Write ADR for processing / merging
We need to document our processing and merging strategy. Our way is to implement a chained approach, where we succeedingly enhance the final data model with more data from sources.
We define an order of mergers collating the data from each of the sources sequentially. The harvesters can run in parallel. This enables us to benefit from prior knowledge of former processed sources, enabling a ranking by starting with high value sources (CFF, CodeMeta, ...) to lower quality and coarse ones like Git, APIs, etc.
The idea is to use a general merger that has selectable generalized merging strategies. This general merger is fed with data from sources that might have been mangled by a preprocessor (which already builds on former knowledge from sources merged before).
Other approach on the right: push all data into one giant model and cleanup collisions, duplicates etc.
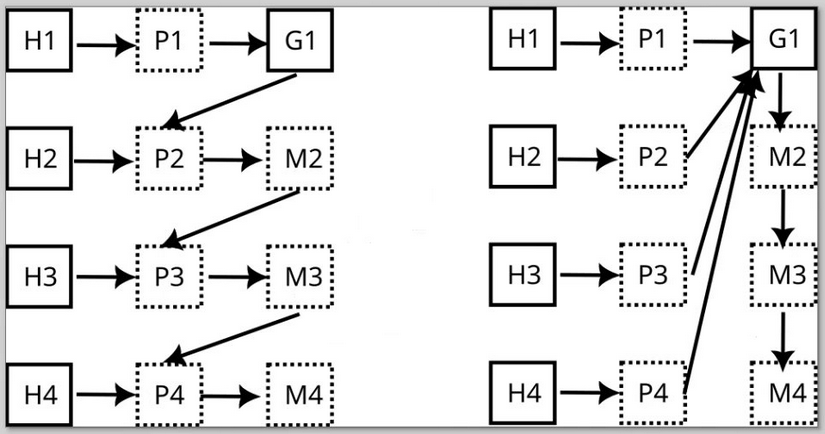
This could also be combined: the general merger might implement such a cleanup and run last in order.
Just to commit one concert to the proceedings: Giving preprocessors (P) access to partially merged results allows dependencies between different preprocessors (or harvester (H)+preprocessor pairs) to emerge which can encumber reuseablilty.
@jkelling Yes, that could happen. However, I don't see a big problem with allowing this, yet we should discourage it in the documentation. And we should definately not include such processors in the core.
In addition, it's not a big deal to allow a combination of both paths... especially as (in the left image) G1 = M2 = M3 = M4 as of the current implementation strategy.
After reviewing #107, it became even more obvious that a "cleanup" entrypoint as a last substep in process is a good idea, e.g. to mangle the author/contributors fields to a users liking.
Had a chat with @led02 about this, based on a potential fix for #67. Here's what we came up with:
Currently, we have a dirty interface between harvesting and processing (and preprocessing). Also, merging in https://github.com/hermes-hmc/workflow/blob/develop/src/hermes/commands/workflow.py#L109 is destructive, i.e., values are overwritten for the same field.
A better idea would be in merging to:
- Record new values for the same field - where it makes sense, i.e., for versions where deduplication must be done by developers of merging strategies - as alternative (instead of overwriting). This may be based on rules for uniqueness (e.g., an
@idfor a Person object), under which alternatives may or may not be valid to exist. - Record alternatives in the tag for, e.g., the first encountered (or a rule-based other) alternative, e.g.,
hasAlternativewhich takes an array of alternatives, i.e. paths (or tag ids?). - Now that we have an enriched model, the actual processing (and we need to move all current (pre-)processing that is actually merging out of there) can take care of evaluation and picking from the alternatives based on metadata point, not harvesting source.
Aim:
- "preprocessing hack" is gone
- The workflow is harvest - merge - process - ...
- Harvesting works along data sources
- Processing works along metadata points or metadata types (e.g., Person, URL)