D)b-tables (d)istribution
a
[elixir 1.3.4][ruby 2.3.0][dev-services]~/temp/cafe:master ✓
$ iex -S mix
Erlang/OTP 18 [erts-7.2.1] [source] [64-bit] [smp:4:4] [async-threads:10] [hipe] [kernel-poll:false]
Interactive Elixir (1.3.4) - press Ctrl+C to exit (type h() ENTER for help)
iex(1)>
14:41:09.427 [info] group coordinator (groupId=cafe1,memberId=,generation=0,pid=#PID<0.142.0>):
connected to group coordinator kafka:9092
14:41:13.832 [info] group coordinator (groupId=cafe1,memberId=nonode@nohost/<0.142.0>-d1d1d65b-5843-4f53-90c1-a050b967e473,generation=4,pid=#PID<0.142.0>):
elected=true
14:41:13.833 [info] group coordinator (groupId=cafe1,memberId=nonode@nohost/<0.142.0>-d1d1d65b-5843-4f53-90c1-a050b967e473,generation=4,pid=#PID<0.142.0>):
assignments received:
whitelist:
partition=0 begin_offset=417447
14:41:13.838 [info] client :cafe1 connected to kafka:9092
I tried killing the node with ctrl-\ as well to immediately hard stop everything and got the same result. Less than 5 seconds and I reconsume from the offset, more than 5 seconds and the node gets the correct next offset it was waiting for.
A week a bit too far out :-D
This seems like a point? https://metrics.librato.com/s/spaces/356792?duration=473&end_time=1487944831
I don't know when that app was restarted (is that midnight to Heroku?), but it looks like all those errors consumed at that time are old. So the theory is that the app was restarted and then consumed all those errors again.
So that was about 1am GMT?
I wonder if this is an issue with having a consumer group with a lot of topics and partitions. Because the offset is committed per partition maybe things can breakdown?
Maybe. I think I've seen it to some degree in Keyster, it has two topics, each with 32 partitions.
When you dig into potential issues with the underlying client and find your own issue talking about how these things fit together 😀
https://github.com/klarna/brod/issues/127
I'm actually noticing replay of events in low volume topics now too; any advice?
@rawkode I think that will happen any time the messages in the topic that tracks the offsets (which is internal to Kafka) expires before the messages themselves.
There may be a configuration setting for this in the Kafka broker.
Alternatively, if the last offset is recommitted, I believe that refreshes it with the broker and you won't get the replay. I've not tested this, however. This would get more complicated across server restarts, of course. 😉