Is possible to run the Ztest class and multiple_difference() method for multiple experiments and events at the same time?
We are considering using Spotify confidence to report on all the experiments running on our experimentation platform. So, I did some tests by running a sample of our data (see image below) against Ztest class to see if it could be used to meet our needs of running it simultaneously for various experiments and conversion events. And my findings were as follows:
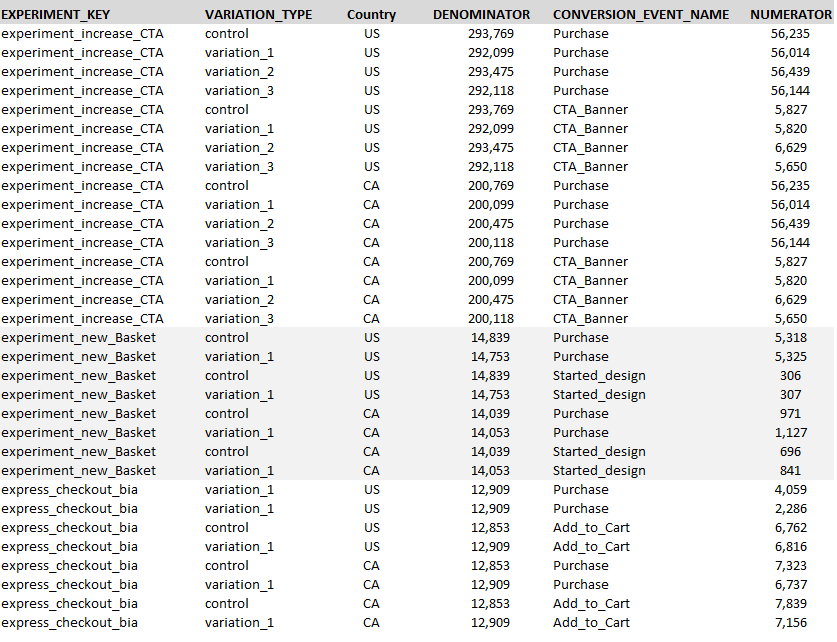
- For a Single Experiment (Variation_Type, Conversion_Event_Name)
For a single experiment with multiple metrics, the following methods, summary(), difference(), and multiple_difference(), worked correctly.
ztest_filtered = confidence.ZTest(pandasDF_filtered,
numerator_column='NUMERATOR',
numerator_sum_squares_column=None,
denominator_column='DENOMINATOR',
categorical_group_columns= ['VARIATION_TYPE','CONVERSION_EVENT_NAME'],
interval_size=0.95,
correction_method='bonferroni',
#metric_column = 'CONVERSION_EVENT_NAME',
)
ztest_filtered.summary()
ztest_filtered.difference(level_1="control", level_2="variation_1", groupby="CONVERSION_EVENT_NAME", absolute=False)
ztest_filtered.multiple_difference(level='control', groupby='CONVERSION_EVENT_NAME', level_as_reference=True)
- For a Multiple Experiments and conversion_Eevnts by making use of concatenation (Variation_Type, "Experiment_Key~Conversion_Event_Name")
Similar results to the previous one, but satisfying to see that it works perfectly for all experiments and events if we do a concatenation between the fields "Experiment_Key~Conversion_Event_Name".
ztest_concat = confidence.ZTest(pandasDF_updated,
numerator_column='NUMERATOR',
numerator_sum_squares_column='NUMERATOR',
denominator_column='DENOMINATOR',
categorical_group_columns=['VARIATION_TYPE','EXP_n_EVENT'],
#ordinal_group_column = ,
interval_size=0.95,
correction_method='bonferroni',
#metric_column = 'CONVERSION_EVENT_NAME',
#treatment_column ,
# power - 0.8 (default)
)
ztest_concat.summary()
ztest_concat.difference(level_1="control", level_2="variation_1", groupby="EXP_n_EVENT", absolute=False)
ztest_concat.multiple_difference(level='control', groupby='EXP_n_EVENT', level_as_reference=True)
- **For all experiments using the above table as it is. (Experiment_Key, Variation_Type, Country, Conversion_Event_Name)
The summary class works even if I change the conversion_event from the categorical group to metric_column. While the methods difference () and multiple_difference() return errors regardless of the combinations, I can try in both the class and the method.
Trial 1: metric_column equals conversion_event_name
ztest = confidence.ZTest(pandasDF_updated,
numerator_column='NUMERATOR',
numerator_sum_squares_column='NUMERATOR',
denominator_column='DENOMINATOR',
categorical_group_columns=['VARIATION_TYPE','EXPERIMENT_KEY'],
#ordinal_group_column = ,
interval_size=0.95,
correction_method='bonferroni',
metric_column = 'CONVERSION_EVENT_NAME',
#treatment_column ,
# power - 0.8 (default)
)
######################################################################
Trial 2 : metric_column hidden and conversion_event_name moved to categorical_group_columns
ztest = confidence.ZTest(pandasDF_updated,
numerator_column='NUMERATOR',
numerator_sum_squares_column='NUMERATOR',
denominator_column='DENOMINATOR',
categorical_group_columns=['VARIATION_TYPE','EXPERIMENT_KEY','CONVERSION_EVENT_NAME'],
#ordinal_group_column = ,
interval_size=0.95,
correction_method='bonferroni',
#metric_column = 'CONVERSION_EVENT_NAME',
#treatment_column ,
# power - 0.8 (default)
)
ztest.multiple_difference(level='control', groupby=['EXPERIMENT_KEY','CONVERSION_EVENT_NAME'], level_as_reference=True)
ValueError: cannot handle a non-unique multi-index! (for both trials)
I've been searching inside the repository notebooks, but I couldn't find the place that explains or execute this error message.
So after this test, I wondered:
- Is there any configuration between the class and the method that meets our needs?
- what is the use case for the variable "metric_column "?
- at which level the "correction_method='bonferroni' " is applied?
Thanks, and looking forward to leveraging this package.
Hi!
Sorry for the slow response.
- If you're using the dataframe above, you would need to add "Country" to
categorical_group_columnsand to thegroupbyargument of multiple difference. If you don't want to split by country you would need to sum up you df first, something likedf.groupby(['VARIATION_TYPE','EXPERIMENT_KEY','CONVERSION_EVENT_NAME']).sum().reset_index()might do. - We use it for some multiple correction variants e.g. "spot-1-bonferroni", where we only Bonferroni correct for "success metrics", not for "guardrail metrics". For normal Bonferroni correction it doens't matter if you put 'CONVERSION_EVENT_NAME' as
metric_columnor incategorical_group_columns. - It's applied to the total number of comparisons, so if you have 3 experiments, 5 metrics and control + 2 treatment groups in each you would get 352=30 comparisons in total.
Hope that helps!