snabb
 snabb copied to clipboard
snabb copied to clipboard
AVX2 Delay (Just an interesting piece of info)
May be worth looking at/thinking about perf wise.
https://software.intel.com/en-us/forums/intel-isa-extensions/topic/710248
Some processors (definitely Xeon E5 v3, but perhaps others) incur a delay of about 10 microseconds (about 30,000 cycles) shortly after any core begins using 256-bit registers (if it has not used 256-bit registers in the last millisecond). (This appears to be a delay required to "turn on" the upper 128-bits of the vector pipelines -- similar to a frequency change, but occurring even if the frequency does not change, so it is probably a delay due to a voltage change.) This stall only occurs when using 256-bit registers -- AVX/AVX2 encodings of scalar and 128-bit register operations do not generate this delay.
If your functions are short (e.g., 3000 cycles), then this overhead would be 10x.
If the time between calls to functions using 256-bit registers is close to 1 millisecond, the stall becomes more random -- sometimes your code will execute just before the upper 128-bit pipeline is turned off and sometimes it will execute just after the upper 128-bit pipeline is turned off.
The only way to avoid this stall is to either (1) never use 256-bit registers, or (2) make sure that the code never goes a full millisecond without using 256-bit registers.
My benchmark codes now include a "warm-up" function that uses 256-bit registers and runs for approximately 2 milliseconds immediately before the initial timer read for any code that I want to test that uses 256-bit registers. This does not eliminate the stall, but it ensures that it happens before my timed region.
The stall seems long, but since it can only happen once per millisecond, it can't eat up more than about 1% of the overall cycles
.
Thanks for the link. I have seen some suspicious spikes in timeline logs in the past and it's possible that they are related to these voltage switches. I will have to check on this when I swing back around there.
I know that some people in the world are strictly sticking with 128-bit SIMD registers for performance reasons and it will be interesting to dig deeper into what suits the Snabb use cases best.
It would be interesting to know if there is any CPU performance counter register counting these voltage switches. There certainly should be.
A newer update on this phenomenon: https://blog.cloudflare.com/on-the-dangers-of-intels-frequency-scaling/
regarding avx512, it could be only a subset of features; https://github.com/openssl/openssl/commit/79337628702dc5ff5570f02d6b92eeb02a310e18
Here's some more docs on how haswell and broadwell behave: https://en.wikichip.org/wiki/intel/frequency_behavior#Base.2C_Non-AVX_Turbo.2C_and_AVX_Turbo
I guess I am mixing the two things: the frequency throttling, and the transition latency. All Xeon chips since E5 v3 I think have different base frequencies when executing AVX2 versus not. For Skylake and later, this is a per-core thing and depends on which kinds of AVX you're talking about; before (e.g. E5 v3 Haswell) it's much more coarse and per-socket (i.e., one core runs AVX2, all cores on die capped at the "AVX2 turbo max", which if you have turbo boost off as we usually do, is the "AVX2 base frequency", commonly 25% slower than marked frequency; e.g. on E5-2620v3 it is 2.1 Ghz vs 2.6 Ghz nominal).
As far as transition latency goes, it is hard to find numbers. Fabian Giesen describes his experience here: https://gist.github.com/rygorous/32bc3ea8301dba09358fd2c64e02d774. For us probably given that we process a new batch of packets every 100 us, if we use AVX2, we never really transition out of it. Even then, I think the original comment on the intel forum is wrong: there's not a complete delay; 256-bit instructions are still retired, only they're shunted through the 128-bit unit and there's a lot of overhead in that transition period.
Stepping back: I think most Snabb apps are not computationally limited by the kinds of instructions that AVX2 could speed up. Consider the following test case, run on our E5-2620 v3 (Haswell-EP):
[wingo@snabb1:~/snabb/src]$ sudo taskset -c 3 ./snabb snabbmark hash
[pmu /sys/devices/cpu/rdpmc: 1 -> 2]
baseline: 9.08 cycles, 3.11 ns per iteration (result: 0)
murmur hash (32 bit): 27.02 cycles, 8.45 ns per iteration (result: 593689054)
sip hash c=1,d=2 (x1): 28.04 cycles, 8.76 ns per iteration (result: 1740456520)
sip hash c=1,d=2 (x2): 21.99 cycles, 6.87 ns per iteration (result: 764162108)
sip hash c=1,d=2 (x4): 13.26 cycles, 4.14 ns per iteration (result: 3982310842)
sip hash c=1,d=2 (x8): 12.56 cycles, 3.93 ns per iteration (result: 2201963874)
sip hash c=2,d=4 (x1): 43.24 cycles, 13.52 ns per iteration (result: 3246680284)
sip hash c=2,d=4 (x2): 39.92 cycles, 12.48 ns per iteration (result: 3394909516)
sip hash c=2,d=4 (x4): 22.09 cycles, 6.91 ns per iteration (result: 1928778572)
sip hash c=2,d=4 (x8): 21.33 cycles, 6.67 ns per iteration (result: 2241889326)
Here, the x1 variants use normal scalar x86-64 assembly; the x2 variants use SSE and 128-bit registers; and the x4 and x8 variants use AVX2 and 256-bit registers.
I see the results and I think well of course, the AVX2 variants are best, great. But how much is a network function limited by hashing?? If this is the only AVX2 in a program, probably very little. If processing a packet takes 200 non-AVX cycles, then that's 77ns at 2.6 Ghz (nominal clock rate), but 95ns at 2.1 Ghz (AVX base clock rate). The difference of almost 20ns for the packet probably isn't made up by increased efficiency of AVX2.
So, we should consider not using 256-bit registers in Snabb. It could be a decent solution to just use SSE4 or at least the 128-bit subset of AVX2, to avoid the frequency limitations.
Althernately, as "light" AVX2 instructions seem to run at full rate on Skylake and later, perhaps we limit them to that processor family -- i.e. disable on Haswell.
Documentation for turbo bins on Xeon E5 servers: https://www.intel.com/content/dam/www/public/us/en/documents/specification-updates/xeon-e5-v3-spec-update.pdf
For the machines in Igalia's lab (2x E5-2620 v3), some excerpts from those charts here:
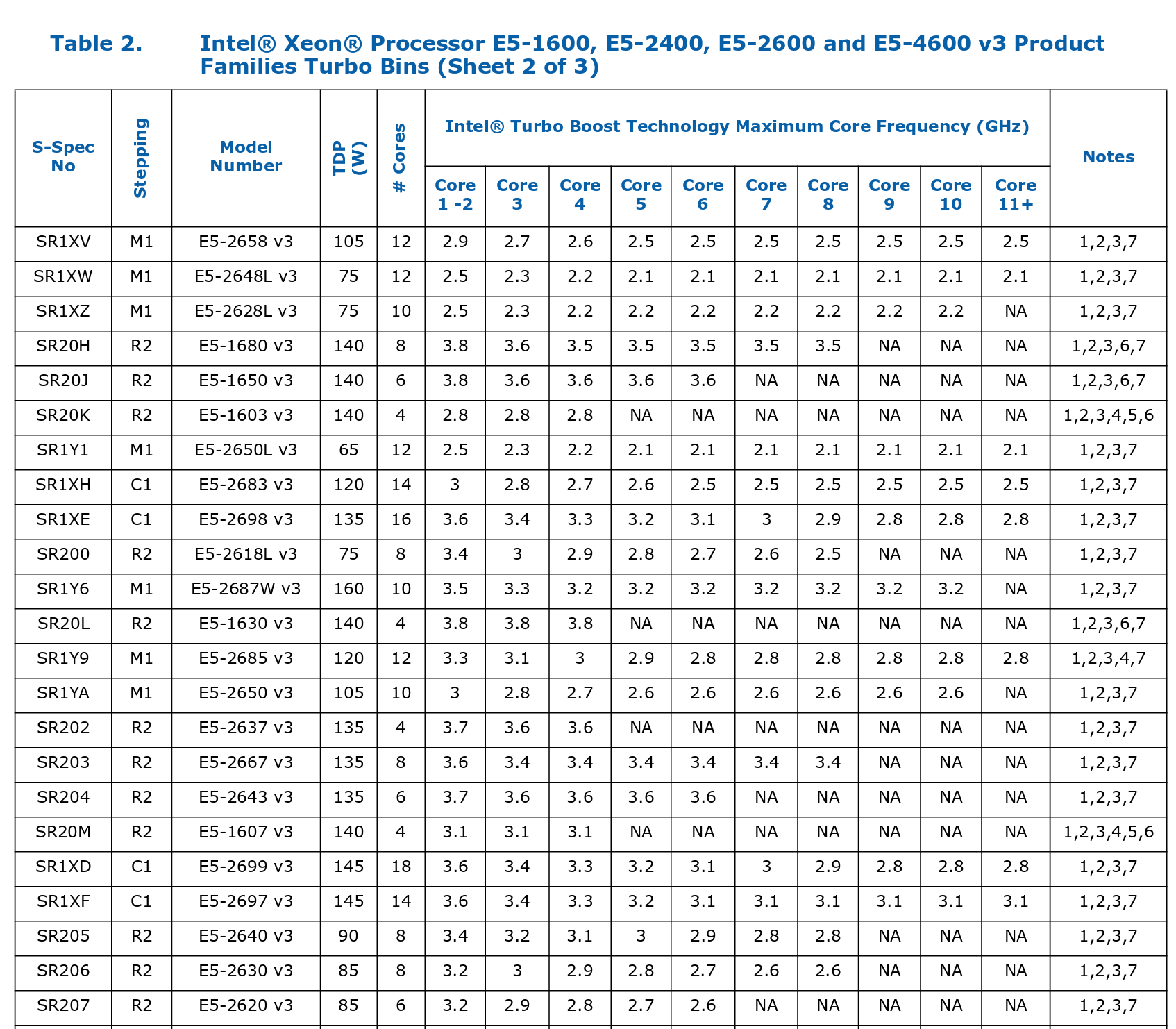
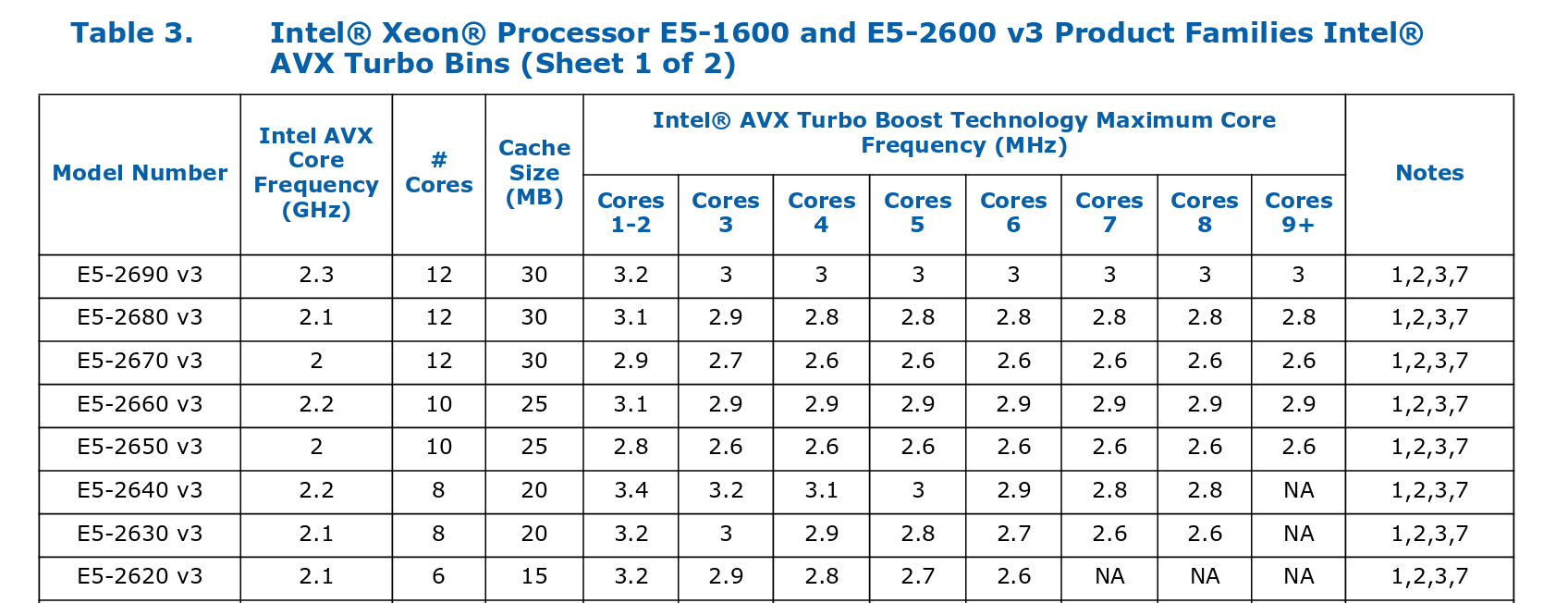
Interestingly for this SKU, the AVX2 turbo bins are the same as the non-AVX turbo bins. I don't think that's generally the case, though the charts don't make it easy to compare.
For me I have two questions:
(1) Should we recommend that turbo boost be enabled? In what circumstances?
(2) Should we back off from YMM (256-bit) register use in Snabb for the moment? Does this decision depend on whether turbo boost is enabled or not on our targets, whether all cores or just one are in use, whether we're talking about production or a benchmarking machine, and what specific part we're talking about?
Regarding turbo boost -- I think that if you want the highest possible performance, you should enable it. If only one core is active, your perf boost could be up to 33% (3.2 Ghz vs 2.4 Ghz on the E5-2620v3). If multiple cores are active, say half your cores, then the boost is more modest: 2.9 Ghz on the E5-2620v3, or 20%. If all cores are active, the boost is minimal, somewhere around 5-10%.
However -- if you
- cannot tolerate temperature or load-related downward changes in frequency
- need to do benchmarking to help determine whether a software change is good or not and you don't want results to depend on temperature or how many other cores are active
Then you need to disable turbo boost.
Now, how does this relate to AVX2?
The thing is, with turbo boost off, using AVX2 will downclock the CPU to the AVX2 "base frequency". On Skylake and later, this is per-core, but on Haswell-EP and Broadwell-EP (Xeon E5 v3 and v4, respectively) it's per-socket apparently. For the E5-2620 v3 it's 12.5% lower (2.1 Ghz vs 2.4 Ghz). Although 256-bit code can do more per cycle, unless the performance is limited by the AVX2 code, the result will be that all the non-AVX2 code runs slower, so your code gets slower. Using AVX2 on a machine with turbo boost off is a lose.
However! With turbo boost on, the CPU may "turbo" up to the corresponding AVX2 turbo bin, which in the case of the E5-2620v3 match the non-AVX2 speeds. So in that case, as long as you run AVX2 often enough to avoid the warmup delay, then using AVX2 may indeed improve performance!!!
I have some measurements showing me thing but I need to collect some more with turbo boost disabled. Will report back with details.
Incidentally here's a better link on how to understand haswell turbo bins: https://www.microway.com/knowledge-center-articles/detailed-specifications-intel-xeon-e5-2600v3-haswell-ep-processors/
From that page, all-core frequency ranges:
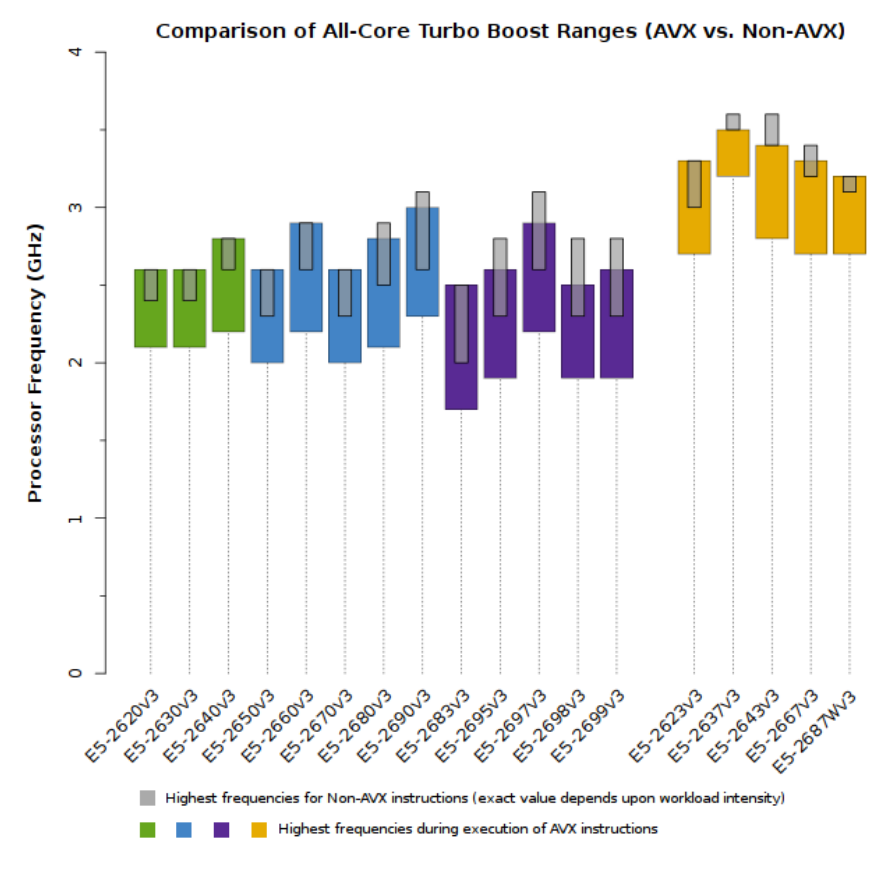
Frequency ranges with a single core active:
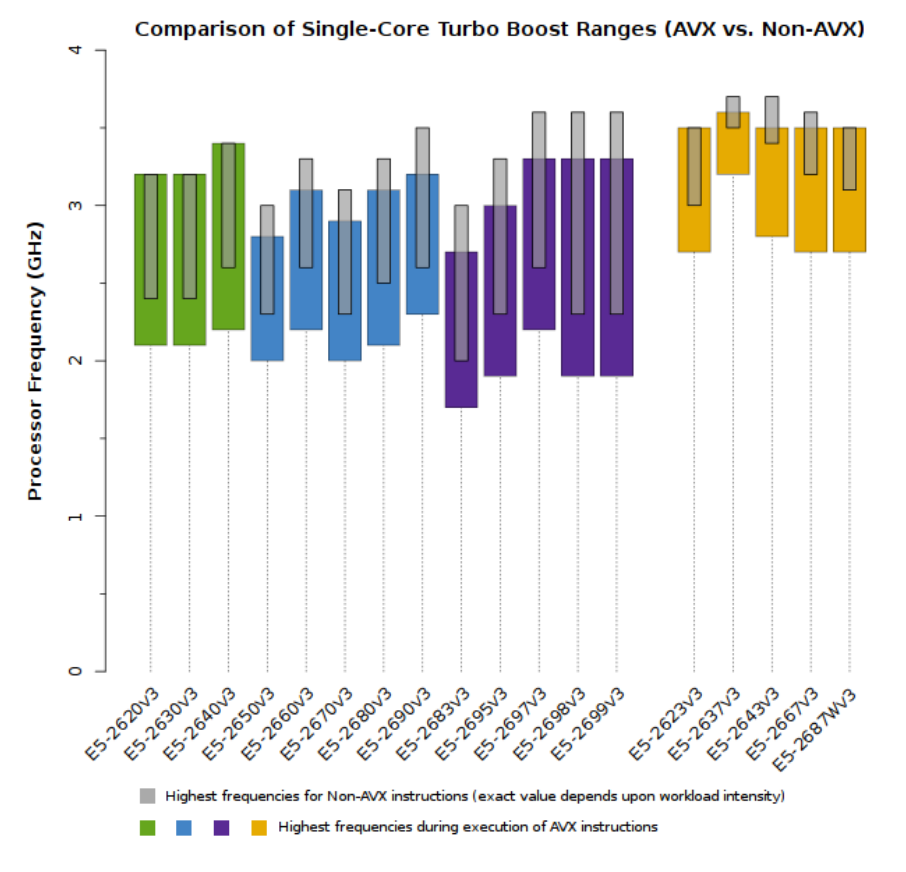
Comparison for skylake: https://www.microway.com/knowledge-center-articles/detailed-specifications-of-the-skylake-sp-intel-xeon-processor-scalable-family-cpus/
An HPC-flavor review of Skylake, Broadwell, and Haswell, with attention to turbo boost: https://indico.cern.ch/event/668301/contributions/2732540/attachments/1572581/2485483/TurboBoostUpAVXClockDownPrelim.pdf
In an absolutely bonkers perplexing result -- I don't see any downclocking when running AVX2 without turbo boost on our servers. Measured by looking at /proc/cpuinfo. Granted, only one core was active when I was running these tests.
The Snabb lwAFTR uses AVX2 in three places:
- Validation of checksums on incoming IPv4 packets.
- SipHash to find binding table entry for incoming packets, and to detect hairpinning.
- Parallel streaming copy of multiple hash table entries as once. (AVX2 lets us load more per cycle.)
I tested the lwAFTR using the snabb loadtest find-limit tool, which does a bisection on applied load from 0 Gbps to 10 Gbps, to determine the highest load at which no packets are dropped. The lwAFTR was run like this, on our E5-2620v3:
sudo ./snabb lwaftr run --cpu 11 --name lwaftr --ingress-drop-monitor=warn --conf program/lwaftr/tests/data/icmp_on_fail.conf --on-a-stick 82:00.1
This test configuration has only a handful of binding table entries, so it doesn't test cache footprint of the binding table. The load generator was run like this:
for i in `seq 5`; do sudo ./snabb loadtest find-limit -D 1 --cpu=3 program/lwaftr/tests/benchdata/ipv4-0094.pcap NIC NIC 02:00.1 | tail -1; done
This does 5 bisections. At each point, load is applied for one second. If no packets are dropped, then that's a pass, bisection continues at a higher load level. If packets are dropped, the load-tester retries three times, then fails, continuing the bisection at a lower load level. The tail -1 makes it so that we get 5 final results.
This test load is a single packet, repeated millions of times. It means that all packets are going to take the same branches, on the lwaftr side. It's not a great test in that sense, but it does do all the computation for each packet, so I think it's a fine test for AVX2 vs not AVX2.
To test without AVX2, I manually short-cutted the tests in the checksum and siphash modules that could take advantage of AVX2. For multi_copy.dasl, I rewrote it in SSE2.
Results:

Summary:
W T F
The different bars represent different invocations of lwaftr run. I did 5 loadtests for each invocation, hence the little histogram on each bar. The loadtest results within an invocation are fairly constant, but there's some inter-invocation variance.
Conclusion is that disabling AVX2 code slows down the system. I think this is because on this system, we aren't actually penalized back to the AVX2 base clock rate. I suspect that's because this is a memory-limited benchmark, so we're not really burning the CPU. But it invalidates the whole theoretical analysis above, which makes me mad!!!!!!!!!!!!!
