Large number of files slows down the checking process.
I have read and attempted to steep check a large number of RBS files, over 10000. I found that there is a big difference in execution time compared to when all the contents are in one file. I think this is an incentive to put the RBS files in one file instead of separating them, so the difference in execution time between the two should be smaller.
gen.rb
#! /usr/bin/env ruby
require 'pathname'
split = Pathname.new('split')
split.rmtree rescue nil
split.mkdir
n = ARGV[0].to_i
(n - 1).times.map { |i| "C#{i}" }.each do |c|
split.join("#{c}.rbs").write(<<~RBS)
class #{c}s
end
RBS
end
How to generate RBS files.
$ ruby gen.rb 2000
How to concat RBS files.
$ cat split/* > concat/concat.rbs
How to measure time.
$ time bundle exec steep check
Measurements were taken by switching directories.
$ cat Steepfile
target :sample do
check "sample.rb"
signature "split" # or "concat"
end
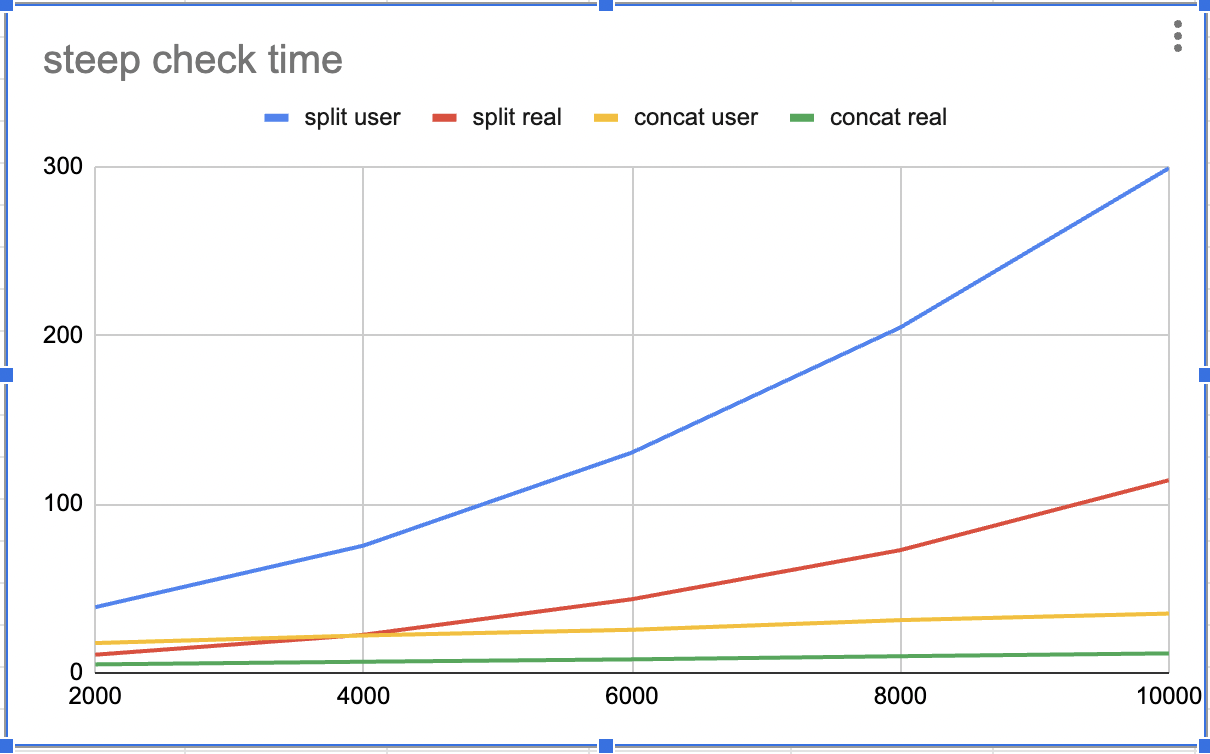
8 cpu execution time.
| file count | split user | split real | concat user | concat real |
|---|---|---|---|---|
| 2000 | 38.92 | 10.774 | 17.67 | 5.04 |
| 4000 | 75.43 | 22.585 | 22.19 | 6.612 |
| 6000 | 130.57 | 43.663 | 25.55 | 8.019 |
| 8000 | 204.71 | 72.76 | 31.27 | 9.888 |
| 10000 | 299.07 | 114.17 | 35.15 | 11.57 |
Nice found...
The reason would be because Steep distributes the RBS validation tasks to worker processes by file. If we have 10,000 files and 10 workers, each worker has 100 validation tasks to execute. If we have 10 files and 10 workers, each worker has 1 validation task to execute. I guess this causes the difference, but not confirmed yet.
Looking at the $ htop, it appeared that there were times when tasks were concentrated on only one cpu.
I have not been able to find out which task it is...