kospeech
 kospeech copied to clipboard
kospeech copied to clipboard
Transformer 모델 학습시 y_hat이 float로 출력
좋은 소스를 공유해주셔서 감사합니다!
Speech transformer 모델로 학습시
supervised_trainer.py
while True:
inputs, targets, input_lengths, target_lengths = queue.get()
if inputs.shape[0] == 0:
break
inputs = inputs.to(self.device)
targets = targets[:, 1:].to(self.device)
model.to(self.device)
if isinstance(model, nn.DataParallel):
y_hats = model.module.recognize(inputs, input_lengths)
else:
y_hats = model.recognize(inputs, input_lengths)
for idx in range(targets.size(0)):
target_list.append(self.vocab.label_to_string(targets[idx]))
predict_list.append(self.vocab.label_to_string(y_hats[idx].detach().cpu().numpy()))
y_hats이 float 형식의 tensor로 출력되어 이후 vocab_label_to_string에서 label을 못찾아 학습도중 에러가 발생합니다. 해결방법이 있을까요?
안녕하세요. 에러 코드랑 같이 기록해주시겠어요?
그리고 해당 레포는 현재 개발은 중단된 상태이고 추가적인 개발은 https://github.com/openspeech-team/openspeech 에서 이루어지고 있습니다. 현재 레포에서 가지고 있는 많은 에러들을 보완하고, 모델, 언어도 추가된 형태로 릴리즈 되었습니다.
해당 레포를 참고해주시는게 더 좋을 것 같습니다.
답변주셔서 감사합니다!
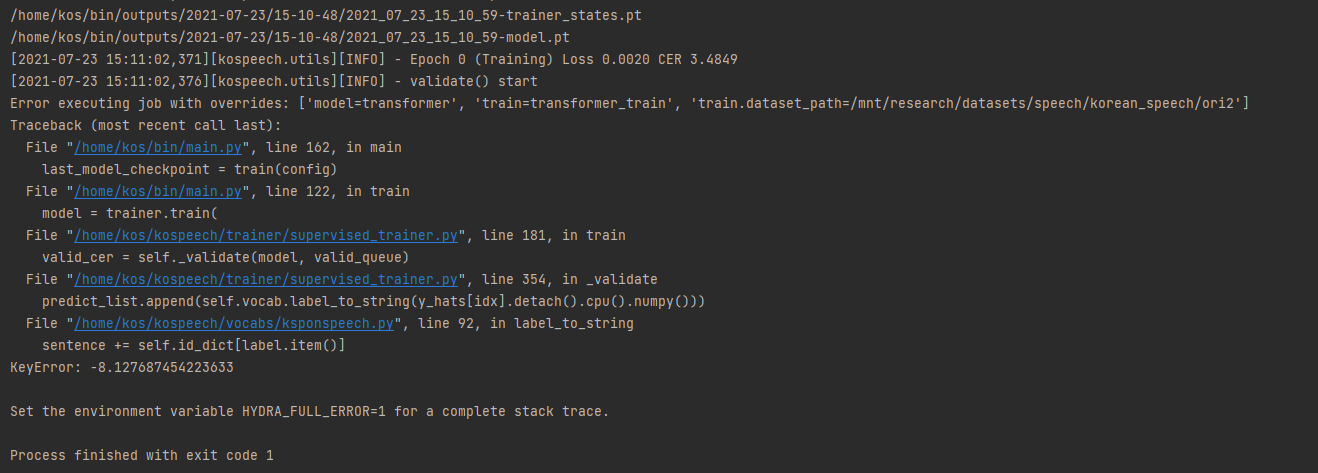
1 에폭 돌면 저 에러가 발생하는 상황입니다.
디버깅 결과 label -> float 로 저장되어 items()를 못 받는것 같습니다.
네. 전처리 파일 돌리는 코드가 제공되고 있습니다. README 읽어보시면 됩니다.
보통 저희 답장이 느려서 직접 돌리시는게 낫습니다.
약간의 차이점이 있어서 openspeech 기준으로 하시는걸 추천드려요.
KsponSpeech의 evaluation 셋이 따로 있습니다. 따로 지정해주시면 됩니다.